关于CAS等原子操作
在开始说无锁队列之前,我们需要知道一个很重要的技术就是CAS操作——Compare & Set,或是 Compare & Swap,现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构。
这个操作用C语言来描述就是下面这个样子:(代码来自Wikipedia的Compare And Swap词条)意思就是说,看一看内存*reg里的值是不是oldval,如果是的话,则对其赋值newval。
int compare_and_swap (int* reg, int oldval, int newval)
{
int old_reg_val = *reg;
if (old_reg_val == oldval) {
*reg = newval;
}
return old_reg_val;
}
我们可以看到,old_reg_val 总是返回,于是,我们可以在 compare_and_swap 操作之后对其进行测试,以查看它是否与 oldval相匹配,因为它可能有所不同,这意味着另一个并发线程已成功地竞争到 compare_and_swap 并成功将 reg 值从 oldval 更改为别的值了。
这个操作可以变种为返回bool值的形式(返回 bool值的好处在于,可以调用者知道有没有更新成功):
bool compare_and_swap (int *addr, int oldval, int newval)
{
if ( *addr != oldval ) {
return false;
}
*addr = newval;
return true;
}
与CAS相似的还有下面的原子操作:(这些东西大家自己看Wikipedia,也没什么复杂的)
- Fetch And Add,一般用来对变量做 +1 的原子操作
- Test-and-set,写值到某个内存位置并传回其旧值。汇编指令BST
- Test and Test-and-set,用来低低Test-and-Set的资源争夺情况
注:在实际的C/C++程序中,CAS的各种实现版本如下:
1)GCC的CAS
GCC4.1+版本中支持CAS的原子操作(完整的原子操作可参看 GCC Atomic Builtins)
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)
2)Windows的CAS
在Windows下,你可以使用下面的Windows API来完成CAS:(完整的Windows原子操作可参看MSDN的InterLocked Functions)
InterlockedCompareExchange ( __inout LONG volatile *Target,
__in LONG Exchange,
__in LONG Comperand);
3) C++11中的CAS
C++11中的STL中的atomic类的函数可以让你跨平台。(完整的C++11的原子操作可参看 Atomic Operation Library)
template< class T >
bool atomic_compare_exchange_weak( std::atomic* obj,
T* expected, T desired );
template< class T >
bool atomic_compare_exchange_weak( volatile std::atomic* obj,
T* expected, T desired );
无锁队列的链表实现
下面的代码主要参考于两篇论文:
- John D. Valois 1994年10月在拉斯维加斯的并行和分布系统系统国际大会上的一篇论文——《Implementing Lock-Free Queues》
- 美国纽约罗切斯特大学 Maged M. Michael 和 Michael L. Scott 在1996年3月发表的一篇论文 《Simple, Fast, and Practical Non-Blocking and Blocking ConcurrentQueue Algorithms》
- (注:下面的代码并不完全与这篇论文相同)
初始化一个队列的代码很简,初始化一个dummy结点(注:在链表操作中,使用一个dummy结点,可以少掉很多边界条件的判断),如下所示:
InitQueue(Q)
{
node = new node()
node->next = NULL;
Q->head = Q->tail = node;
}
我们先来看一下进队列用CAS实现的方式,基本上来说就是链表的两步操作:
第一步,把tail指针的next指向要加入的结点。 tail->next = p;
第二步,把tail指针移到队尾。 tail = p;
EnQueue(Q, data) //进队列
{
//准备新加入的结点数据
n = new node();
n->value = data;
n->next = NULL;
do {
p = Q->tail; //取链表尾指针的快照
} while( CAS(p->next, NULL, n) != TRUE);
//while条件注释:如果没有把结点链在尾指针上,再试
CAS(Q->tail, p, n); //置尾结点 tail = n;
}
我们可以看到,程序中的那个 do-while 的 Retry-Loop 中的 CAS 操作:如果 p->next 是 NULL,那么,把新结点 n 加到队尾。如果不成功,则重新再来一次!
