一、什么是CAS
CAS:Compare and Swap,即比较再交换。
CAS 的思想很简单:三个参数,一个当前内存值 V、旧的预期值 A、即将更新的值 B,当且仅当预期值 A 和内存值 V 相同时,将内存值修改为 B 并返回 true,否则什么都不做,并返回 false。
上面那段话来源于官方解析
Atomic原子类底层核心就是CAS,无锁化,乐观锁,每次尝试修改的时候,就对比一下,有没有人修改过这个值,没有人修改,自己就修改,如果有人修改过,就重新查出来最新的值,再次重复那个过程
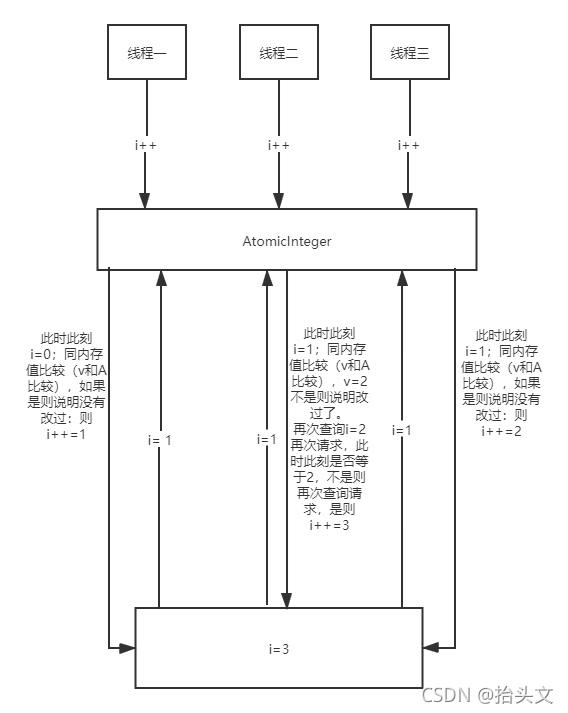
二、CAS 底层原理
我们拿 AtomicInteger 类来分析,先来看看 AtomicInteger 静态代码块片段:
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
// 省略部分代码
}这里用到了 sun.misc.Unsafe 类它可以提供硬件级别的原子操作,它可以获取某个属性在内存中的位置,也可以修改对象的字段值,只不过该类对一般开发而言,很少会用到,其底层是用 C/C++ 实现的,所以它的方式都是被 native 关键字修饰过的。
而且的话人家限制好了,不允许你去实例化他以及使用他里面的方法的,首先人家的构造函数是私有化,不能自己手动去实例化他,
其次,如果用Unsafe.getUnsafe()方法来获取一个实例是不行的,在那个源码里,他会判断一下,如果当前是属于我们的用户的应用系统,识别到有我们的那个类加载器以后,就会报错,不让我们来获取实例JDK源码里面,JDK自己内部来使用,不是对外的Unsafe,封装了一些不安全的操作,指针相关的一些操作,就是比较底层了,主要就是Atomic原子类底层大量的运用了Unsafe
如果想使用Unsafe可以通过反射获取:
//自己定义一个类获取Unsafe
public class UnsafeInstance {
public static Unsafe reflectGetUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
}
//调用使用方式
private static final Unsafe unsafe = UnsafeInstance.reflectGetUnsafe();
private static long stateOffset;
static {
try {
stateOffset = unsafe.objectFieldOffset(AQSLock.class.getDeclaredField("state"));
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}我们看到AtomicInteger初始化的时候来进行执行的,valueOffset,value这个字段在AtomicInteger这个类中的偏移量,在底层,这个类是有自己对应的结构的,无论是在磁盘的.class文件里,还是在JVM内存中
大概可以理解为:value这个字段具体是在AtomicInteger这个类的哪个位置,offset,偏移量,这个是很底层的操作,是通过unsafe来实现的。刚刚在类初始化的时候,就会完成这个操作的,final的,一旦初始化完毕,就不会再变更了
#############
接下来看一下AtomicInteger 中的getAndIncrement 方法
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));// 自旋
return var5;
}var5 通过 this.getIntVolatile(var1, var2)方法获取,认为当前的value值。去跟底层当前目前AtomicInteger对象实例中的value值比较,如果是一样的话这就是compare的过程,就是set的过程,也就是将value的值设置为i+1(递增的值),如果var5(获取到的值)跟AtomicInteger + valueOffset获取到的当前的值,不一样的话,此时compareAndSwapInt方法就会返回false,进入下一轮循环,重新执行getIntVolatile(var1, var2)再次获取 value 值,因为变量 value 被 volatile 修饰,所以其它线程对它的修改,线程 A 总是能够看到,线程A继续执行compareAndSwapInt进行比较替换,直到成功。

compareAndSwapInt 方法是一个本地方法:
public final native boolean compareAndSwapInt(Object paramObject, long paramLong, int paramInt1, int paramInt2);Java 并没有直接实现 CAS,CAS 相关的实现是通过 C++ 内联汇编的形式实现的。Java 代码需通过 JNI 才能调用,位于 unsafe.cpp,查看源码:
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END看不懂具体是啥意思,网上资料总结:
1、先想办法拿到变量 value 在内存中的地址。
2、通过Atomic::cmpxchg实现比较替换,其中参数 x 是即将更新的值,参数 e 是原内存的值。
以上1、2解析步骤来源于:https://www.jianshu.com/p/fb6e91b013cc
三、CAS的缺点
此处参考 https://objcoding.com/2018/11/29/cas/#similar_posts
1、ABA问题
- 线程1 查询A的值为a,与旧值a比较,
- 线程2 查询A的值为a,与旧值a比较,相等,更新为b值
