1.Prometheus是什么?
Prometheus(下文称Prom) 是由 SoundCloud 开源监控告警解决方案,与Kubernetes同属CNCF,它已经成为炙手可热的Kubernetes生态圈中的核心监控系统,越来越多的项目(如Kubernetes和etcd等 )都加入了丰富的Prometheus原生支持,
Prom提供了通用的数据模型和便捷的数据采集、存储和查询接口,同时基于Go实现也大大降低了服务端的运维成本,可以借助一些优秀的图形化工具(如Grafana)可以实现友好的图形化和报警。
1.1单词理解
- metric—指标(名字)
- targes–数据源
- alert–警报
- exporter–负责数据汇报和信息收集的程序
- quantile–分位数
- bucket–块
- Summary–概略图
- Histogram–直方图
- labels–标签
1.2主要特点:
- 多维数据模型【时序由 metric(指标) 名字和 k/v 的 labels 构成】。
- 灵活的查询语句(PromQL)。
- 无依赖存储,支持 local 和 remote 不同模型。
- 采用 http 协议,使用 pull 模式拉取数据,简单易懂。
- 监控目标,可以采用服务发现或静态配置的方式。
- 支持多种统计数据模型,图形化友好。
1.3核心组件:
- Prometheus Server:主要用于抓取数据和存储时序数据,另外还提供API供外界查询和 Alert Rule 配置管理。
- client libraries:用于对接 Prometheus Server, 可以查询和上报数据。
- push gateway :允许短暂和批量作业将其指标暴露给普罗米修斯。由于这些类型的作业可能存在时间不足以被删除,因此他们可以将其指标推送到Pushgateway。然后,Pushgateway将这些指标暴露给普罗米修斯,主要用于业务数据汇报等。
- 各种汇报数据的 exporters :例如汇报机器数据的 node_exporter, 汇报 MongoDB 信息的 MongoDB * exporter 等等。
- 用于告警通知管理的 alertmanager 。
1.4基础架构图
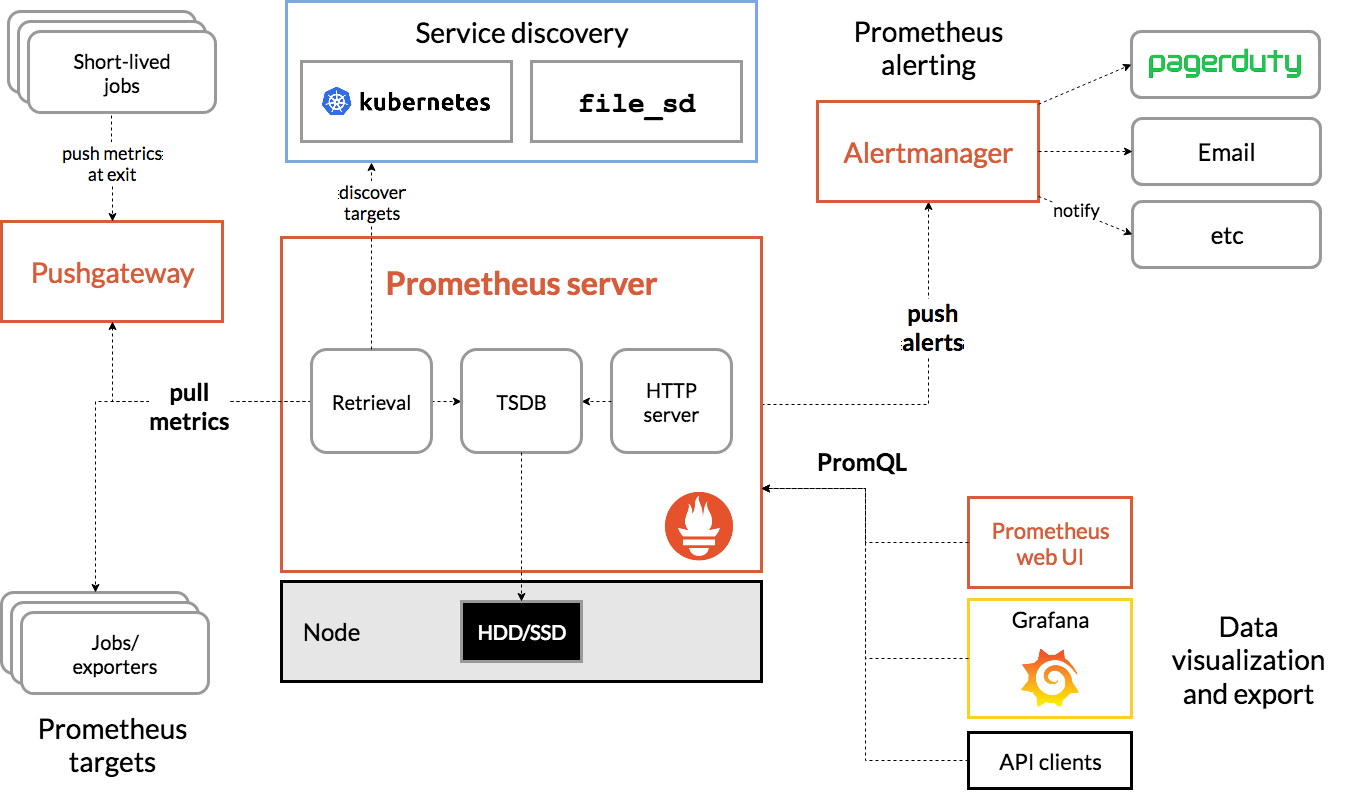
1.5模块逻辑解析:
- Prometheus server :定期从静态配置的 Prometheus targets (数据源)或者服务发现的 targets (数据源)拉取数据。
- Retrieval:检索拉去到的数据分发给TSDB进行存储。
- HTTP server:用于接受外界的HTTP请求。
- TSDB:当新拉取的数据大于配置内存缓存区的时候,Prometheus会将数据持久化到磁盘(HHD/SSD)(如果使用 remote storage 将持久化到云端)。
- Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert(警告) 推送(pushalerts)到配置的 Alertmanager(警告管理器)。
- Alertmanager :收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
- API client,Grafana:API client通过使用promQL查询数据,Grafana用于聚合数据将数据可视化。
- Web UI: Prometheus的web接口,可用于简单可视化,及语句执行或者服务状态监控。
- short-lived jobs:存在时间不足以被删除的短暂和批量作业
- pushgateway:shaort-lived jobs 在推出时将数据推给pushgateway,主要用于业务数据汇报等。
注意:
- Prometheus 的数据是基于时序的 float64 的值,如果你的数据值有更多类型,无法满足。
- Prometheus 不适合做审计计费,因为它的数据是按一定时间采集的,关注的更多是系统的运行瞬时状态以及趋势,即使有少量数据没有采集也能容忍,但是审计计费需要记录每个请求,并且数据长期存储,这个 Prometheus 无法满足,可能需要采用专门的审计系统。
2.prometheus的数据模型
Prometheus 存储的是时序数据, 即按照相同时序(相同的名字和标签),以时间维度存储连续的数据的集合。
2.1时序索引
-
时序(time series) 是由指标名字(Metric),以及一组 key/value 标签定义的,具有相同的名字以及标签属于相同时序。
-
时序的名字由 ASCII 字符,数字,下划线,以及冒号组成,它必须满足正则表达式
[a-zA-Z_:][a-zA-Z0-9_:]*,