就是说,很有可能我在准备在队列尾加入结点时,别的线程已经加成功了,于是tail指针就变了,于是我的CAS返回了false,于是程序再试,直到试成功为止。这个很像我们的抢电话热线的不停重播的情况。
但是你会看到,为什么我们的“置尾结点”的操作(第13行)不判断是否成功,因为:
- 如果有一个线程T1,它的while中的CAS如果成功的话,那么其它所有的 随后线程的CAS都会失败,然后就会再循环,
- 此时,如果T1 线程还没有更新tail指针,其它的线程继续失败,因为tail->next不是NULL了。
- 直到T1线程更新完 tail 指针,于是其它的线程中的某个线程就可以得到新的 tail 指针,继续往下走了。
- 所以,只要线程能从 while 循环中退出来,意味着,它已经“独占”了,tail 指针必然可以被更新。
这里有一个潜在的问题——如果T1线程在用CAS更新tail指针的之前,线程停掉或是挂掉了,那么其它线程就进入死循环了。下面是改良版的EnQueue()
EnQueue(Q, data) //进队列改良版 v1
{
n = new node();
n->value = data;
n->next = NULL;
p = Q->tail;
oldp = p
do {
while (p->next != NULL)
p = p->next;
} while( CAS(p.next, NULL, n) != TRUE); //如果没有把结点链在尾上,再试
CAS(Q->tail, oldp, n); //置尾结点
}
我们让每个线程,自己fetch 指针 p 到链表尾。但是这样的fetch会很影响性能。而且,如果一个线程不断的EnQueue,会导致所有的其它线程都去 fetch 他们的 p 指针到队尾,能不能不要所有的线程都干同一个事?这样可以节省整体的时间?
比如:直接 fetch Q->tail 到队尾?因为,所有的线程都共享着 Q->tail,所以,一旦有人动了它后,相当于其它的线程也跟着动了,于是,我们的代码可以改进成如下的实现:
EnQueue(Q, data) //进队列改良版 v2
{
n = new node();
n->value = data;
n->next = NULL;
while(TRUE) {
//先取一下尾指针和尾指针的next
tail = Q->tail;
next = tail->next;
//如果尾指针已经被移动了,则重新开始
if ( tail != Q->tail ) continue;
//如果尾指针的 next 不为NULL,则 fetch 全局尾指针到next
if ( next != NULL ) {
CAS(Q->tail, tail, next);
continue;
}
//如果加入结点成功,则退出
if ( CAS(tail->next, next, n) == TRUE ) break;
}
CAS(Q->tail, tail, n); //置尾结点
}
上述的代码还是很清楚的,相信你一定能看懂,而且,这也是 Java 中的 ConcurrentLinkedQueue 的实现逻辑,当然,我上面的这个版本比 Java 的好一点,因为没有 if 嵌套,嘿嘿。
好了,我们解决了EnQueue,我们再来看看DeQueue的代码:(很简单,我就不解释了)
DeQueue(Q) //出队列
{
do{
p = Q->head;
if (p->next == NULL){
return ERR_EMPTY_QUEUE;
}
while( CAS(Q->head, p, p->next) != TRUE );
return p->next->value;
}
