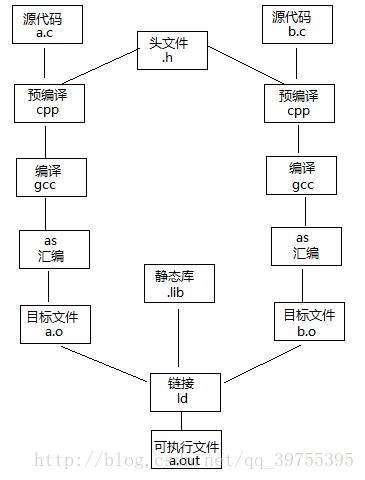
一个源程序到一个可执行程序的过程:预编译、编译、汇编、链接。
其中,编译是主要部分,其中又分为六个部分:词法分析、语法分析、语义分析、中间代码生成、目标代码生成和优化。
链接中,分为静态链接和动态链接,本文主要是静态链接。
一、预编译:主要处理源代码文件中的以“#”开头的预编译指令。处理规则见下
1.删除所有的#define,展开所有的宏定义。
2.处理所有的条件预编译指令,如“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。
3.处理“#include”预编译指令,将文件内容替换到它的位置,这个过程是递归进行的,文件中包含其他文件。
4.删除所有的注释,“//”和“/**/”。
5.保留所有的#pragma 编译器指令,编译器需要用到他们,如:#pragma once 是为了防止有文件被重复引用。
6.添加行号和文件标识,便于编译时编译器产生调试用的行号信息,和编译时产生编译错误或警告是能够显示行号。
C语言的宏替换和文件包含的工作,不归入编译器的范围,而是交给独立的预处理器。
C语言中源代码文件的文件扩展名为.c,头文件的文件扩展名为.h,经预编译之后,生成xxx.i文件。
在C++,源代码文件的扩展名是.cpp或.cxx,头文件的文件扩展名为.hpp,经预编译之后,生成xxx.ii文件。
二、编译:把预编译之后生成的xxx.i或xxx.ii文件,进行一系列词法分析、语法分析、语义分析及优化后,生成相应的汇编代码文件。
(结合程序来说明编译的几个步骤)
有C语言的源代码如下:
arr[3] = (a+4)*(3+8);
1.词法分析:利用类似于“有限状态机”的算法,将源代码程序输入到扫描机中,将其中的字符序列分割成一系列的记号。
以上的一行C语言程序,一共有16个空字符,经扫描机扫描之后,产生了16个记号。lex可以实现词法分析。见下表:

见上图:
词法分析产生的记号分类有:关键字、标识符、字面量(数字、字符串)、特殊符号(加号、等号等)
2.语法分析:语法分析器对由扫描器产生的记号,进行语法分析,产生语法树。由语法分析器输出的语法树是一种以表达式为节点的树。上述的代码就是
各种表达式的组合:赋值表达式、加法表达式、乘法表达式、数组表达式和括号表达式组成的复杂表达式。yacc可以实现语法分析,根据用户给定的规则(不同的编程语言对应不同的语法规则)对记号表进行解析。
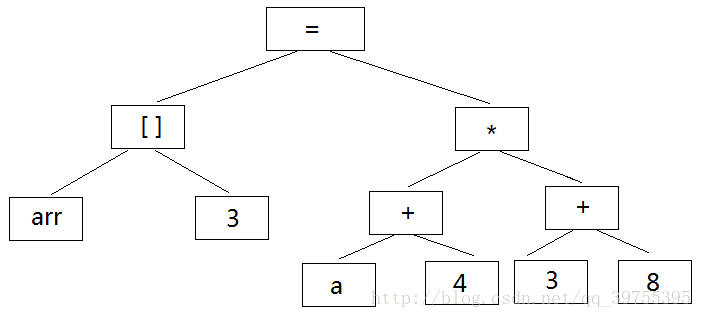
见上图:
整个语句被看作是一个“赋值表达式”,“=”左边是一个“数组表达式”,右边是一个“乘法表达式”。数组表达式又由两个符号表达式组成,符号表达式就是最小的表达式,之后同理。
在语法分析的同时,就把运算符的优先级确定了下来,如果出现表达式不合法,——各种括号不匹配、表达式中缺少操作,编译器就会报错。
3.语义分析:语法分析器只是完成了对表达式语法层面的分析,语义分析器则对表达式是否有意义进行判断,其分析的语义是静态语义——在编译期能分期的语义,相对应的动态语义是在运行期才能确定的语义。
