排序
冒泡算法
arr = [1, 36, 7, 102, 54]
def BubbleSort(arr):
n = len(arr)
for i in range(0,n-1): #最后一位不用排了,所以是n-1
for j in range(0,n-1-i): #冒泡排序从后到前,不断减少范围
if arr[j]>arr[j+1]:
arr[j],arr[j+1]=arr[j+1],arr[j]
return arr
BubbleSort(arr)
print(arr)
选择排序
arr = [1, 36, 7, 102, 54]
# 扫描一遍,把最小的放在最小位置
def SelectSort(arr):
n = len(arr)
for i in range(0,n-1):
min_index = i #记录每一个位子
for j in range(i+1,n):
if arr[i] > arr[j]:
min_index = j
arr[i],arr[min_index] = arr[min_index],arr[i]
return arr
SelectSort(arr)
print(arr)
插入排序
arr = [1, 36, 7, 102, 54]
def InsertionSort(arr):
n = len(arr)
for i in range(1, n):
j = i - 1 # i是当前位, j是前一位
while j >= 0:
if arr[j] > arr[i]: # 前面一位大于后面一位
tem = arr[i]
arr[j + 1] = arr[j]
arr[j] = tem
j -= 1
return (arr)
归并排序
def merge_sort(S):
n = len(S)
if n < 2:
return S
mid = n // 2
S1 = S[0:mid]
S2 = S[mid:n]
merge_sort(S1)
merge_sort(S2)
merge(S1, S2, S)
def merge(S1, S2, S):
i = j = 0
while i + j < len(S):
if j == len(S2) or (i < len(S1) and S1[i] < S2[j]):
S[i + j] = S1[i]
i += 1
else:
S[i + j] = S2[j]
i += 1
return S
链表归并排序
class LinkedQueue():
def __init__(self, val):
self.val = val
self.next = None
def enqueue(self):
pass
def dequeue(self):
pass
class Solution:
S = LinkedQueue(None)
def merge(self, S1, S2, S):
while not S1.is_empty() and S2.is_empty():
if S1.first() < S2.first():
S.enqueue(S1.dequeue())
else:
S.enqueue(S2.dequeue())
while not S1.is_empty():
S.enqueue(S1.dequeue())
while not S2.is_empty():
S.enqueue(S2.dequeue())
def merge_sort(self, S):
n = len(S)
if n < 2:
return
S1 = LinkedQueue(None)
S2 = LinkedQueue(None)
while len(S1) < n//2:
S1.enqueue(S.dequeue())
while not S.is_empty():
S2.enqueue(S.dequeue())
self.merge_sort(S1)
self.merge_sort(S2)
快速排序
class Solution:
def quicksort(self, S):
if len(S) < 2:
return S
else:
pivot = S[len(S)//2] # 基准值
left = [i for i in S if i < pivot]
right = [i for i in S if i > pivot]
mid = [i for i in S if i == pivot]
return self.quicksort(left) + mid + self.quicksort(right)
if __name__ == '__main__':
arr = [57, 89, 65, 4, 5, 7, 32, 28, 456]
Solution = Solution()
print(Solution.quicksort(arr))
原地快速排序
def inplace_quick_sort(S, a, b):
if a >= b: return
pivot = S[b]
left = a
right = b-1
while left <= right:
while left <= right and S[left] < pivot:
left += 1
while left <= right and pivot < S[right]:
right -= 1
if left <= right:
S[left], S[right] = S[right], S[left]
left, right = left+1, right-1
S[left], S[b] = S[b], S[left]
inplace_quick_sort(S, a, left-1)
inplace_quick_sort(S, left+1, b)
return S
S = [1, 8, 6, 5, 7, 2]
print(inplace_quick_sort(S, 0, 5))
