在机器学习中,我们训练数据集去训练一个model(模型),通常的做法是定义一个Loss function(损失函数),通过这个最小化loss的过程来提高模型的性能。然而我们学习模型的目的是为了解决实际问题(或者说是训练这个数据集领域中的一般化问题),单纯的将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization error=bias+variance。注意:bias和variance是针对Generalization(一般化,泛化)来说的。
一、Bias
我们先来看个栗子(参考程序员在深圳的博主的博客),假设实验室收集了老鼠的体重和大小的数据,我们可以建立一个模型,通过输入老鼠的大小来预测老鼠的体重,部分数据的散点图如下。在训练之前,我们还是将数据拆分为两部分,红色的点为训练集,绿色的点表示测试集:
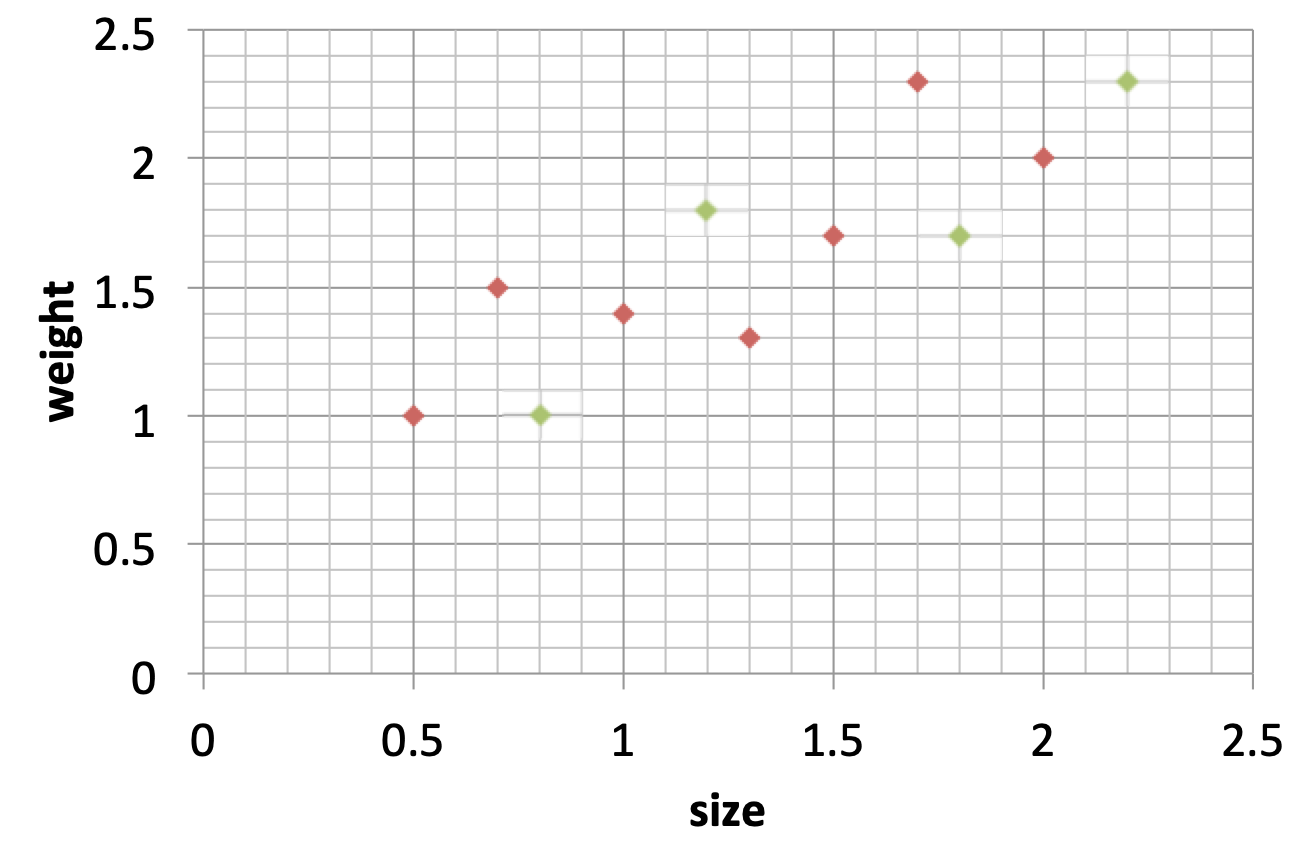
接下来我们用两个模型来拟合数据(可以使用最小二乘法来拟合),第一个模型如下图所示:
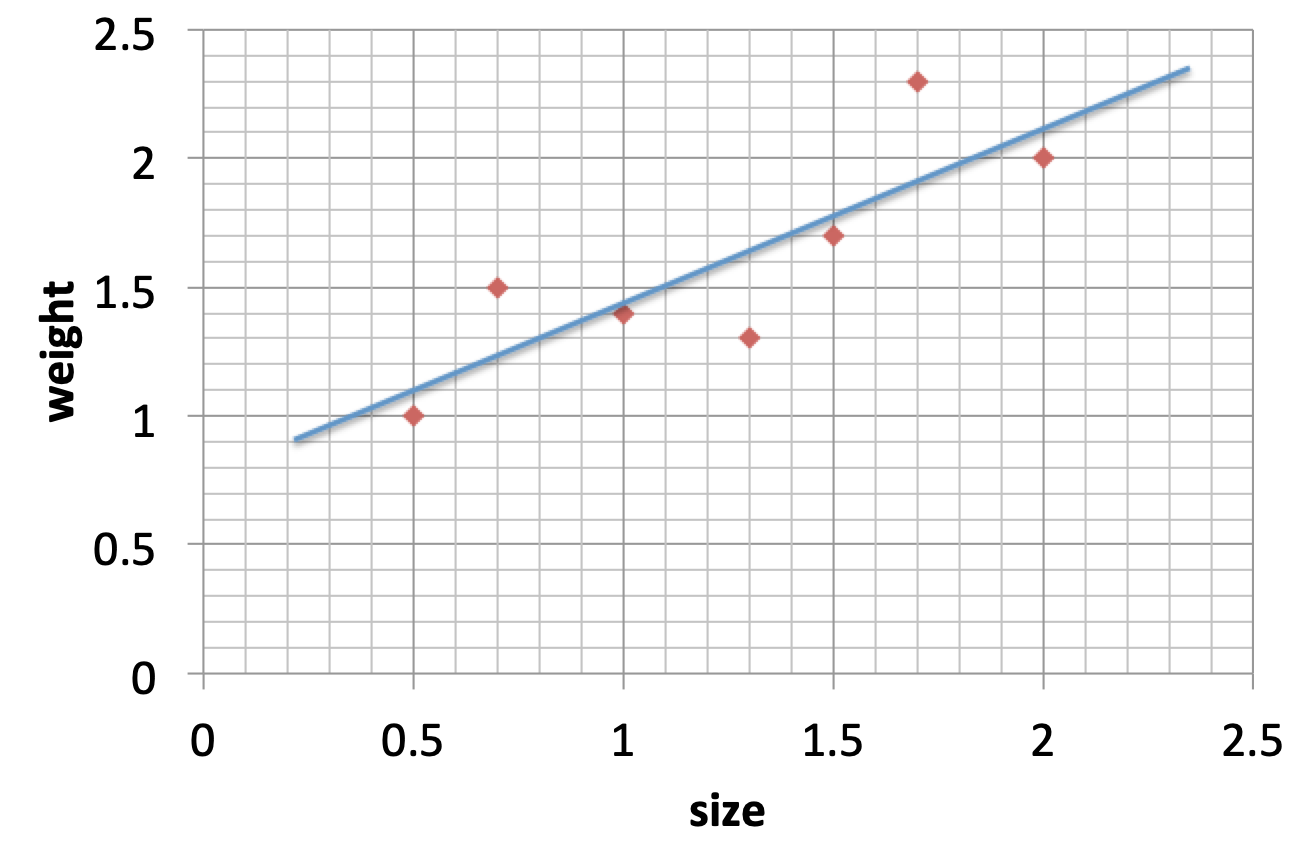 模型一
模型一
可以看到线性模型不能很好的拟合描绘真实数据,我们一般使用 MSE (Mean Squared Error) 来量化这种拟合能力,即预测值和实际值之间的差值的平方的均值。
第二个模型如下图 所示 :
 模型二
模型二
第二个模型完全与数据贴合 ,即用该模型训练数据时,获得的预测值与真实值相等。至此给出bias的定义就不难理解了:
Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,即算法本身的拟合能力。
从上面的例子可以看出,模型一的bias远大于模型二的bias
二、Variance
训练完模型后,我们还需要使用测试集对模型进行评估,下图是模型一的评估结果,我们用蓝色虚线来表示测试结果中,预测值和实际情况的差异:
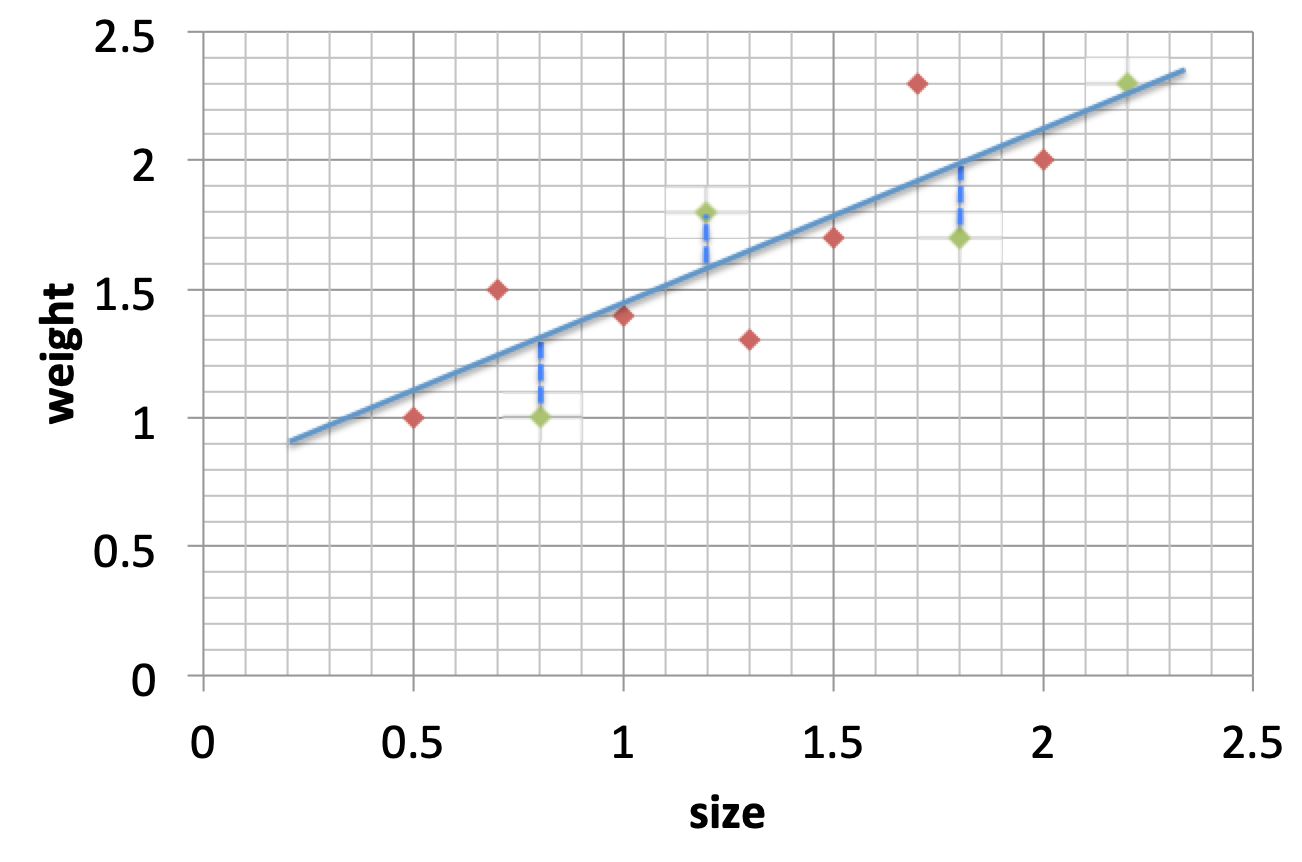 模型一
模型一
同样,模型二的评估结果如下:
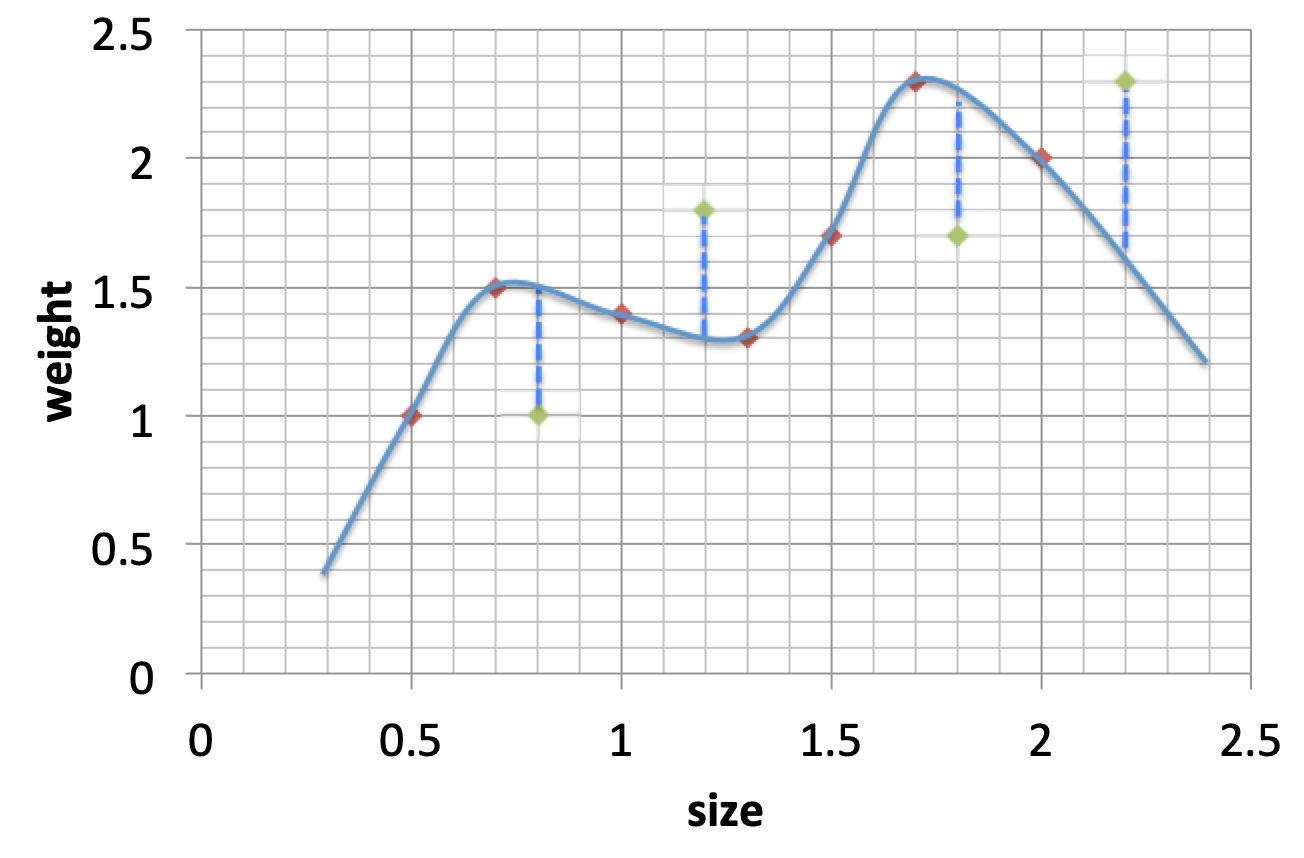 模型二
模型二
通过模型一和模型二可以看出,模型一的预测效果却远远好于模型二的,这说明模型二的预测能力并不稳定,即模型二的variance大于模型一的variance,下面给出variance的定义:
Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。反应预测的波动情况。
三、Bias&Variance
举个简单的例子(开枪问题)来理解Bias和Variance
想象你开着一架黑鹰直升机,得到命令攻击地面上一只敌军部队,于是你连打数十梭子,结果有一下几种情况:
1.子弹基本上都打在队伍经过的一棵树上了,连在那棵树旁边等兔子的人都毫发无损,这就是方差小(子弹打得很集中),偏差大(跟目的相距甚远)。
2.子弹打在了树上,石头上,树旁边等兔子的人身上,花花草草也都中弹,但是敌军安然无恙,这就是方差大(子弹到处都是),偏差大(同1)。