其名字应该具有语义化,一般表示一个可以度量的指标,例如: http_requests_total, 可以表示 http 请求的总数。
-
时序的标签可以使 Prometheus 的数据更加丰富,能够区分具体不同的实例,例如:
http_requests_total{method="POST"} 可以表示所有 http 中的 POST 请求。 -
标签名称由 ASCII 字符,数字,以及下划线组成, 其中 __ 开头属于 Prometheus 保留,标签的值可以是任何 Unicode 字符,支持中文。
2.2时序样本
- 按照某个时序以时间维度采集的数据,称之为样本,其值包含:
- 一个 float64 值
- 一个毫秒级的 unix 时间戳
2.3格式
-
Prometheus 时序格式与 OpenTSDB 相似:
<metric name>{<label name>=<label value>, ...}
其中包含时序名字以及时序的标签。
2.4时序 4 种类型
Prometheus 时序数据分为 Counter(变化的增减量), Gauge(瞬时值), Histogram(采样并统计), Summary(采样结果) 四种类型。
- Counter
Counter 表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量、错误总数等。
例如 Prometheus server 中 http_requests_total, 表示 Prometheus 处理的 http 请求总数,我们可以使用 delta, 很容易得到任意区间数据的增量,这个会在 PromQL 一节中细讲。
- Gauge
Gauge 表示搜集的数据是一个瞬时的值,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
例如 Prometheus server 中 go_goroutines, 表示 Prometheus 当前 goroutines 的数量。
- Histogram
主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),
并能够对其指定区间以及总数进行统计,通常它采集的数据展示为直方图。
Histogram 由 <basename>_bucket{le="<upper inclusive bound>"},
<basename>_bucket{le="+Inf"}, <basename>_sum,<basename>_count组成,
例如 Prometheus server中prometheus_local_storage_series_chunks_persisted,
表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数。
- Summary
主要用于表示一段时间内数据采样结果(通常是请求持续时间或响
应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。
Summary 和 Histogram 类似,由 <basename>{quantile="<φ>"},<basename>_sum,
<basename>_count 组成,
例如 Prometheus server 中 prometheus_target_interval_length_seconds。
-
Histogram vs Summary
都包含 <basename>_sum,<basename>_count Histogram 需要通过 <basename>_bucket 计算 quantile, 而 Summary 直接存储了 quantile 的值。
2.5实例和作业
Prometheus 中,将任意一个独立的数据源(target)称之为实例(instance)。包含相同类型的实例的集合称之为作业(job)。
####2.6自生成标签和时序
Prometheus 在采集数据的同时,会自动在时序的基础上添加标签,作为数据源(target)的标识,以便区分:
job: The configured job name that the target belongs to.
作业:设定该作业名属于哪个数据源
instance: The <host>:<port> part of the target's URL that was scraped.
例如:这个域名端口号是该数据源的url被剪切出的一部分
如果其中任一标签已经在此前采集的数据中存在,那么将会根据 honor_labels 设置选项来决定新标签。
-
对每一个实例而言,Prometheus 按照以下时序来存储所采集的数据样本:
* up{job="<job-name>", instance="<instance-id>"}: 1 表示该实例正常工作 * up{job="<job-name>", instance="<instance-id>"}: 0 表示该实例故障 * scrape_duration_seconds{job="<job-name>", instance="<instance-id>"} 表示拉取数据的时间间隔 * scrape_samples_scraped{job="<job-name>", instance="<instance-id>"} 表示从该数据源获取的样本数 * scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"} 表示采用重定义标签(relabeling)操作后仍然剩余的样本数
其中 up 时序可以有效应用于监控该实例是否正常工作。
3.PromQL 基本使用
-
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化以及rule 告警中都会使用到它。
-
在查询语句中,字符串往往作为查询条件labels(标签)的值,和Golang 字符串语法一致,可以使用 “”, ‘’, 或者 “ 。也可以使用正数或浮点数,
3.1查询结果类型
PromQL 查询结果主要有 3 种类型:
-
瞬时数据 (Instant vector): 包含一组时序,每个时序只有一个点,例如:
http_requests_total -
区间数据 (Range vector): 包含一组时序,每个时序有多个点,例如:
http_requests_total[5m] -
纯量数据 (Scalar): 纯量只有一个数字,没有时序,例如:
count(http_requests_total)
3.2查询条件
Prometheus 存储的是时序数据,而它的时序是由名字和一组标签构成的,其实名字也可以写出标签的形式,
例如 http_requests_total 等价于 {name="http_requests_total"}。
一个简单的查询相当于是对各种标签的筛选,
http_requests_total{code="200"}
// 表示查询名字为 http_requests_total,code 为 "200" 的数据
查询条件支持正则匹配,
3.2.1操作符
Prometheus 查询语句中,支持常见的各种表达式操作符。例如:
- 算术运算符:+,-,*,/,%,
- 比较运算符:==,!=,>,<,>=,<=
- 逻辑运算符:and,or,unless
- 聚合运算符: sum,min,max,avg,stddev,stdvar,count,count_values,bottomk,topk,quantile
注意,和四则运算类型,Prometheus 的运算符也有优先级,它们遵从(^)> (*, /, %) > (+, -) > (==, !=, <=, <, >=, >) > (and, unless) > (or) 的原则。
3.2.2内置函数
Prometheus 内置不少函数,方便查询以及数据格式化,详情参考内置函数
3.2.3与MySql对比
经过与MySql对比发现,常用查询和统计方面,PromQL 比 MySQL 简单和丰富很多,而且查询性能也高不少。
4.Exporter
在 Prometheus 中负责数据汇报的程序统一叫做 Exporter, 而不同的 Exporter 负责不同的业务。 它们具有统一命名格式,即
xx_exporter, 例如负责主机信息收集的 node_exporter。
Prometheus 社区已经提供了很多 exporter, 详情请参考这里
4.1文本格式
- Exporter 本质上就是提供 http 请求并将收集的数据,转化为对应的文本格式。
- Exporter 收集的数据转化的文本内容以行 (\n) 为单位,空行将被忽略, 文本内容最后一行为空行。
- 文本内容,如果以 # 开头通常表示注释。
-
以 # HELP 开头表示 metric 帮助说明。
-
以 # TYPE 开头表示定义 metric 类型,包含 counter, gauge, histogram, summary和untyped 类型。
-
其他表示一般注释,供阅读使用,将被 Prometheus 忽略。
-
内容如果不以 # 开头,表示采样数据。它通常紧挨着类型定义行,满足以下格式:
metric_name [{label_name = "label_value",label_name ="label_value"}] value [ timestamp ]