希尔排序
import random
source = [random.randrange(10000+i) for i in range(10000)]
step = int(len(source)/2)
while step>0:
for index in range(0, len(source)):
if index + step < len(source):
current_val = source[index]
if current_val > source[index+step]:
source[index], source[index+step] = source[index+step], source[index]
step = int(step/2)
else:
for index in range(1, len(source)):
current_val = source[index]
position = index
while position > 0 and source[position-1] > current_val:
source[position] = current_val
print(source)
基数排序
import random
def radixSort():
A = [random.randint(1, 9999) for i in range(10000)]
for k in range(4): # 4轮排序
s = [[] for i in range(10)] # 10个桶
for i in A:
s[i // (10 ** k) % 10].append(i)
A = [a for b in s for a in b]
return A
print(radixSort())
堆排序
def Max_Heapify(heap, heapsize, root):
'''
对一个父节点及其左右孩子节点调整;heap:list;heapsize:做数组最大限制,root:根节点位置
'''
left = 2 * root + 1 # 注意此处下标从0开始,下标为1开始时,公式为left = 2*root
right = left + 1
large = root
if left < heapsize and heap[large] < heap[left]:
large = left
if right < heapsize and heap[large] < heap[right]:
large = right
if root != large:
heap[root], heap[large] = heap[large], heap[root]
# 堆建立过程自下而上调整每个父节点及左右孩子
def Build_heap(heap, heapsize):
for root in range((heapsize - 1) // 2, -1, -1): # 表示求每个父节点位置
Max_Heapify(heap, heapsize, root)
# 堆排序
def Sort_heap(heap, heapsize, sortsize):
'''
heapsize:heap的长度
sortsize:未排序的数据个数
'''
Build_heap(heap, heapsize) # 排序前先建立一个最大堆
heap[0], heap[sortsize] = heap[sortsize], heap[0]
heapsize -= 1 # 最大值移到最后一位之后,将其从树中删除
sortsize -= 1 # 未排序个数减1
if sortsize != 0:
Sort_heap(heap, heapsize, sortsize)
计数排序
import random
def countingSort(alist, k):
n = len(alist)
b = [0 for i in range(n)]
c = [0 for i in range(k + 1)]
for i in alist:
c[i] += 1
for i in range(1, len(c)):
c[i] = c[i - 1] + c[i]
for i in alist:
b - 1] = i
c[i] -= 1
return b
if __name__ == '__main__':
a = [random.randint(0, 100) for i in range(100)]
print(countingSort(a, 100))
桶排序
import random
class bucketSort(object):
def _max(self, oldlist): # 返回最大值
_max = oldlist[0]
for i in oldlist:
if i > _max:
_max = i
return _max
def _min(self, oldlist): # 返回最小值
_min = oldlist[0]
for i in oldlist:
if i < _min:
_min = i
return _min
def sort(self, oldlist):
_max = self._max(oldlist)
_min = self._min(oldlist)
s = [0 for i in range(_min, _max + 1)] # 初始值都是0的桶
for i in oldlist:
s[i - _min] += 1
current = _min
n = 0
for i in s:
while i > 0:
oldlist[n] = current
i -= 1
n += 1
current += 1
def __call__(self, oldlist):
self.sort(oldlist)
return oldlist
if __name__ == '__main__':
