磁盘文件
通过前一篇文章Linux——系统文件I/O,我们知道了如何对加载在内存中的文件进行读写等操作,并了解了其内在的原理。同时我们也应该清楚,并不是所有的文件都会被加载入内存,而没有被加载入内存的文件,就被存放在磁盘中,称为磁盘文件。现在,就让我们一起来学习磁盘文件的相关知识
本片思维导图:
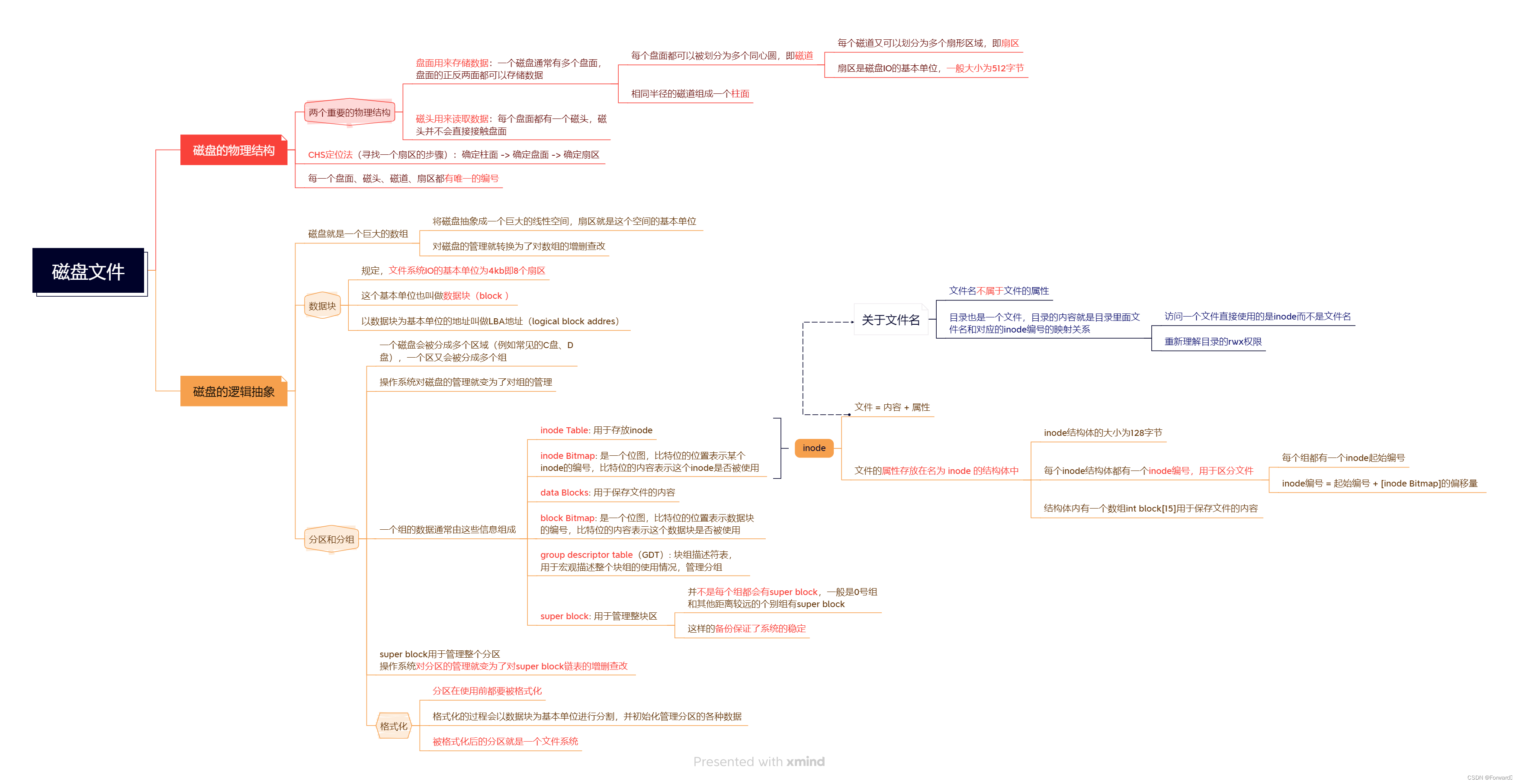 注:本章思维导图对应的
注:本章思维导图对应的.xmind和.png文件都已同步导入至资源,供免费查阅
1. 磁盘的物理结构

1.1 两个重要的结构

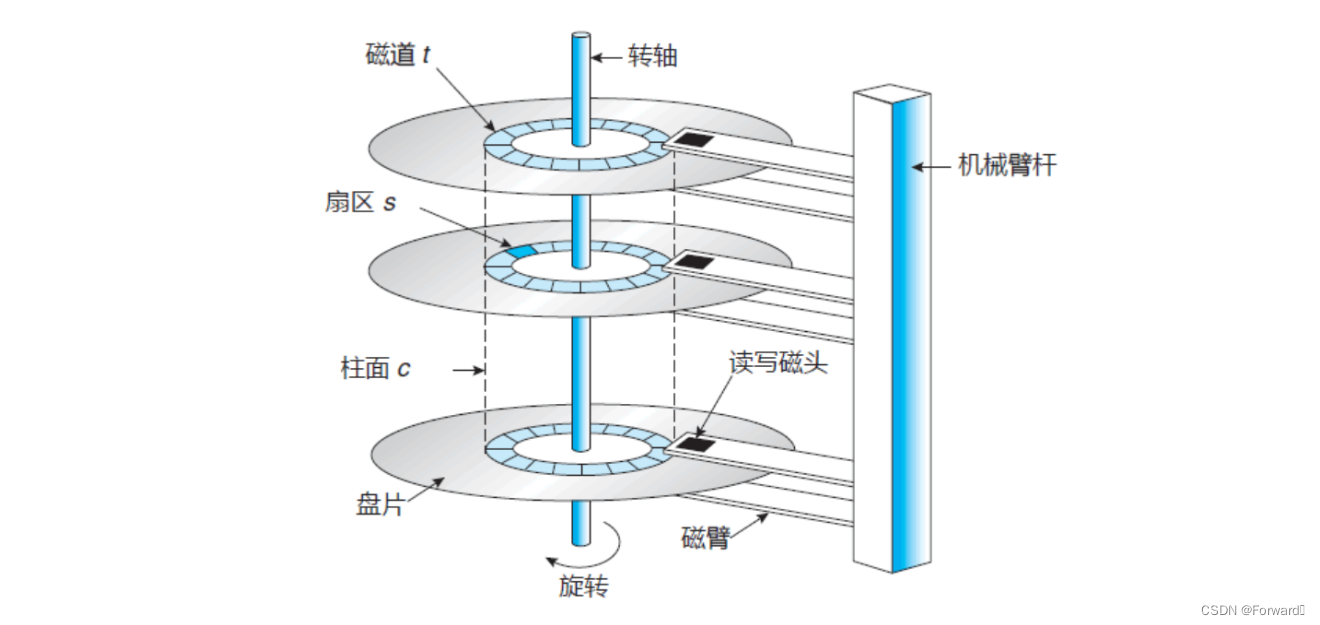
磁盘的两个重要的物理结构为盘面和磁头:
盘面:
- 盘面用来存放数据
