锁
编写代码时,我们以及习惯了用锁去保护数据。那么,这里的锁是什么?为什么它能满足我们的要求?它存在于哪里?
让我们从一个最简单的例子出发—多个线程并发修改一个全局变量:
/* 全局变量 */
int g_sum = 0;
/* 每个线程入口 */
void *thread(void* arg)
{
for(int i = 0; i < 100; i++)
{
g_sum++;
}
return NULL;
}在多核处理器上,如果有两个线程同时执行上面的累加操作,最终的g_sum几乎不可能是预期的200(每个线程累加100次),而更倾向于是一个接近200的随机值。
这是因为CPU对g_sum进行累加时,它们都会:1.从内存中读取 2.修改它的值 3.将新值写回内存。由于CPU之间是独立的,而内存是共享的,所以就有可能存在一种时序:两个CPU先后从内存中读取了g_sum的值,并各自对它进行了递增,最终将新的值写入g_sum,这时。两个线程的两次累加最终只让g_sum增加了1
临界区
要解决上面的问题,一个很自然的想法同一时间段内,要想办法只让一个线程对全局变量进行读-修改-写。我们可以用锁去保护临界区
这里引入了临界区的概念。临界区是指访问共用资源的程序片段(比如上面的例子中的”g_sum++”)。线程在进入临界区时加锁,退出临界区时解锁。也就是说,锁将临界区”保护”了起来。
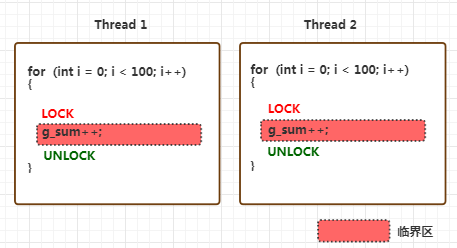
临界区是人们为一段代码片段强加上的概念,但加锁和解锁不一样,它必须实打实地存在于代码中。那么问题来了,锁应该如何实现 ?
为了回答这个问题,我们先将锁需要具有的特性列出来:
1. 它需要支持加锁(lock)和解锁(unlock)两种操作。2. 它需要是有状态(State)的,它需要记录当前这把锁处于Locked还是Unlocked状态。3. 锁的状态变化必须是原子(Atomic)的4. 当它处于Locked状态时,对其进行加锁(lock)的操作,不会成功。
第1条,对实现者来说,一是要提供两个API分别对应这两种操作。
第2条,需要一个地方能记录锁的状态,对计算机系统来说,这个地方只能是内存。
第3条,将锁的状态记录在内存中有个和全局变量一样的问题,那就是如何避免多个线程同时去改变锁的状态 ? 总不能用锁去保护锁吧 ? 好在各个体系的CPU都提供了这种原子操作的原语, 对x86来说,就是指令的LOCK前缀, 它可以在执行指令时控制住总线,直到指令执行完成。这也就保证了锁的状态修改是通过原子操作完成的。
第4条,加锁操作成功的前提是锁的状态是处于”Unlocked”,如果该条件不满足,则本次加锁操作失败,那么失败以后的行为呢?不同的锁有不同的实现,一般来说有三种可选择的行为:1.立即返回失败 2.不断尝试再加锁,直到成功. 3. 睡眠线程自己,直到可以获得锁。
典型实现
当然,我们并不需要去重复造锁的轮子。
在用户空间,glibc提供了诸如spinlock、semaphore、rwlock、mutex类型的锁的实现,我们只要使用API就行。
int sem_wait(sem_t *sem);
int sem_post(sem_t *sem);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
.......在内核空间,Linux也有类似的实现.