3.子弹打死了一部分敌军,但是也打偏了些打到花花草草了,这就是方差大(子弹不集中),偏差小(已经在目标周围了)。
4.子弹一颗没浪费,每一颗都打死一个敌军,跟抗战剧里的八路军一样,这就是方差小(子弹全部都集中在一个位置),偏差小(子弹集中的位置正是它应该射向的位置)。
直观解释如下图所示 :
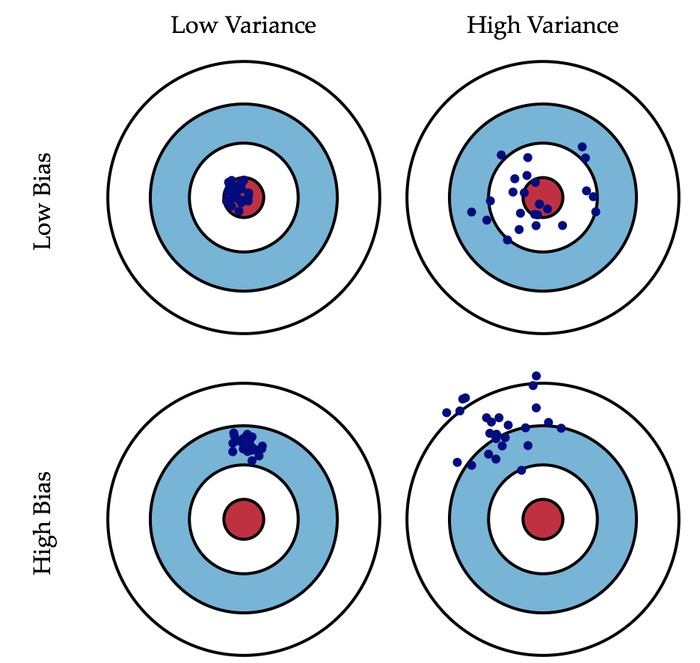
上图可以对照开枪问题来理解,我们可以看到,Low Variance的这一列数据的集中,稳定性很好,方差很小 ;而High Variance这一列的数据比较分散,说明稳定性不好,也就是方差很大。对于Low Bias这一行,数据大都聚集在中心红点,说明偏差比较小;而对于High Bias这一行,数据与中心红点有一定的偏离,说明偏差比较大。图的右上角代表了过拟合。
四、交叉验证的产生
人们发现用同一数据集,既进行训练,又进行模型误差估计,对误差估计的很不准确,这就是所说的模型误差估计的乐观性。为了克服这个问题,提出了交叉验证。基本思想是将数据分为两部分,一部分数据用来模型的训练,称为训练集;另外一部分用于测试模型的误差,称为验证集。由于两部分数据不同,估计得到的泛化误差更接近真实的模型表现。数据量足够的情况下,可以很好的估计真实的泛化误差。但是实际中,往往只有有限的数据可用,需要对数据进行重用,从而对数据进行多次切分,得到好的估计。(参考听风1996 简书)
五、K-交叉验证的原理