a = [random.randint(0, 100) for i in range(10)]
bucketSort()(a)
print(a)
二叉树遍历
前序遍历
# 前序遍历
def preorder(root):
if not root:
return []
return [root.val] + preorder(root.left) + preorder(root.right)
# 前序遍历的非递归实现 中左右
def preorderTraversal(root):
stack = [] # 右节点压入栈中,左节点递归
sol = []
curr = root
while stack or curr:
if curr:
sol.append(curr.val)
stack.append(curr.right)
curr = curr.left
else:
curr = stack.pop()
return sol
中序遍历
# 中序遍历的递归版本
def inorderTraversal(root):
if not root:
return []
return inorderTraversal(root.left) + [root.val] + inorderTraversal(root.right)
# 中序遍历的非递归版本
def inorderTraversal(self, root):
stack = [] # 把中间节点压入栈中
sol = []
curr = root
while stack or curr:
if curr:
stack.append(curr)
curr = curr.left
else:
curr = stack.pop()
sol.append(curr.val)
curr = curr.right
return sol
后序遍历
# 后序遍历的递归实现
def postorderTraversal(self, root): ##后序遍历
if not root:
return []
return self.inorderTraversal(root.left) + self.inorderTraversal(root.right) + [root.val]
# 后序遍历的非递归实现 左右中 [::-1] 中右左
def postorderTraversal(self, root): ## 后序遍历
stack = [] # 把左节点压入栈中,指针沿着右节点走
sol = []
curr = root
while stack or curr:
if curr:
sol.append(curr.val)
stack.append(curr.left)
curr = curr.right
else:
curr = stack.pop()
return sol[::-1]
广度优先遍历
# 广度优先递归实现
class Solution:
def levelOrder(self, root):
def helper(node, level):
if not node:
return
else:
sol[level-1].append(node.val)
if len(sol) == level: # 遍历到新层时,只有最左边的结点使得等式成立
sol.append([])
helper(node.left, level+1)
helper(node.right, level+1)
sol = [[]]
helper(root, 1)
return sol[:-1]
# 广度优先遍历的非递归实现
class Solution:
def levelOrder(self, root):
if not root:
return []
sol = []
curr = root # 树的遍历一般都会使用到栈这个结构
queue = [curr]
while queue:
curr = queue.pop(0)
sol.append(curr.val)
if curr.left:
queue.append(curr.left)
if curr.right:
queue.append(curr.right)
return sol
海量数据Top k算法
寻找最大的K个数
方法一:先对数据进行排序,然后取前K个
时间复杂度:O(k+n*logn)
方法二:维持一个最小堆,如果数值小于堆顶,就直接pass,如果大于堆顶,就直接替换堆顶,然后重新整理最小堆,整理一次的时间复杂度是logk
时间复杂度:O( k+(n-k)*logk )
方法三:类似quick select
# 海量数据Top k
def partition(seq):
qviot, seq = seq[0], seq[1:] # 选取并移除主元
right = [x for x in seq if x <= qviot] # 值较小的
left = [x for x in seq if x > qviot]
return right, qviot, left
def select(seq, k):
right, qviot, left = partition(seq)
m = len(right)
if m == k:
return right
if m < k:
right.append(qviot)
return right+select(left, k-m-1)
return select(right, k)
if __name__ == "__main__":
sel = [8,3,4,5,1,5,23,5,1,3,53,645,314,632,65,76,2,46,575,1,5]
print(select(sel, 5))
哈希表
什么是哈希函数?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
常用的哈希函数有哪些?