其中,静态语义通常包括:声明和类型的匹配,类型的转换,那么语义分析就会对这些方面进行检查,例如将一个int型赋值给int*型时,语义分析程序会发现这个类型不匹配,编译器就会报错。
经过语义分析阶段之后,所有的符号都被标识了类型(如果有些类型需要做隐式转化,语义分析程序会在语法树中插入相应的转换节点),见下图:
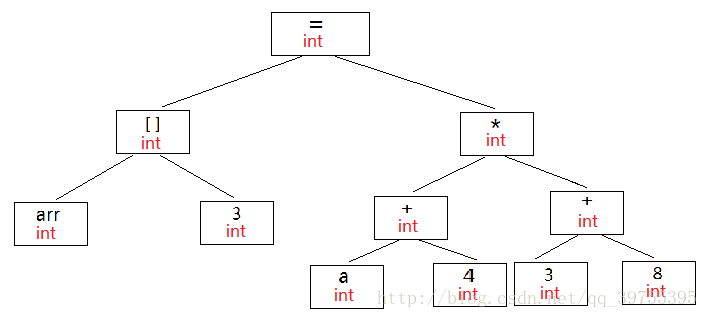
这个语句中的类型都是int型,无须做转换。
4.优化:*源代码级别的一个优化过程*,例如该语句中的(3+8)的值可以在编译期确定,源代码优化器会将整个语法树转换成中间代码——语法树的顺序表示,十分接近目标代码。
中间代码有很多种类型,最常见的是“三地址码”和“P-代码”,其中三地址码的基本形式为:x = y op z,表示将变量y和z进行op操作后,赋值给x,op操作可以是加减乘除等。
经优化之后的语法树为:
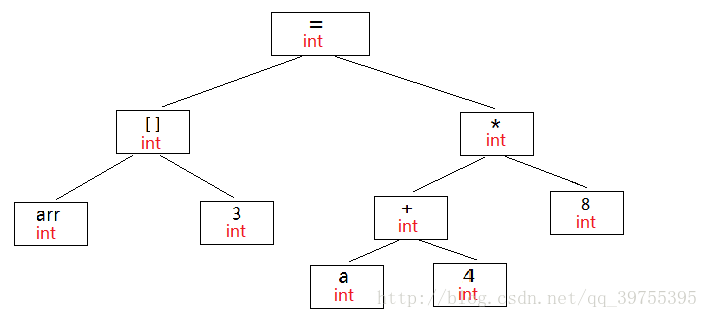
该语句的三地址码:
t1 = 3 + 8;
t2 = a + 4;
t3 = t2 * t1;
arr[3] = t3;
t1由数字11代替,省去t3,经优化或的三地址码为:
t2 = a +4;
t2 = t2 + 11;
arr[3] = t2;
另一个关于中间代码的要点:中间代码使得编译器可以被分成前端和后端,编译器前端负责产生与机器无关的中间代码,编译器后端将中间代码转换为机器代码。
源代码优化去产生中间代码标志着下面的过程都属于编译器后端,后端主要包括:代码生成器和目标代码优化器。
5.目标代码生成:由代码生成器将中间代码转换成目标机器代码,生成一系列的代码序列——汇编语言表示。
6.目标代码优化:目标代码优化器对上述的目标机器代码进行优化:寻找合适的寻址方式、使用位移来替代乘法运算、删除多余的指令等。
上述的六个步骤完毕之后,编译过程也就告一段落了。最终产生了由汇编语言编写的目标代码。
gcc把预编译和编译两个步骤合并成一个步骤。对于C语言的代码,是用“cc1”这个程序来完成这两步,对于C++代码,对应的程序为“cc1plus”。gcc这个命令只是后台程序的包装,根据不同的参数去调用:预编译编译程序——cc1,汇编器——as,连接器——ld。
C语言的代码,经编译后产生的文件名为xxx.s。
三、汇编:将汇编代码转变成机器可以执行的指令(机器码文件)。
汇编器的汇编过程相对于编译器来说更简单,没有复杂的语法,也没有语义,更不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译过来,汇编过程有汇编器as完成。
经汇编之后,产生目标文件(与可执行文件格式几乎一样)xxx.o(Windows下)、xxx.obj(Linux下)。
但是,经过预编译、编译、汇编之后,生成机器可以执行的目标文件之后,还有一个问题——变量a和数组arr的地址还没有确定。这就需要链接器来搞定啦~
四、链接:
1、历史过程:曾经,程序猿门在编程时,使用纸带作为最原始的存储设备,每当程序需要修改时,都要重新扎一条纸带,扎孔的表示1,不扎的是0,一串串1和0就组成了各种各样的指令——跳转等等….