我们可以看到,DeQueue的代码操作的是 head->next,而不是 head 本身。这样考虑是因为一个边界条件,我们需要一个dummy的头指针来解决链表中如果只有一个元素,head 和 tail 都指向同一个结点的问题,这样 EnQueue 和 DeQueue 要互相排斥了。
但是,如果 head 和 tail 都指向同一个结点,这意味着队列为空,应该返回 ERR_EMPTY_QUEUE,但是,在判断 p->next == NULL 时,另外一个EnQueue操作做了一半,此时的 p->next 不为 NULL了,但是 tail 指针还差最后一步,没有更新到新加的结点,这个时候就会出现,在 EnQueue 并没有完成的时候, DeQueue 已经把新增加的结点给取走了,此时,队列为空,但是,head 与 tail 并没有指向同一个结点。如下所示:
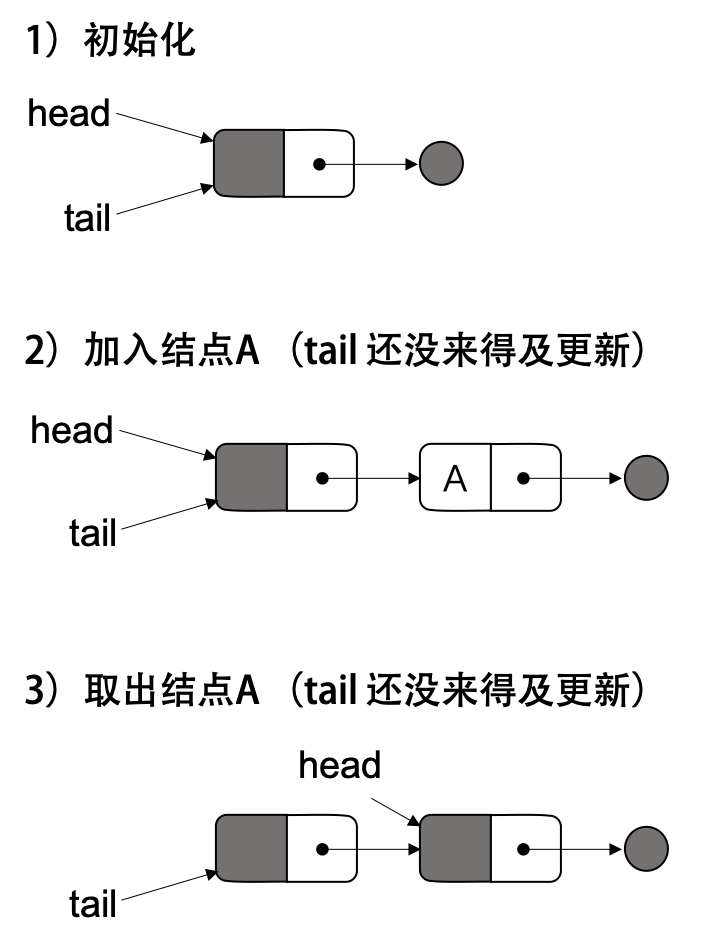
虽然,EnQueue的函数会把 tail 指针置对,但是,这种情况可能还是会导致一些并发问题,所以,严谨来说,我们需要避免这种情况。于是,我们需要加入更多的判断条件,还确保这个问题。下面是相关的改进代码:
DeQueue(Q) //出队列,改进版
{
while(TRUE) {
//取出头指针,尾指针,和第一个元素的指针
head = Q->head;
tail = Q->tail;
next = head->next;
// Q->head 指针已移动,重新取 head指针
if ( head != Q->head ) continue;
// 如果是空队列
if ( head == tail && next == NULL ) {
return ERR_EMPTY_QUEUE;
}
//如果 tail 指针落后了
if ( head == tail && next == NULL ) {
CAS(Q->tail, tail, next);
continue;
}
//移动 head 指针成功后,取出数据
if ( CAS( Q->head, head, next) == TRUE){
value = next->value;
break;
}
}
free(head); //释放老的dummy结点
return value;
}
上面这段代码的逻辑和 Java 的 ConcurrentLinkedQueue 的 poll 方法很一致了。也是《Simple, Fast, and Practical Non-Blocking and Blocking ConcurrentQueue Algorithms》这篇论文中的实现。
CAS的ABA问题
所谓ABA(见维基百科的ABA词条),问题基本是这个样子:
- 进程P1在共享变量中读到值为A
- P1被抢占了,进程P2执行
- P2把共享变量里的值从A改成了B,再改回到A,此时被P1抢占。
- P1回来看到共享变量里的值没有被改变,于是继续执行。
虽然P1以为变量值没有改变,继续执行了,但是这个会引发一些潜在的问题。ABA问题最容易发生在lock free 的算法中的,CAS首当其冲,因为CAS判断的是指针的值。很明显,值是很容易又变成原样的。
比如上述的DeQueue()函数,因为我们要让head和tail分开,所以我们引入了一个dummy指针给head,当我们做CAS的之前,如果head的那块内存被回收并被重用了,而重用的内存又被EnQueue()进来了,这会有很大的问题。(内存管理中重用内存基本上是一种很常见的行为)
这个例子你可能没有看懂,维基百科上给了一个活生生的例子——
你拿着一个装满钱的手提箱在飞机场,此时过来了一个火辣性感的美女,然后她很暖昧地挑逗着你,并趁你不注意的时候,把用一个一模一样的手提箱和你那装满钱的箱子调了个包,然后就离开了,你看到你的手提箱还在那,于是就提着手提箱去赶飞机去了。
这就是ABA的问题。
解决ABA的问题