K-交叉验证是指将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2.。而K-CV 的实验共需要建立 k 个models,并计算 k 次 test sets 的平均辨识率。在实作上,k 要够大才能使各回合中的 训练样本数够多,一般而言 k=10 (作为一个经验参数)算是相当足够了。
举个栗子:假设将数据集D分为K个包(这里K = 6),每次将其中一个包作为验证集,其他K-1个包作为训练集

六、 Bias、Variance和K-交叉验证关系
K-交叉验证常用来确定不同类型的模型哪一种更好,为了减少数据划分对模型产生的影响 ,最终选取的模型类型是通过K次建模的误差平均值最小的模型。当k较大时,经过更多次数的平均可以学习得到更符合真实数据分布的模型,Bias就小了,但是这样一来模型就更加拟合训练数据集,再去测试集上预测的时候预测误差的期望值就变大了,从而Variance就大了;反之,k较小时模型不会过度拟合训练数据,从而Bias较大,但是正因为没有过度拟合训练数据,Variance也较小。(参考听风1996 简书)
七、K-交叉验证简单代码实现
假设有数据 X = ([1,2], [3,4], [1,3], [3,5]),Y = ([1, 2, 3, 4]),这里使用的是从sklearn库中引入的KFold
##一个简单的4折交叉验证
from sklearn.model_selection import KFold