- 线程2 查询A的值为b,与旧值b比较,相等,更新为a值
- 线程1 相等,更新B的值为c,尽管线程 1 也更改成功了,但是不代表这个过程就是没有问题的。
- 仔细思考,这样可能带来的问题是,如果需要关注A值变化过程,是会漏掉一段时间窗口的监控
举例分析:
现有一个用单向链表实现的栈,栈顶元素为 A,A.next 为 B,期望用 CAS 将栈顶替换成 B。
有线程 1 获取了元素 A,此时线程 1 被挂起,线程 2 也获取了元素 A,并将 A、B 出栈,再 push D、C、A,这时线程 1 恢复执行 CAS,因为此时栈顶元素依然为 A,线程 1 执行成功,栈顶元素变成了 B,但 B.next 为 null,这就会导致 C、D 被丢掉了。
这个例子充分说明了 CAS 的 ABA 问退带来的隐患,通常,我们的乐观锁实现中都会带一个 version 字段来记录更改的版本,避免并发操作带来的问题。在 Java 中,AtomicStampedReference 也实现了这个处理方式。
AtomicStampedReference 的内部类 Pair:
private static class Pair<T> {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}如上,每个 Pair 维护一个值,其中 reference 维护对象的引用,stamp 维护修改的版本号。
compareAndSet 方法:
/**
* Atomically sets the value of both the reference and stamp
* to the given update values if the
* current reference is {@code ==} to the expected reference
* and the current stamp is equal to the expected stamp.
*
* @param expectedReference the expected value of the reference
* @param newReference the new value for the reference
* @param expectedStamp the expected value of the stamp
* @param newStamp the new value for the stamp
* @return {@code true} if successful
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}从 compareAndSet 方法得知,如果要更改内存中的值,不但要值相同,还要版本号相同。
举例分析:
public class AtomicStampedReferenceTest {
// 初始值为1,版本号为0
private static AtomicStampedReference<Integer> a = new AtomicStampedReference<>(1, 0);
// 计数器
private static CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) {
new Thread(() -> {
System.out.println("线程名字:" + Thread.currentThread() + ", 当前 value = " + a.getReference());
// 获取当前版本号
int stamp = a.getStamp();
// 计数器阻塞,直到计数器为0,才执行
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程名字:" + Thread.currentThread() + ",CAS操作结果: " + a.compareAndSet(1, 2, stamp, stamp + 1));
}, "线程1").start();
// 线程2
new Thread(() -> {
// 将 value 值改成 2
a.compareAndSet(1, 2, a.getStamp(), a.getStamp() + 1);
System.out.println("线程名字" + Thread.currentThread() + "value = " + a.getReference());
// 将 value 值又改成 1
a.compareAndSet(2, 1, a.getStamp(), a.getStamp() + 1);
System.out.println("线程名字" + Thread.currentThread() + "value = " + a.getReference());
// 线程计数器
countDownLatch.countDown();
}, "线程2").start();
}
}2、无限循环问题:大家看源码就知道Atomic类设置值的时候会进入一个无限循环,只要不成功,就不停循环再次尝试,这个在高并发修改一个值的时候其实挺常见的,比如你用AtomicInteger在内存里搞一个原子变量,然后高并发下,多线程频繁修改,其实可能会导致这个compareAndSet()里要循环N次才设置成功,所以还是要考虑到的。
JDK 1.8引入的LongAdder来解决,是一个重点,分段CAS思路
3、多变量原子问题:一般的AtomicInteger,只能保证一个变量的原子性,但是如果多个变量呢?你可以用AtomicReference,这个是封装自定义对象的,多个变量可以放一个自定义对象里,然后他会检查这个对象的引用是不是一个。