性能损失
在刚才的例子中,如果我们使用了锁去保护g_sum,那么最终一定能得到200。但是,我们在得到准确结果的同时也会付出性能的代价。
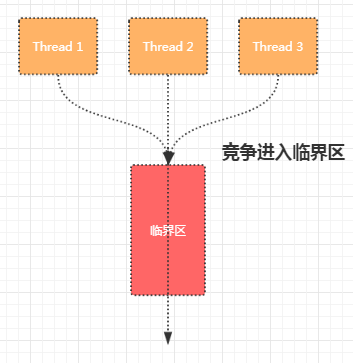
如果把临界区比作成一个独木桥,那么线程就是需要过独木桥的人。 显然,如果过桥的人(并发访问临界区的线程)越多,独木桥越长(锁保护的临界区的范围越大),那么其他人等地就越久(性能就下降地越厉害)。
下面这是在一台8核CPU虚拟机环境下,测试程序的运行结果。
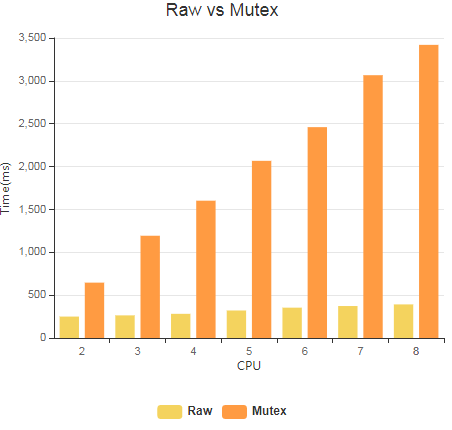
横坐标是并发运行的线程的数目,纵坐标是完成相同任务(累加一定次数)时的运行时间。越多的线程会带来越多的冲突,因此,总的运行时间会逐渐增大。
如果增加临界区的长度呢(在每次循环中增加一些额外指令),则会得到下面的结果:
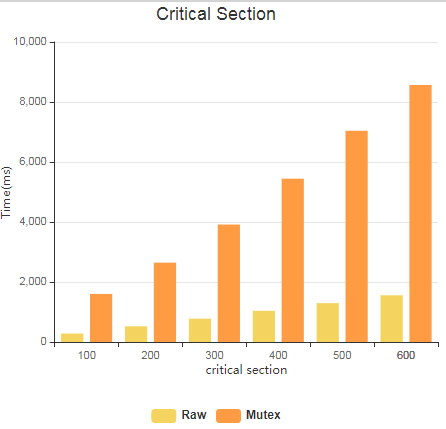
横坐标表示额外的指令,纵坐标依然表示时间。
可见,线程的并发越多、临界区越大都会造成程序性能下降。这也是为什么追求性能的程序会选择使用每cpu变量(或者每线程变量),并且尽量减小锁保护的粒度。
Futex
前面说过,锁是有状态的,并且这个状态需要保存在内存中。那么?具体到Linux平台,锁对象是保存在内核空间还是用户空间呢? 在比较早的内核(2.5.7)中,这个对象是保存在内核中的,这是很自然的做法。因为当一个线程(task)去等待获得一个互斥锁时,如果获取不到,那么它需要将积极睡眠,直到锁可用后再被唤醒。
这个过程具体来说,就是将自己的task_struct挂到锁对象的等待链表上。当锁的持有者unlock时,内核就可以从该等待列表上找到并唤醒链表上所有task。
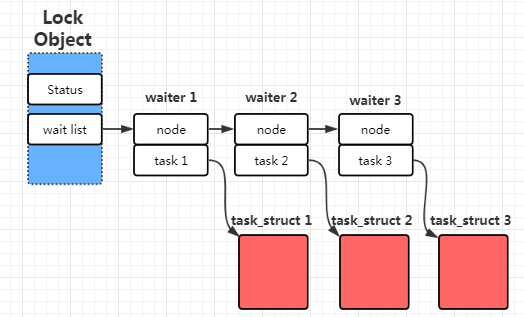
可见,每次用户的加锁解锁操作都必须陷入内核(即使现在没有其他线程持有这把锁)。陷入内核意味着几百个时钟就消耗了。在冲突不大的场景中,这种消耗就白白浪费了。
因此,从2.5.7版本开始,Linux引入了Futex(Fast Userspace muTEXes),即快速的用户态互斥机制,这个机制是用户态和内核态共同协作完成的,它将保存锁状态的对象放在用户态。如果用户在加锁时发现锁处于(Unlocked)状态,那么就直接修改状态就好了(fast path),不需要陷入内核。当然,如果此时锁处于(Locked)状态,还是需要陷入内核(slow path)。
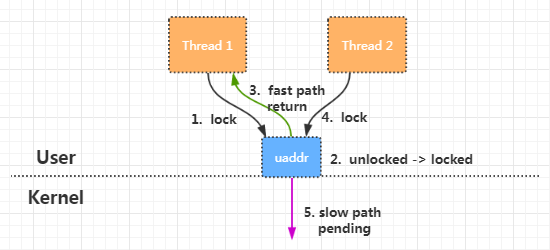
那么我们如何使用Futex机制呢?答案是我们完全不需要显示地使用,glibc库中的semaphore、mutex底层就是使用的Futex。
无锁
锁是通过一个状态的原子操作来保证共享数据的访问互斥。而无锁的意思就是不需要这样一个状态。
CAS
说到无锁,必须提到的就是CAS指令(也可以叫CSW)。CAS是CompareAndSwap的缩写,即比较-交换。不同体系的CPU有不同的CAS的指令实现。在x86上,就是带LOCK前缀的CMPXCHG指令。所以,CAS操作是原子的
它的功能用伪代码描述就是下面这样(仅为理解,实际是一条原子指令):
bool compare_and_swap(int *src, int *dest, int newval)
{
if (*src == *dest) {
*src = newval;
return true;
} else {
return false;
}
}第一个操作数的内容与第二个操作数的内容相比较, 如果相同,则将第三个操作数赋值给第一个操作数,返回TRUE, 否则返回FALSE。
较新版本的gcc已经内置了CAS操作的API(如下)。其他编译器也提供了类似的API,不过这不是本文的重点。
bool __sync_bool_comware_and_swap(type *ptr, type oldval, type newval);基于链表的无锁队列
无锁通常构建无锁队列(Lock-Free Queue)。顾名思义,无锁队列就是指不使用锁结构来控制多线程并发互斥的队列。
