linux IO子系统和文件系统读写流程,是基于2.6.32及其后的内核.
我们在linux上总是要保存数据,数据要么保存在文件系统里(如ext3),要么就保存在裸设备里。我们在使用这些数据的时候都是通过文件这个抽象来访问的,操作系统会把我们需要的数据提交给我们,而我们则无需和块设备打交道。
从下图,我们可以清除的看到:

I/O子系统是个层次很深的系统,数据请求从用户空间最终到达磁盘,经过了复杂的数据流动。
对设驱开发人员或与此相关的设计人员,特别是IO很密集,我们就需要搞清楚IO具体是如何动作的,免得滥用IO和导致设计问题。(http://blog.yufeng.info/archives/751)
IBM developworks中,〈read系统调用剖析〉阐述就很清楚。
read系统调用的处理分为用户空间和内核空间处理两部分。其中,用户空间处理只是通过0x80中断陷入内核,接着调用其中断服务例程,即sys_read以进入内核处理流程。
对于read系统调用在内核的处理,如上图所述,经过了VFS、具体文件系统,如ext2、页高速缓冲存层、通用块层、IO调度层、设备驱动层、和设备层。其中,VFS主要是用来屏蔽下层具体文件系统操作的差异,对上提供一个统一接口,正是因为有了这个层次,所以可以把设备抽象成文件。具体文件系统,则定义了自己的块大小、操作集合等。引入cache层的目的,是为了提高IO效率。它缓存了磁盘上的部分数据,当请求到达时,如果在cache中存在该数据且是最新的,则直接将其传递给用户程序,免除了对底层磁盘的操作。通用块层的主要工作是,接收上层发出的磁盘请求,并最终发出IO请求(BIO)。IO调度层则试图根据设置好的调度算法对通用块层的bio请求合并和排序,回调驱动层提供的请求处理函数,以处理具体的IO请求。驱动层的驱动程序对应具体的物理设备,它从上层取出IO请求,并根据该IO请求中指定的信息,通过向具体块设备的设备控制器发送命令的方式,来操纵设备传输数据。设备层都是具体的物理设备。
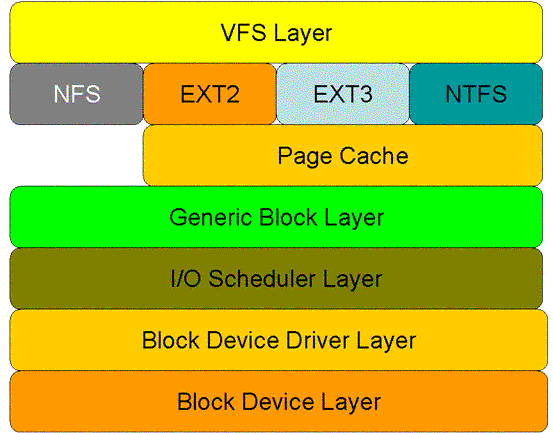
VFS层:
内核函数sys_read是read系统调用在该层的入口点。
它根据文件fd指定的索引,从当前进程描述符中取出相应的file对象,并调用vfs_read执行文件读取操作。
vfs_read会调用与具体文件相关的read函数执行读取操作,file->f_op.read。
然后,VFS将控制权交给了ext2文件系统。(ext2在此作为示例,进行解析)
Ext2文件系统层的处理
通过ext2_file_operations结构知道,上述函数最终会调用到do_sync_read函数,它是系统通用的读取函数。所以说,do_sync_read才是ext2层的真实入口。
该层入口函数 do_sync_read 调用函数 generic_file_aio_read ,后者判断本次读请求的访问方式,如果是直接 io (filp->f_flags 被设置了 O_DIRECT 标志,即不经过 cache)的方式,则调用 generic_file_direct_IO 函数;如果是 page cache 的方式,则调用 do_generic_file_read 函数。它会判断该页是否在页高速缓存,如果是,直接将数据拷贝到用户空间。如果不在,则调用page_cache_sync_readahead函数执行预读(检查是否可以预读),它会调用mpage_readpages。如果仍然未能命中(可能不允许预读或者其它原因),则直接跳转readpage,执行mpage_readpage,从磁盘读取数据。
在mpage_readpages(一次读多个页)中,它会将连续的磁盘块放入同一个BIO,并延缓BIO的提交,直到出现不连续的块,则直接提交BIO,再继续处理,以构造另外的BIO。
文件的 page cache 结构
图5显示了一个文件的 page cache 结构。文件被分割为一个个以 page 大小为单元的数据块,这些数据块(页)被组织成一个多叉树(称为 radix 树)。树中所有叶子节点为一个个页帧结构(struct page),表示了用于缓存该文件的每一个页。在叶子层最左端的第一个页保存着该文件的前4096个字节(如果页的大小为4096字节),接下来的页保存着文件第二个4096个字节,依次类推。树中的所有中间节点为组织节点,指示某一地址上的数据所在的页。此树的层次可以从0层到6层,所支持的文件大小从0字节到16 T 个字节。树的根节点指针可以从和文件相关的 address_space 对象(该对象保存在和文件关联的 inode 对象中)中取得(更多关于 page cache 的结构内容请参见参考资料)。

mpage处理机制就是page cache层要处理的问题。
通用块层
在缓存层处理末尾,执行mpage_submit_bio之后,会调用generic_make_request函数。这是通用块层的入口函数。
它将bio传送到IO调度层进行处理。
IO调度层
对bio进行合并、排序,以提高IO效率。然后,调用设备驱动层的回调函数,request_fn,转到设备驱动层处理。
设备驱动层
request函数对请求队列中每个bio进行分别处理,根据bio中的信息向磁盘控制器发送命令。处理完成后,调用完成函数end_bio以通知上层完成。