- 直接定址法
取关键字或关键字的某个线性函数值为散列地址。
即 H(key) = key 或 H(key) = a*key + b,其中a和b为常数。 - 除留余数法
取关键字被某个不大于散列表长度 m 的数 p 求余,得到的作为散列地址。
即 H(key) = key % p, p < m。 - 数字分析法
当关键字的位数大于地址的位数,对关键字的各位分布进行分析,选出分布均匀的任意几位作为散列地址。
仅适用于所有关键字都已知的情况下,根据实际应用确定要选取的部分,尽量避免发生冲突。 - 平方取中法
先计算出关键字值的平方,然后取平方值中间几位作为散列地址。
随机分布的关键字,得到的散列地址也是随机分布的。 - 折叠法(叠加法)
将关键字分为位数相同的几部分,然后取这几部分的叠加和(舍去进位)作为散列地址。
用于关键字位数较多,并且关键字中每一位上数字分布大致均匀。 - 随机数法
选择一个随机函数,把关键字的随机函数值作为它的哈希值。
通常当关键字的长度不等时用这种方法。
解决冲突的方法:
- 开放地址法:除了哈希函数得出地址可用,当出现冲突的时候其他地址一样可以使用
- 再哈希法:按顺序规定多个哈希函数,每次查询时按顺序调用哈希函数
- 链地址法:所有关键字哈希值都存储在同一线性链表中
- 公共溢出区:一旦发生冲突全进入溢出表
- 装填因子: a=(表中填入记录数)/(哈希表长度)
a越小,冲突越小,0.75 比较合适
二叉树:
二叉树:
二叉树是每个节点最多有两个子树的树结构
二叉树有以下几个性质:TODO(上标和下标)
性质1:二叉树第i层上的结点数目最多为 2{i-1} (i≥1)。
性质2:深度为k的二叉树至多有2{k}-1个结点(k≥1)。
性质3:包含n个结点的二叉树的高度至少为log2 (n+1)。
性质4:在任意一棵二叉树中,若终端结点的个数为n0,度为2的结点数为n2,则n0=n2+1。

满二叉树,完全二叉树和二叉查找树
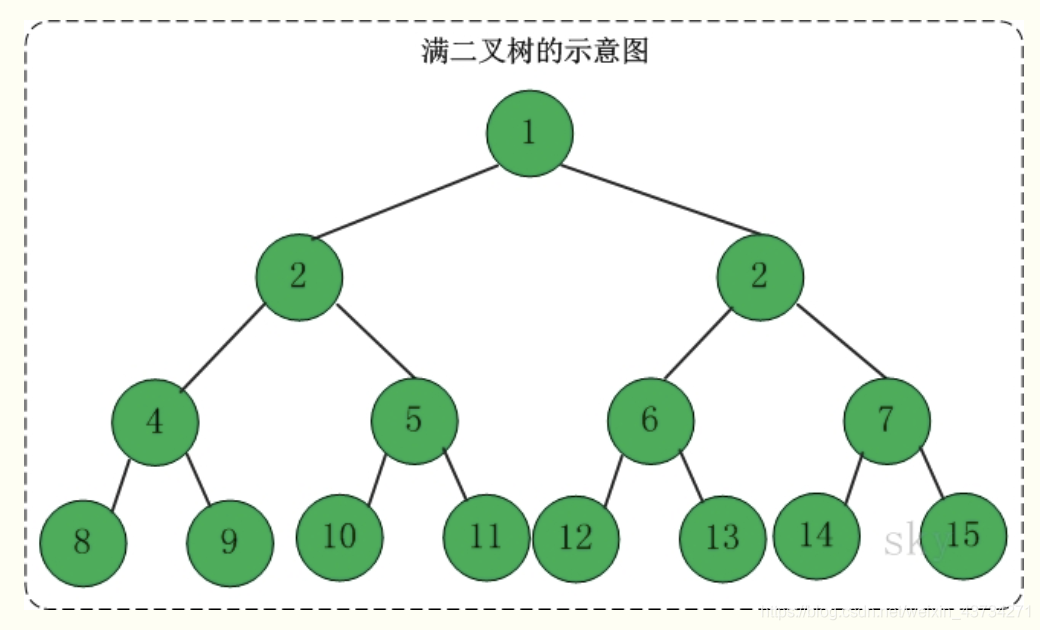
满二叉树
定义:高度为h,并且由2{h} –1个结点的二叉树,被称为满二叉树。
完全二叉树
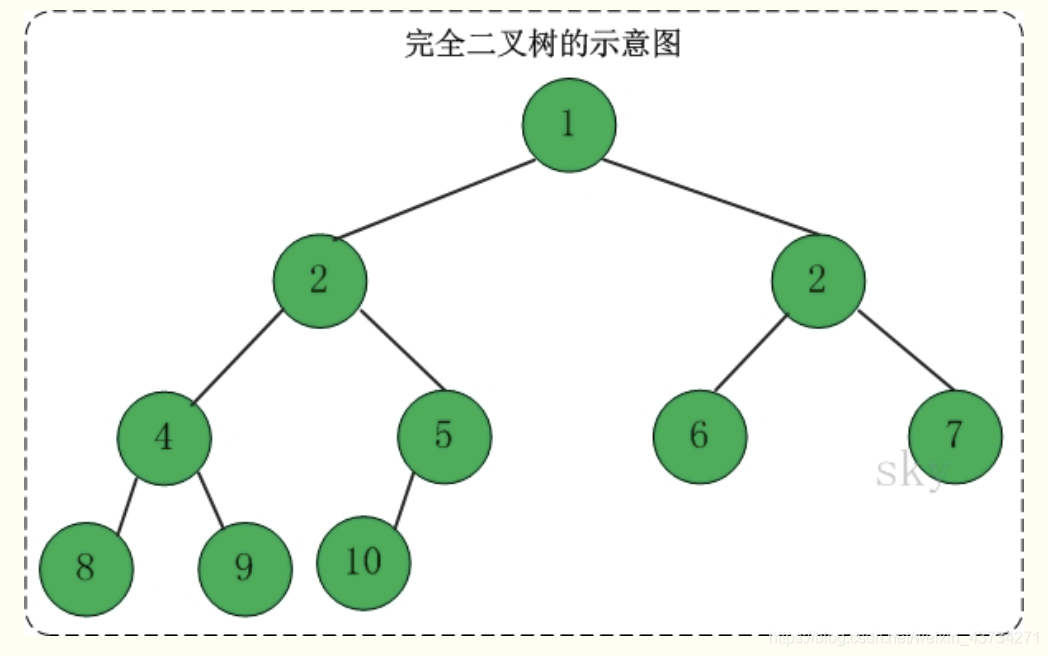
定义:一棵二叉树中,只有最下面两层结点的度可以小于2,并且最下一层的叶结点集中在靠左的若干位置上。这样的二叉树称为完全二叉树。