维基百科上给了一个解——使用double-CAS(双保险的CAS),例如,在32位系统上,我们要检查64位的内容
1)一次用CAS检查双倍长度的值,前半部是值,后半部分是一个计数器。
2)只有这两个都一样,才算通过检查,要吧赋新的值。并把计数器累加1。
这样一来,ABA发生时,虽然值一样,但是计数器就不一样(但是在32位的系统上,这个计数器会溢出回来又从1开始的,这还是会有ABA的问题)
当然,我们这个队列的问题就是不想让那个内存重用,这样明确的业务问题比较好解决,论文《Implementing Lock-Free Queues》给出一这么一个方法——使用结点内存引用计数refcnt!(论文《Simple, Fast, and Practical Non-Blocking and Blocking ConcurrentQueue Algorithms》中的实现方法也基本上是一样的,用到的是增加一个计数,可以理解为版本号)
)
SafeRead(q)
{
loop:
p = q->next;
if (p == NULL){
return p;
}
Fetch&Add(p->refcnt, 1);
if (p == q->next){
return p;
}else{
Release(p);
}
goto loop;
}
其中的 Fetch&Add和Release分是是加引用计数和减引用计数,都是原子操作,这样就可以阻止内存被回收了。
用数组实现无锁队列
本实现来自论文《Implementing Lock-Free Queues》
使用数组来实现队列是很常见的方法,因为没有内存的分部和释放,一切都会变得简单,实现的思路如下:
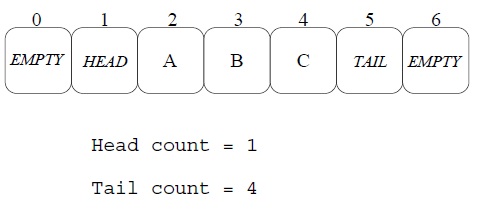
1)数组队列应该是一个ring buffer形式的数组(环形数组)
2)数组的元素应该有三个可能的值:HEAD,TAIL,EMPTY(当然,还有实际的数据)
3)数组一开始全部初始化成EMPTY,有两个相邻的元素要初始化成HEAD和TAIL,这代表空队列。
4)EnQueue操作。假设数据x要入队列,定位TAIL的位置,使用double-CAS方法把(TAIL, EMPTY) 更新成 (x, TAIL)。需要注意,如果找不到(TAIL, EMPTY),则说明队列满了。
5)DeQueue操作。定位HEAD的位置,把(HEAD, x)更新成(EMPTY, HEAD),并把x返回。同样需要注意,如果x是TAIL,则说明队列为空。
算法的一个关键是——如何定位HEAD或TAIL?
1)我们可以声明两个计数器,一个用来计数EnQueue的次数,一个用来计数DeQueue的次数。
2)这两个计算器使用使用Fetch&ADD来进行原子累加,在EnQueue或DeQueue完成的时候累加就好了。
3)累加后求个模什么的就可以知道TAIL和HEAD的位置了。
如下图所示:
### 小结
以上基本上就是所有的无锁队列的技术细节,这些技术都可以用在其它的无锁数据结构上。
1)无锁队列主要是通过CAS、FAA这些原子操作,和Retry-Loop实现。
2)对于Retry-Loop,我个人感觉其实和锁什么什么两样。只是这种“锁”的粒度变小了,主要是“锁”HEAD和TAIL这两个关键资源。而不是整个数据结构。
还有一些和Lock Free的文章你可以去看看:
Code Project 上的雄文 《Yet another implementation of a lock-free circular array queue》
Herb Sutter的《Writing Lock-Free Code: A Corrected Queue》– 用C++11的std::atomic模板。
IBM developerWorks的《设计不使用互斥锁的并发数据结构》