-
这里有一个完整的例子
# HELP http_requests_total The total number of HTTP requests.
# TYPE http_requests_total counter
http_requests_total{method="post",code="200"} 1027 1395066363000
http_requests_total{method="post",code="400"} 3 1395066363000
# Escaping in label values:
msdos_file_access_time_seconds{path="C:\\DIR\\FILE.TXT",error="Cannot find file:\n\"FILE.TXT\""} 1.458255915e9
# Minimalistic line:
metric_without_timestamp_and_labels 12.47
# A weird metric from before the epoch:
something_weird{problem="division by zero"} +Inf -3982045
# A histogram, which has a pretty complex representation in the text format:
# HELP http_request_duration_seconds A histogram of the request duration.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.05"} 24054
http_request_duration_seconds_bucket{le="0.1"} 33444
http_request_duration_seconds_bucket{le="0.2"} 100392
http_request_duration_seconds_bucket{le="0.5"} 129389
http_request_duration_seconds_bucket{le="1"} 133988
http_request_duration_seconds_bucket{le="+Inf"} 144320
http_request_duration_seconds_sum 53423
http_request_duration_seconds_count 144320
# Finally a summary, which has a complex representation, too:
# HELP rpc_duration_seconds A summary of the RPC duration in seconds.
# TYPE rpc_duration_seconds summary
rpc_duration_seconds{quantile="0.01"} 3102
rpc_duration_seconds{quantile="0.05"} 3272
rpc_duration_seconds{quantile="0.5"} 4773
rpc_duration_seconds{quantile="0.9"} 9001
rpc_duration_seconds{quantile="0.99"} 76656
rpc_duration_seconds_sum 1.7560473e+07
rpc_duration_seconds_count 2693
需要特别注意的是,假设采样数据 metric 叫做 x, 如果 x 是 histogram 或 summary 类型必需满足以下条件:
- 采样数据的总和应表示为 x_sum。
- 采样数据的总量应表示为 x_count。
- summary 类型的采样数据的 quantile 应表示为 x{quantile=“y”}。
- histogram 类型的采样分区统计数据将表示为 x_bucket{le=“y”}。、
- histogram 类型的采样必须包含 x_bucket{le=“+Inf”}, 它的值等于 x_count 的值。
- summary 和 historam 中 quantile 和 le 必需按从小到大顺序排列。
4.2 Node_Exporter
Node_Exporter主要用于 *NIX 系统监控, 用 Golang 编写。
4.2.1Node_Exporter的安装与启动
在下载页面中下载相应的二进制安装包。下载并解压成功后,我们可以使用 ./node_exporter -h 查看运行选项,./node_exporter 运行 Node Exporter, 如果看到类似输出,表示启动成功。
INFO[0000] Starting node_exporter (version=0.14.0, branch=master, revision=840ba5dcc71a084a3bc63cb6063003c1f94435a6) source="node_exporter.go:140"
INFO[0000] Build context (go=go1.7.5, user=root@bb6d0678e7f3, date=20170321-12:13:32) source="node_exporter.go:141"
INFO[0000] No directory specified, see --collector.textfile.directory source="textfile.go:57"
INFO[0000] Enabled collectors: source="node_exporter.go:160"
.....
