1.哈希表(散列)-Google 上机题
1)看一个实际需求,Google 公司的一个上机题:
2)有一个公司,当有新的员工来报到时,要求将该员工的信息加入(id,性别,年龄,住址…),当输入该员工的id时,要求查
找到该员工的所有信息。
3)要求:不适用数据库,尽量节省内存,速度越快越好=> 哈希表(散列)
2.哈希表的基本介绍
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值
映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。

Google 公司的一个上机题:
有一个公司,当有新的员工来报到时,要求将该员工的信息加入(id,性别,年龄,住址…),当输入该员工的id时,要求查
找到该员工的所有信息。
要求:
1)不使用数据库,速度越快越好=>哈希表(散列)
2)添加时,保证按照id从低到高插入[课后思考:如果id不是从低到高插入,但要求各条链表仍是从低到高,怎么解决?]
3)使用链表来实现哈希表,该链表不带表头[即:链表的第一个结点就存放雇员信息]
4)思路分析并画出示意图
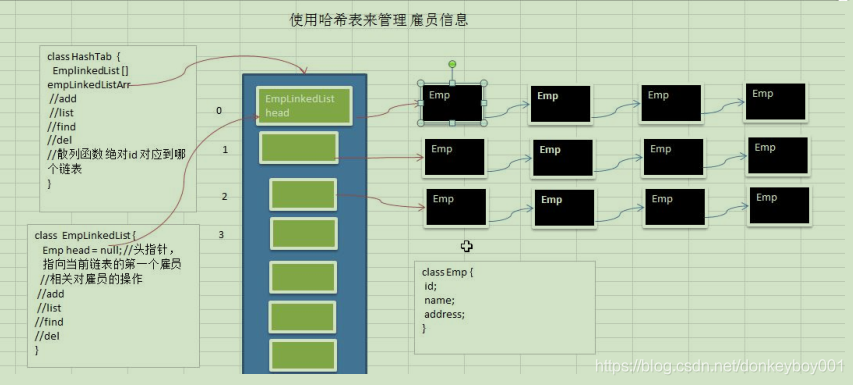
5)代码实现
package com.example.demo.hashtable;
import java.util.Scanner;
public class HashTableDemo {
public static void main(String[] args) {
//创建哈希表
HashTable hashTable = new HashTable(7);
String key = "";
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.println("add: 添加雇员");
System.out.println("list: 显示雇员");
System.out.println("find: 查找雇员");
System.out.println("exit: 退出系统");
key = scanner.next();
switch (key) {
case "add":
System.out.println("输入id");
int id = scanner.nextInt();
System.out.println("输入名字");
String name = scanner.next();
//创建 雇员
Emp emp = new Emp(id, name);
hashTable.add(emp);
break;
case "list":
hashTable.list();
break;
case "find":
System.out.println("请输入要查找的id");
id = scanner.nextInt();
hashTable.findEmpById(id);
break;
case "exit":
scanner.close();
System.exit(0);
default:
break;
}
}
}
}
//创建 HashTable 来存储链表
class HashTable {
private EmpLinkedList[] empLinkedListArray;
private int size; //表示有多少条链表
public HashTable(int size) {
this.size = size;
//初始化 empLinkedListArray
empLinkedListArray = new EmpLinkedList[size];
//分别初始化每个链表
for (int i = 0; i < size; i++) {
empLinkedListArray[i] = new EmpLinkedList();
}
}
//添加雇员
public void add(Emp emp) {
//根据员工的id,得到该员工应当添加到哪条链表
int empLinkedListNO = hashFun(emp.id);
//将emp 添加到对应的链表中
empLinkedListArray[empLinkedListNO].add(emp);
}
//遍历所有的链表,遍历 hashtable
public void list() {
for (int i = 0; i < size; i++) {
empLinkedListArray[i].list(i);
}
}
//根据输入的id,查找雇员
public void findEmpById(int id) {
//使用散列函数确定这个元素所在的链表
int empLinkedListNO = hashFun(id);
Emp emp = empLinkedListArray[empLinkedListNO].findEmpById(id);
if (emp != null) { //找到
System.out.printf("在第%d 条链表中找到 雇员 id=%d\n", (empLinkedListNO + 1), id);
} else {
System.out.println("在哈希表中,没有找到该雇员~");
}
}
public int hashFun(int id) {
return id % size;
}
}
//表示一个雇员
class Emp {
public int id;
public String name;
public Emp next; //next 默认为null
public Emp(int id, String name) {
super();
this.id = id;
this.name = name;
}
}
//创建EmpLinkedList,表示链表
class EmpLinkedList {
//头指针,执行第一个Emp,因此我们这个链表的head 是直接指向第一个Emp
private Emp head; //默认 null
//添加雇员到链表
//说明
//1.假定,当添加雇员时,id是自增长,即id的分配总是从小到大
// 因此我们将该雇员直接加入到本链表的最后即可
public void add(Emp emp) {
//当添加第一个雇员时
if (head == null) {
head = emp;
return;
}
//如果不是添加第一个雇员那么需要辅助指针来辅助定位到最后一个元素
Emp curEmp = head;
while (true) {
if (curEmp.next == null) { //找到最后一个元素
break;
}
curEmp = curEmp.next; //后移
}
curEmp.next = emp; //将Emp 添加到链表上
}
//遍历链表的雇员信息
public void list(int no) { //no 表示链表放在hash table中索引位置
if (head == null) { //说明链表为空
System.out.println("第 " + (no + 1) + "链表为空");
return;
}
System.out.println("第 " + (no + 1) + "链表的信息为");
Emp curEmp = head; //辅助指针
while (true) {
System.out.printf("=>id=%d name=%s\t", curEmp.id, curEmp.name);
if (curEmp.next == null) { //说明curEmp 已经是最后节点
break;
}
curEmp = curEmp.next; //后移
}
System.out.println();
}
//根据id 查找雇员
//如果查找到,就返回Emp,如果没有找到,就返回null
public Emp findEmpById(int id) {
//判断链表是否为空
if (head == null) {
System.out.println("链表为空");
return null;
}
//辅助指针
Emp curEmp = head;
while (true) {
if (curEmp.id == id) { //找到
break; //这时 curEmp 就指向要查找的雇员
}
//退出
if (curEmp.next == null) { //已经到达链表末尾节点
curEmp = null;
break;
}
curEmp = curEmp.next;
}
return curEmp;
}
}