我们知道,队列是一个典型的先入先出(FIFO)的数据结构,具有入队(Enqueue)和出队(Dequeue)两种操作。并发条件下,多个线程可能在入队或出队时会产生竞争。
以单向链表为基础实现的队列如下图所示(有一个Dummy链表头),线程1和线程2都希望自己能完成入队操作
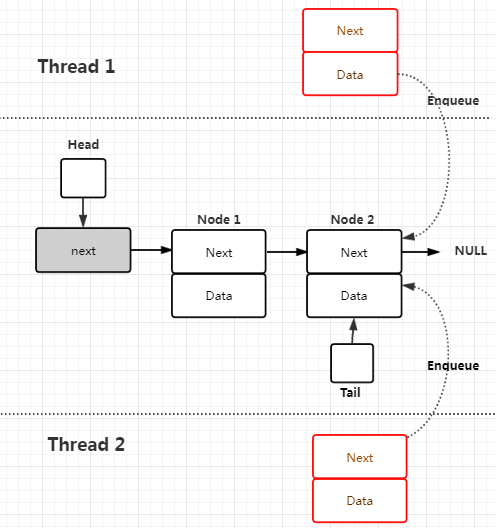
通常来说,入队要完成两件事:
如果可以使用锁,我们可以通过将以上两件事放到一个锁的保护范围内就能完成线程的互斥,那么对于无锁呢?
John D.Valois 在《Implemeting Lock-Free Queues》中提出的无锁队列的入队列算法如下(伪代码):
EnQueue(x)
{
/* 创建新的节点 n */
n = new node();
n->value = x;
n->next = NULL;
do {
t = tail; // 取得尾节点
succ = CAS(t->next, NULL, n) // 尝试更新尾节点的Next指向新的节点
if succ != TRUE
CAS(tail, t, t->next) // 更新失败,尝试将tail向后走
}while(succ != TRUE);
CAS(tail, t, n); // 更新队列的Tail指针,使它指向新的节点
}这里的Enqueue算法中使用了三次CAS操作。
1. 第一次CAS操作更新尾节点的Next指向新的节点。如果在单线程环境中,这个操作必定成功。但在多线程环境,如果有多个线程都在进行Enqueue操作,那么在线程T1取得尾节点后,线程T2可能已经完成了新节点的入队,此时T1的CAS操作就会失败,因为此时t->Next已经不为NULL了,而变成了T2新插入的节点。

再强调一遍,CAS操作会锁住总线!因此T1和T2只有一个线程会成功,成功的线程会更新尾节点的Next,另一个线程会因为CAS失败而重新循环。
如果CAS操作成功,链表会变成下面这样,此时的Tail指针还没有更新
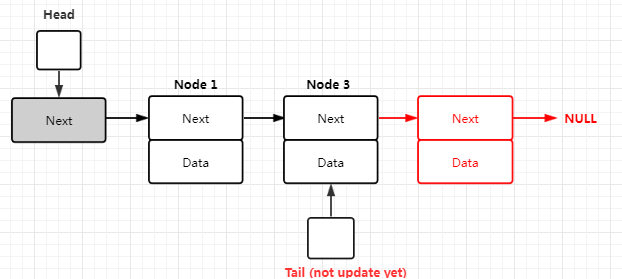
2. 如果第一个CAS失败,说明有其他线程在坏事(进行了元素入队),这个时候第二个CAS操作会尝试推进Tail指针。这样做是为了防止第一个CAS成功的线程突然挂掉而导致不更新Tail指针
3. 第三个CAS操作更新尾节点的Next
论文中还给出了另一个版本的入队算法,如下所示
EnQueue2(x)
{
/* 创建新的节点 n */
n = new node();
n->value = x;
n->next = NULL;
oldt = t = tail
do {
while(t->next != NULL) // 不断向后到达队列尾部
t = t->next
}while(CAS(t->next, NULL, n) != TRUE); // 更新尾节点的Next指向新的节点
CAS(tail, oldt, n); // 更新队列的Tail指针,使它指向新的节点
}与前一个的版本相比,新版本在循环内部增加了不断向后遍历的过程,也就是如果Tail指针后面已经有被其他线程添加了节点,本线程并不会等待Tail更新,而是直接向后遍历。
再来看出队,论文中给出的出队算法如下:
DeQueue()
{
do {
h = head;
if h->next = NULL
error queue_empty;
}while (CAS(head, h, h->next)!= TRUE)
return h->next->value;
}需要特别注意,该出队算法不是返回队首的元素,而是返回Head->Next节点。完成出队后,移动Head指针到刚出队的元素。算法中使用了一个CAS操作来控制竞争下的Head指针更新。另外,算法中并没有描述队列元素的资源释放。
基于数组的无锁队列
以链表为基础的无锁队列有一个缺点就是内存的频繁申请和释放,在一些语言实现中,这种申请释放本身就是带锁的。包含有锁操作的行为自然称不上是无锁。因此,更通用的无锁队列是基于数组实现的。论文中描述了一种基于数组的无锁队列算法,它具有以下一些特性:
1. 数组预先分配好,也就是能容纳的元素个数优先
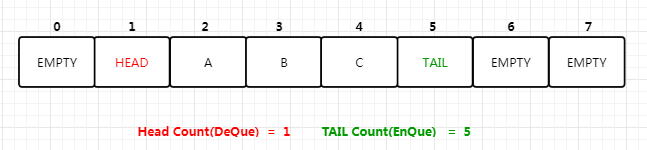
2. 使用者可以将值填入数组,除此之外,数组有三个特殊值:HEAD, TAIL和EMPTY。队列初始化时(下图),除了有两个相邻的位置是填入HEAD, TAIL之外,其他位置都是EMPTY。显然,用户数据不能再使用这三个值了。。

- 入队操作:假设用户希望将一个值
x入队,它会找到TAIL的位置,然后对该位置和之后的位置执行一次Double-Word CAS。该操作将<TAIL,EMPTY>原子地替换为<x,TAIL>。当然,如果TAIL后面不是EMPTY(而是HEAD`),就说明队列满了,入队失败。 - 出队操作:找到
HEAD的位置,同样利用Double-Word CAS,将<HEAD,x>替换为<EMPTY,HEAD>。当然如果HEAD后面是EMPTY,则出队失败(此时队列是空的)。 - 为了快速找到
HEAD和TAIL的位置,算法使用两个变量记录入队和出队发生的次数,显然这两个变量的改变都是原子递增的。
在某个时刻,队列可能是下面这个样子
我也用CAS操作实现了一个队列,但是没有用论文中的算法。而更偏向于DPDK的实现。
struct headtail{
volatile uint32_t head;
volatile uint32_t tail;
};
struct Queue{
struct headtail prod;
struct headtail cons;
int array[QUEUE_SIZE];
int capacity;
};
int CAS_EnQueue(struct Queue* queue, int val)
{
uint32_t head;
uint32_t idx;
bool succ;
do{
head = queue->prod.head;
if (queue->capacity + queue->cons.tail - head < 1)
{
/* queue is full */
return -1;
}
/* move queue->prod.head */
succ = CAS(&queue->prod.head, head, head + 1);
}while(!succ);
idx = head & queue->capacity;
/* set val */
queue->array[idx] = val;
/* wait */
while(unlikely(queue->prod.tail != head))
{
_mm_pause();
}
queue->prod.tail = head + 1;
return 0;
}
int CAS_DeQueue(struct Queue* queue, int* pval)
{
uint32_t head;
uint32_t idx;
bool succ;
do {
head = queue->cons.head;
if (queue->prod.tail - head < 1)
{
/* Queue is Empty */
return -1;
}
/* forward queue->head */
succ = CAS(&queue->cons.head, head, head + 1);
}while(!succ);
idx = head & queue->capacity;
*pval = queue->array[idx];
/* wait */
while(unlikely(queue->cons.tail != head))
{
_mm_pause();
}
/* move cons tail */
queue->cons.tail = head + 1;
return 0;
}
总结
无论是锁还是无锁,其实都是一种多线程环境下的同步方式,锁的应用更为广泛,而无锁更有一种自旋的味道在里面,在特定场景下的确能提高性能,比如DPDK中ring实际就是无锁队列的应用