特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。显然,一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。
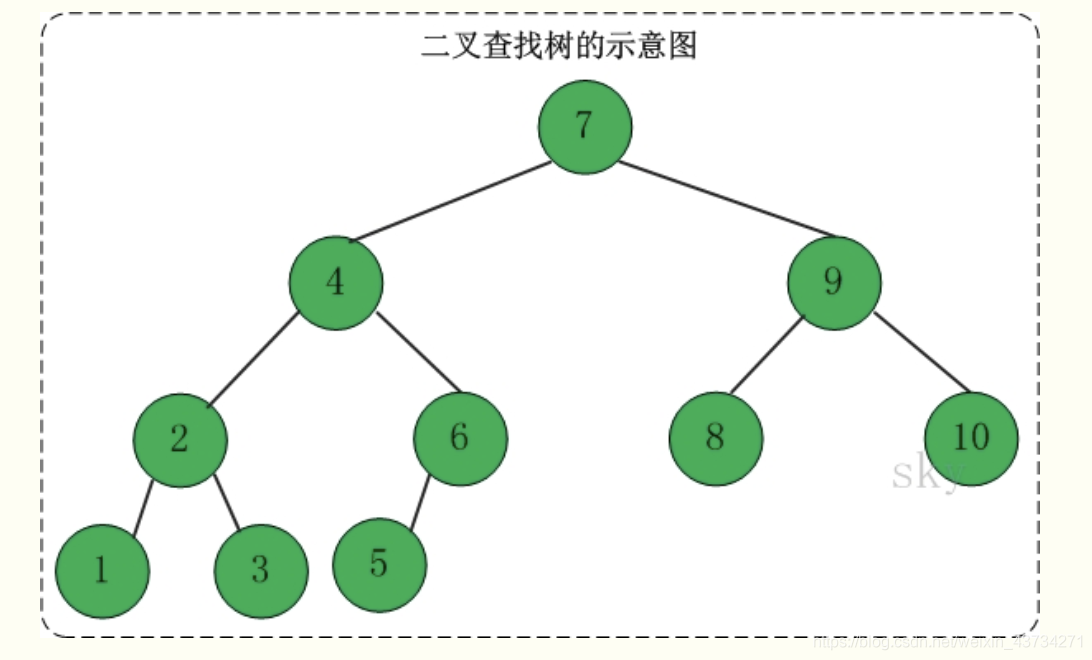
二叉查找树
定义:二叉查找树(Binary Search Tree),又被称为二叉搜索树。设x为二叉查找树中的一个结点,x节点包含关键字key,节点x的key值记为key[x]。如果y是x的左子树中的一个结点,则key[y] <= key[x];如果y是x的右子树的一个结点,则key[y] >= key[x]。
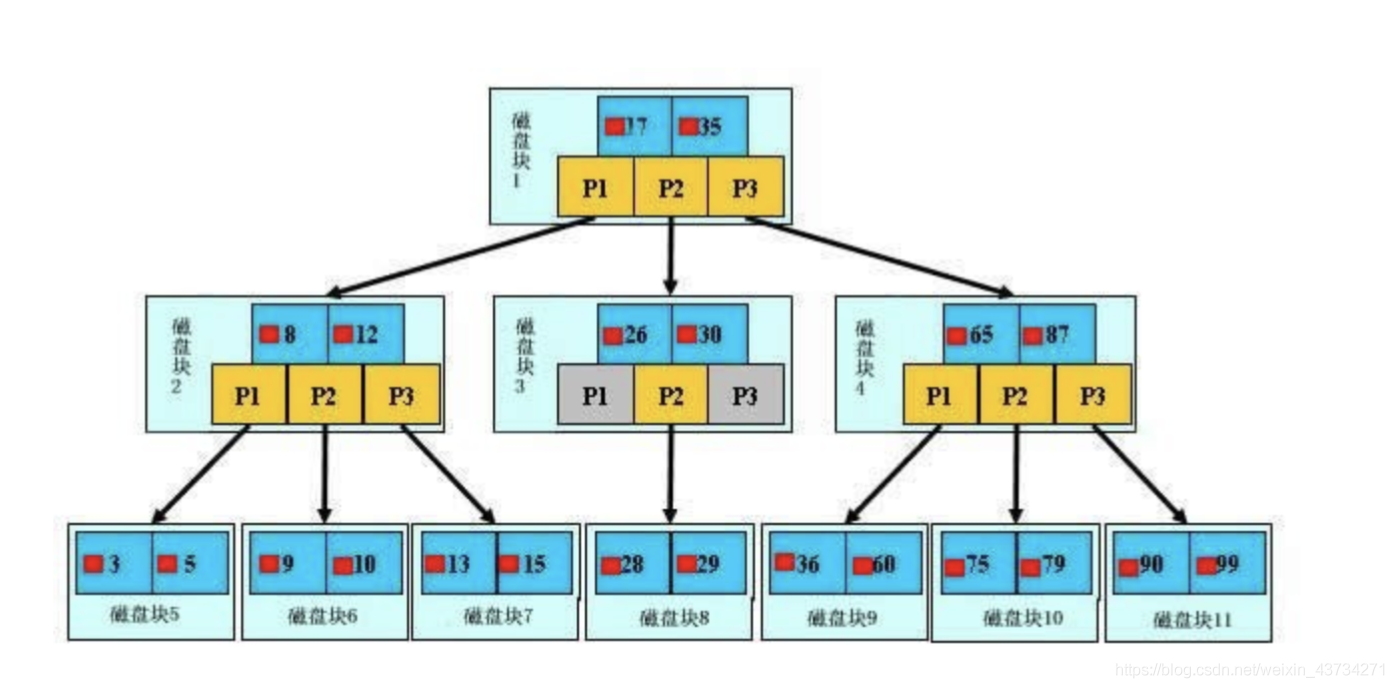
B树:
B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
- 根节点至少有两个子节点
- 每个节点有M-1个key,并且以升序排列
- 位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