每一次的修改都非常痛苦,所以先知们就发明了汇编语言,这种编程语言方便之处在于符号的引用,表示跳转指令不再需要记住一串串0和1,终于可以使用符号——foo来表示这个动作了!
随着汇编语言的普及,程序的代码量也就开始快速膨胀了,汇编语言说它也撑不住了….不过还好,高级编程语言Fortran、C、C++等一个接一个地问世,语言越来越方便了,追求perfect的人们就想:代码咋写更好呢?可不可以把代码按照功能的不同,分成不同的部分,便于日后的修改和重复使用呢?
有了这个启发,程序猿们越来越得心应手,他们开始把代码按照功能和性质划分,分别形成不同的功能模块,不同的模块之间又按照各种结构来组织。
发展到如今,软件的规模越来越大,代码动辄数百万行代码,放在一个模块那是万万不行的,维护起来会非常麻烦,所有现在的大型软件往往拥有成千上万的模块,
模块之间相互独立又相互依赖。
新的问题来了,一个程序被分割成这么多模块,最后要怎么把这些模块组合形成一个单一的程序?
答案就是:模块之间,符号的引用!
这就像是一张画有大树的拼图,叶子、枝干、根系都零散的分布在那些拼图碎片上,想要看到完整的大树,我们就会耐心地把那些碎片拼合在一起。
这些模块之间同样如此,它们依靠那些凸起和凹陷联系在一起,最终组合成一个完整的程序,这样的过程称为——链接。
这样基于符号的模块化,使得链接过程在整个程序开发中显得十分重要和突出…..
2、下面就静态链接,进行分析。
1.链接:“组装”模块的过程。
2.链接的内容:把各个模块之间相互引用的部分都处理好,使得各个模块之间能够正确地衔接。(就像拼图,凸起和凹槽的位置一定一一对应,否则…)
3.链接的过程:地址和空间的分配、符号决议(也叫“符号绑定”,倾向于动态链接)和重定位
以gcc编译器为例,看基本的链接过程:
.c文件经过编译器、汇编器之后得到目标文件.o,目标文件再与库进行链接得到可执行文件.out。
库其实就是一组目标文件的打包,这些目标文件中都是一些常用的代码。
我们在fun.c模块中定义了函数foo(),在main.c模块中引用了foo()函数,在编译过程当中,编译器并不知道main.c中foo()的地址,所以将调用foo()的指令的目标地址部分搁置,
等到了链接的阶段,链接器会去找到foo()定义的那个模块,在main.o中填入正确的函数地址,这个修改地址的过程被叫做“重定位”,每个被修正的地方叫“重定位入口”。
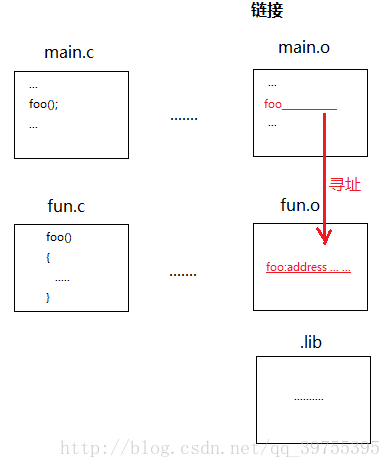
以上就是一个程序从源代码到可执行程序的大致过程,这是博主根据《程序员的自我修养——链接、装载与库》来整理的,有兴趣的同学可以自己去琢磨琢磨~