INFO[0000] Listening on :9100 source="node_exporter.go:186"
4.2.2 数据存储
我们可以利用 Prometheus 的static_configs来拉取 node_exporter 的数据。
打开 prometheus.yml 文件, 在 scrape_configs 中添加如下配置:
- job_name: "node"
static_configs:
- targets: ["127.0.0.1:9100"]
重启加载配置,然后到 Prometheus Console 查询,你会看到 node_exporter 的数据。
4.2.3Node Exporter 常用查询语句
收集到 node_exporter 的数据后,我们可以使用 PromQL 进行一些业务查询和监控,下面是一些比较常见的查询。
注意:以下查询均以单个节点作为例子,如果大家想查看所有节点,将 instance=“xxx” 去掉即可。
-
CPU 使用率
100 - (avg by (instance) (irate(node_cpu{instance="xxx", mode="idle"}[5m])) * 100) -
CPU 各 mode 占比率
avg by (instance, mode) (irate(node_cpu{instance="xxx"}[5m])) * 100 -
机器平均负载
node_load1{instance="xxx"} // 1分钟负载 node_load5{instance="xxx"} // 5分钟负载 node_load15{instance="xxx"} // 15分钟负载 -
内存使用率
100 - ((node_memory_MemFree{instance="xxx"}+node_memory_Cached{instance="xxx"}+node_memory_Buffers{instance="xxx"})/node_memory_MemTotal) * 100 -
磁盘使用率
100 - node_filesystem_free{instance="xxx",fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} / node_filesystem_size{instance="xxx",fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} * 100 -
网络 IO
// 上行带宽 sum by (instance) (irate(node_network_receive_bytes{instance="xxx",device!~"bond.*?|lo"}[5m])/128) // 下行带宽 sum by (instance) (irate(node_network_transmit_bytes{instance="xxx",device!~"bond.*?|lo"}[5m])/128) -
网卡出/入包
// 入包量 sum by (instance) (rate(node_network_receive_bytes{instance="xxx",device!="lo"}[5m])) // 出包量 sum by (instance) (rate(node_network_transmit_bytes{instance="xxx",device!="lo"}[5m]))
4.3 总结
- node exporter是混合态的,不同的模块的处理方式也不尽相同。对于mdadm,我们必须手动解析文件,并获取我们想要的度量指标,所以我们可以在需要的时候获取度量指标。对于meminfo,不同的内核版本命名可能会有变化,所以我们需要创建有效的度量指标,以适应不同内核版本的内存使用情况。
- 当导出器和应用程序一起工作时,你的导出器目标是尽量不要让用户使用自定义配置,而是尽可能地使用默认配置就ok了。你也可以给你的导出器提供过滤度量指标的支持,因为有些度量指标是非常多且琐碎,也有些需要花费很大的代价才能获取度量指标,这些都可以进行过滤(例如:HAProxy exporter允许过滤每个服务器的统计信息),类似地,默认配置可以直接禁用获取代价比较的度量指标。
- 度量指标名称永远不要程序化的生成,除非在编写自定义收集器或者导出器时。
- 应用程序的度量指标名称应该以exporter名称为前缀,如haproxy_up。
- 为了把度量指标推送到检测系统中,一个给定的度量指标应该在一个指定的文件中存在。根据导出器和收集器,一个度量指标名称应该应用在一个子系统中
- 度量指标名称不应该包括他们导出的labels(如:by_type)如果标签聚在一起,就没有意义。
- 暴露的度量指标不应包含冒号,这些用于聚合时可供用户使用。度量指标名称只有符合正则表达式[a-zA-Z0-9:]是有效的,任何其他字符串都需要被改成””下划线
- _sum, _count, _bucket, 和_total用于Summaries,Histogram和Counters的后缀。如果你正好要使用这些统计则可以使用这些后缀,否则避免使用这些后缀。
- 如果你正在使用COUNTER类型,则应该使用_total作为度量指标的后缀。
- 当你统计请求的成功数量和失败数量时,最佳方法是暴露两个度量指标,一个是总的请求数,另一个度量指标是失败的请求度量指标。这使得计算失败比率变得很容易。不要使用带有failed/success的标签。类似于缓存中的hit/miss,有一个总的度量指标和另一个hits的度量指标是更好的。
- 避免把type做为标签名称,它太通用化,而且无意义。你也应该试着尽可能地避免与目标标签冲突,例如:region, zone, cluster, availability, az, datacenter, dc, owner, customer, stage, environment和env, 尽管这是应用程序调用的东西,但是最好不要通过重命名造成混乱。
- 标签le对于Histograms有特殊的含义。同样对于Summaries来说,quantile也是如此。避免使用这些标签。
5.配置说明
prometheus的配置文件中比较重要的是prometheus.yml,文件大致内容如下:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
#Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
该配置文件中比较重要的是以下几个部分:
- global:全局的配置,如果后面的任务没有对特定配置项进行覆盖,这里的选项会生效。
- scrape_interval: 拉取 targets 的默认时间间隔。如果太频繁会导致 promethues 压力比较大,如果太久,可能会导致某些关键数据漏掉,推荐根据每个任务的重要性和集群规模分别进行配置。
- scrape_timeout: 拉取一个 target 的超时时间。
- evaluation_interval: 执行 rules 的时间间隔。
- external_labels: 额外的属性,会添加到拉取的数据并存到数据库中。
- scrape__configs:主要用于配置拉取数据节点,每一个拉取配置主要包含以下参数:
- job_name:任务名称
- honor_labels: 用于解决拉取数据标签有冲突,当设置为 true, 以拉取数据为准,否则以服务配置为准
- params:数据拉取访问时带的请求参数
- scrape_interval: 拉取时间间隔
- scrape_timeout: 拉取超时时间
- metrics_path: 拉取节点的 metric 路径
- scheme: 拉取数据访问协议
- sample_limit: 存储的数据标签个数限制,如果超过限制,该数据将被忽略,不入存储;默认值为0,表示没有限制
- relabel_configs: 拉取数据重置标签配置
上述例子中可以配置多中抓取任务,因此是一个列表,这里我们只有一个任务,那就是抓取 promethues 本身的 metrics。配置里面最重要的是 static_configs.targets,表示要抓取任务的 HTTP 地址,默认会在 /metrics url 出进行抓取,比如这里就是 http://localhost:9090/。 这是 prometheus 本身提供的监控数据,可以在浏览器中直接查看。
- 告警配置
通常我们可以使用运行参数 -alertmanager.xxx 来配置 Alertmanager, 但是这样不够灵活,没有办法做到动态更新加载,以及动态定义告警属性。
所以 alerting 配置主要用来解决这个问题,它能够更好的管理 Alertmanager, 主要包含 2 个参数:- alert_relabel_configs: 动态修改 alert 属性的规则配置。
- alertmanagers: 用于动态发现 Alertmanager 的配置。
6.collector
我们先来看下采集器Collector接口的实现
type Collector interface {
// 用于传递所有可能的指标的定义描述符
// 可以在程序运行期间添加新的描述,收集新的指标信息
// 重复的描述符将被忽略。两个不同的Collector不要设置相同的描述符
Describe(chan<- *Desc)
// Prometheus的注册器调用Collect执行实际的抓取参数的工作,
// 并将收集的数据传递到Channel中返回
// 收集的指标信息来自于Describe中传递,可以并发的执行抓取工作,但是必须要保证线程的安全。
Collect(chan<- Metric)
}
有很多数据类型实现了这个接口
Gauge
type Gauge interface {
Metric
Collector
// Set将标尺设置为任意值。
Set(float64)
//Inc将测量值增加1。
Inc()
// dec将测量值减1
Dec()
// Add adds the given value to the Gauge. (The value can be
// negative, resulting in a decrease of the Gauge.)
Add(float64)
// Sub subtracts the given value from the Gauge. (The value can be
// negative, resulting in an increase of the Gauge.)
Sub(float64)
}
Counter
type Counter interface {
Metric
Collector
// Set is used to set the Counter to an arbitrary value. It is only used
// if you have to transfer a value from an external counter into this
// Prometheus metric. Do not use it for regular handling of a
// Prometheus counter (as it can be used to break the contract of
// monotonically increasing values).
//
// Deprecated: Use NewConstMetric to create a counter for an external
// value. A Counter should never be set.
Set(float64)
// Inc increments the counter by 1.
Inc()
// Add adds the given value to the counter. It panics if the value is <
// 0.
Add(float64)
}
###Histogram
type Histogram interface {
Metric
Collector
// Observe adds a single observation to the histogram.
Observe(float64)
}
###Summary
type Summary interface {
Metric
Collector
// Observe adds a single observation to the summary.
Observe(float64)
}
…
…
.
…
…
详细过程参见collector源码解析