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[1,2], [3,4], [1,3], [3,5]])
Y = np.array([1, 2, 3, 4])
KF = KFold(n_splits = 4) #建立4折交叉验证方法 查一下KFold函数的参数
for train_index, test_index in KF.split(X):
print("TRAIN", train_index, "TEST", test_index)
X_train, X_test = X[train_index], Y[test_index]
Y_train, Y_test = Y[train_index], Y[test_index]
print("对于数据X训练数据:", X_train)
print("对于数据X测试数据:", X_test)
print("对于数据Y训练数据:", Y_train)
print("对于数据Y测试数据:", Y_test)输出结果:
TRAIN [1 2 3] TEST [0]
对于数据X训练数据: [[3 4]
[1 3]
[3 5]]
对于数据X测试数据: [1]
对于数据Y训练数据: [2 3 4]
对于数据Y测试数据: [1]
TRAIN [0 2 3] TEST [1]
对于数据X训练数据: [[1 2]
[1 3]
[3 5]]
对于数据X测试数据: [2]
对于数据Y训练数据: [1 3 4]
对于数据Y测试数据: [2]
TRAIN [0 1 3] TEST [2]
对于数据X训练数据: [[1 2]
[3 4]
[3 5]]
对于数据X测试数据: [3]
对于数据Y训练数据: [1 2 4]
对于数据Y测试数据: [3]
TRAIN [0 1 2] TEST [3]
对于数据X训练数据: [[1 2]
[3 4]
[1 3]]
对于数据X测试数据: [4]
对于数据Y训练数据: [1 2 3]
对于数据Y测试数据: [4]
八、代码解释
1、KFold(n_splits = 4) 2、KF.split(X)
n_splits:表示划分几等份
shuffle:在每次划分时,是否进行洗牌,①若为Falses时,其效果等同于random_state等于整数,每次划分的结果相同,②若为True时,每次划分的结果都不一样,表示经过洗牌,随机取样的
random_state:随机种子数
split():将数据集划分成训练集和测试集,返回索引生成器
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, random_state=43, shuffle=True)
a=[[1,2],[3,4],[5,6],[7,8],[9,10]]
b=[1,2,3,4,5]
for i,j in kf.split(a,b):
print(i,j)
[0 1 2 4] [3]
[0 1 3 4] [2]
[0 2 3 4] [1]
[1 2 3 4] [0]
[0 1 2 3] [4]以上是对K-交叉验证的总结,如果有什么理解不到位的地方还请指点改正。