- 其它节点至少有M/2个子节点
下图是一个M=4 阶的B树:
B+树:
B+树是对B树的一种变形树,它与B树的差异在于:
- 有k个子结点的结点必然有k个关键码;
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
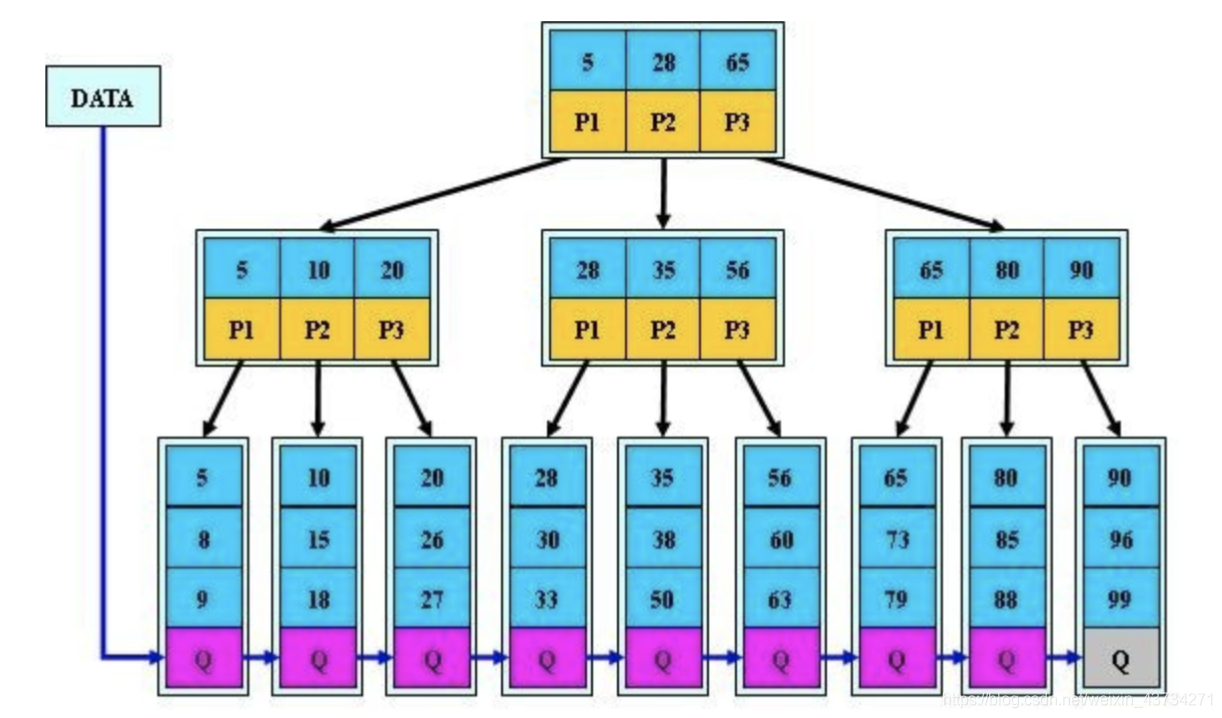
B+ 树的优点在于: - B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
- 由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率。
剖析2:为什么B+树比B树更适合做系统的数据库索引和文件索引
1)B+树的磁盘读写代价更低
因为B+树内部结点没有指向关键字具体信息的指针,内部结点相对B树小
2)B+树的查询更加稳定
因为非终端结点并不是指向文件内容的结点,仅仅是作为叶子结点的关键字索引,因此所有的关键字查询都会走一条从根节点到叶子结点的路径。即s所有关键字查询的长度是一样的,查询效率稳定。