1.fock()调用的基本语义
#include<unistd.h>
pid_t fork(void);
//父进程返回子进程的pid,子进程返回0,错误返回-1fork()创建了一个心的进程(child)信进程几乎是调用进程(父进程的翻版),理解fork()的关键是,在完成对其调用之后,会产生2个进程,且每个进程都会从fork()的返回处开始执行.
这俩个进程将执行相同的程序段,但是拥有各自不同的堆段,栈段,数据段,每个子程序都可修改各自的数据段,堆段,和栈段
调用fork()之后先执行哪个进程的是由Linux下专有文件/proc/sys/kernel/sched_child_runs_first的值来确定的(值为0父进程先执行,非0子进程先执行)
2.fork()调用之后父子进程的内存关系
PS:建议读者在看这之前先看一下虚拟内存方面的知识,我的前几篇博文中就有
从具体的表现形式(读者可写段代码测试)上看,我们会认为fork()是对父进程程序段,数据段,堆段,栈段的一个赋值,我们在表象上也的确可以这么理解
早期的UNIX的fork()实现时,就是原汁原味的复制,和它的表像一样,但是很明显,这种方法效率太低,而且造成了很大的浪费,现在大部分的UNIX实现采用了如下俩种方法来规避这种浪费
(1)首先我们可以确定父子进程的代码段是相同的,所以代码段是没必要复制的,因此内核将代码段标记为只读,这样父子进程就可以安全的共享此代码段了。fork之后在进程创建代码段时,新子进程的进程级页表项都指向和父进程相同的物理页帧
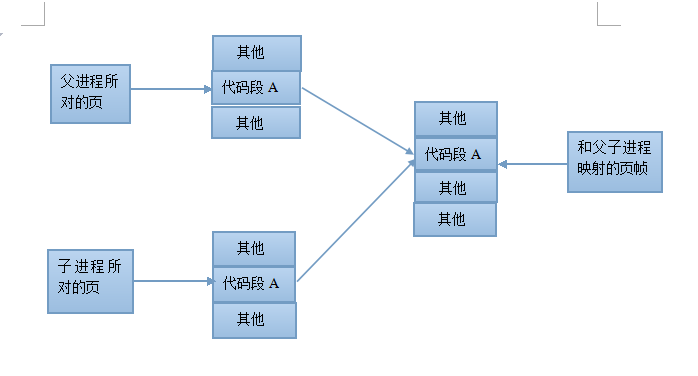
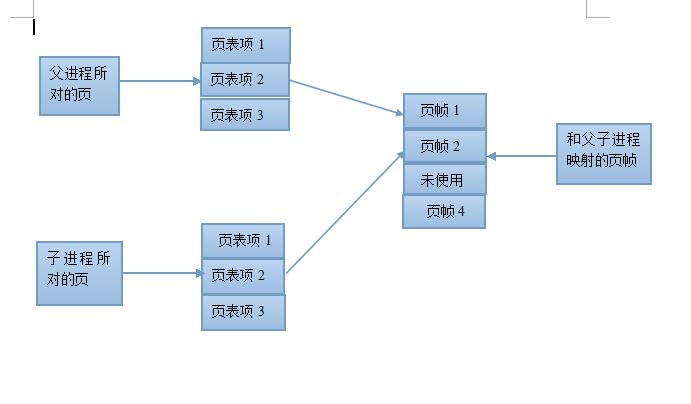
(2)而对于父进程的数据段,堆段,栈段中的各页,由于父子进程要相互独立,所以我们采用写实复制的技术,来最大化的提高内存以及内核的利用率。刚开始,内核做了一些设置,令这些段的页表项指向父进程相同的物理内存页。调用fork之后,内核会捕获所有父进程或子进程针对这些页面的修改企图(说明此时还没修改)并为将要修改的页面创建拷贝。系统将新的页面拷贝分配给被内核捕获的进程,还会对子进程的相应页表项做适当的调整,现在父子进程就可以分别修改各自的上述段,不再互相影响了
写实复制前:

写实赋值后:
3.总结
表面看起来fork()创建子进程子进程拷贝了父进程的地址空间其实不然
刚调用完fork()之后,子进程只是拥有一份和父进程相同的页表,其中页表中指向RAM代码段的部分是不会改变的,而指向数据段,堆段,栈段的会在我们将要改变父子进程各自的这部分内容时,才会将要操作的部分进行部分复制