- 盘面有正反两面,两面都可以存储数据;一个磁盘可能有多个盘面;每一个盘面都有唯一的编号
磁道:
- 每个盘面都可以被划分为多个同心圆,每个同心圆就叫做一个磁道。每个磁道都有唯一的编号
- 相同半径的磁道组成的柱状结构就叫做
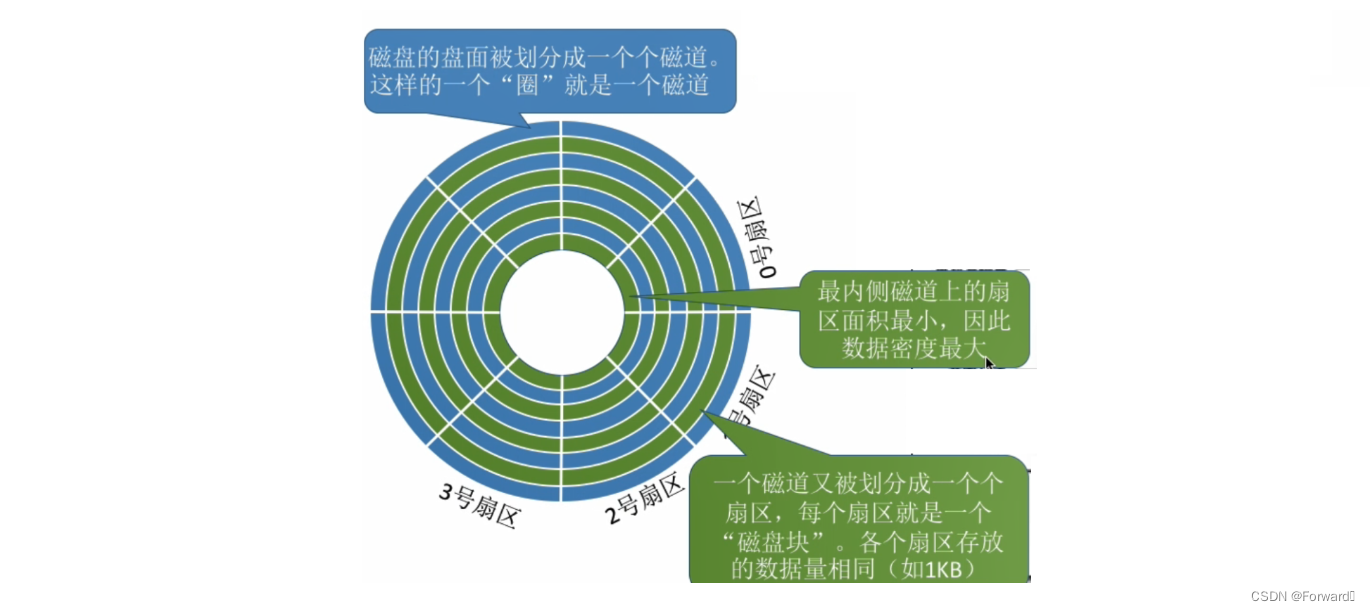
柱面扇区:
- 每一个磁道可以被划分为多个扇形区域,这些区域叫做
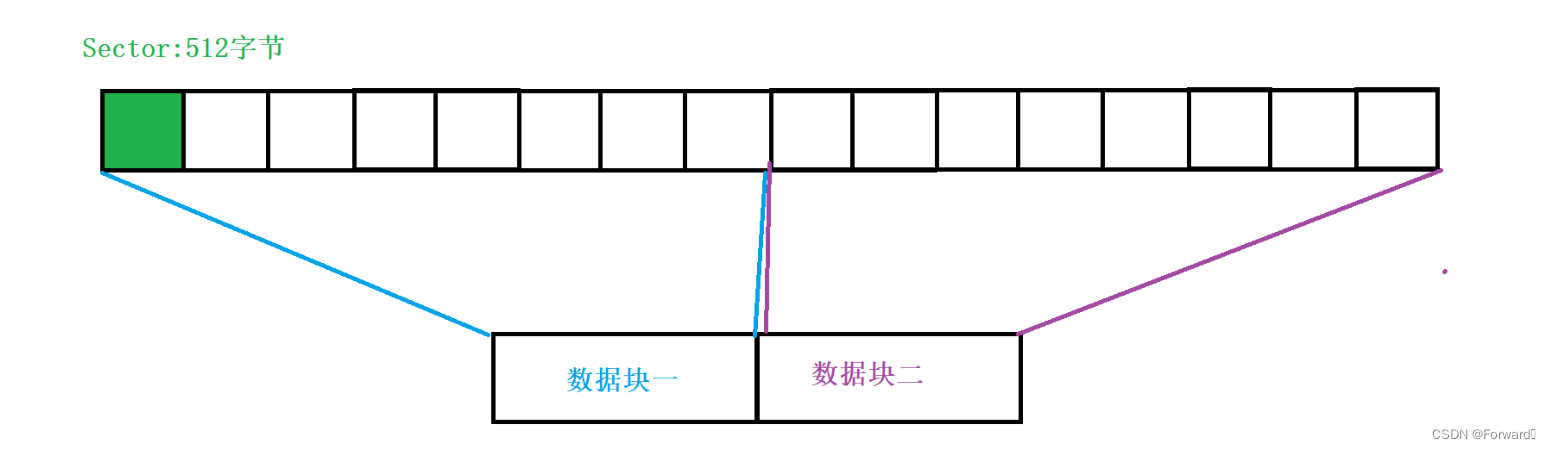
扇区。每个扇区都有唯一的编号- 扇区的一般大小为512字节
- 扇区是磁盘IO的基本单位(例如,如果要改变磁盘中的一个字节,那么必须要将包含这个字节的整个扇区都读入内存,而不能只读入这个字节)
磁头:
- 每个盘面都有一个磁头,磁头悬浮在盘面的上方,并不会与盘面接触
- 每个磁头都有唯一的编号
- 所有磁头都固定在一个磁头臂上,可以共同向盘面的圆心前进后退,从而读取指定的柱面
1.2 CHS定位法
如何定位一个指定的扇区?我们可以通过这样的步骤:
首先,通过磁头的移动来找到扇区位于的柱面;之后,确定所在的盘面(磁头所指的盘面);最后确定确定盘面确定磁道上的扇区
即:确定柱面(磁道)(Cylinder)> 确定磁头(Head) -> 确定扇区(Sector);
这就是所谓的CHS定位法
既然文件存储在磁盘中,那么说到底它也就占用了数个扇区,因此我们就可以通过对文件占用的扇区进行记录,从而将对文件的查找转换为利用CHS定位法对文件所占用扇区进行查找
2. 磁盘的逻辑抽象
2.1 磁盘 -> 线性空间

我们可以来回忆一下以前听英语听力时用到的磁带,磁带盒里的磁带存储着数据,且是一个圆盘状,我们可以将其和磁盘的盘面类比。如果我们将磁带盒里的磁带都抽出来,那么它就成了数十米的条带。
类似的,我们也可以将磁盘作类似的抽象:将盘面的也像磁带一样展开,这样一个盘面也就成了一个线性的空间,而磁盘就是多个线性空间的组合,也就是一个巨大的线性空间,而这个空间的基本单位就是扇区
可以做出总结:磁盘实际上就是一个巨大的数组,数据的每个下标就是一个扇区
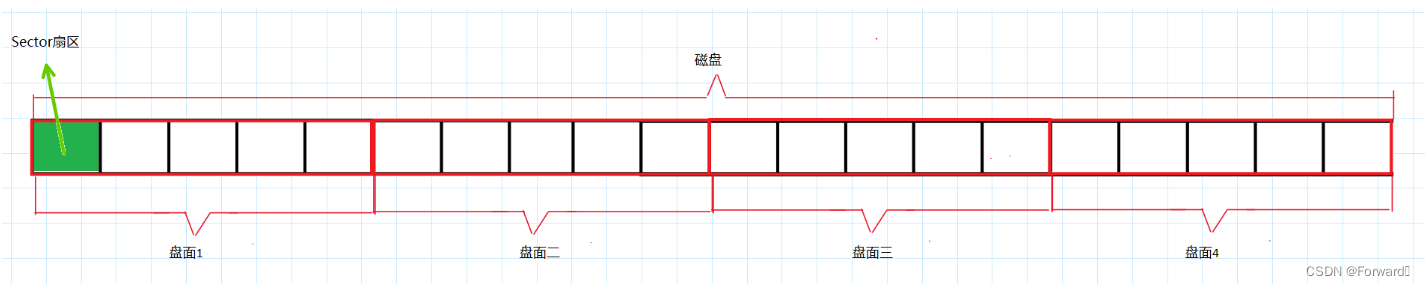
从而,我们对磁盘文件的管理就转换成了对数组的增删查改
既然扇区是这块线性空间的基本单位,那么空间的每个一下标就对应着一个扇区。我们在前面提到过用CHS定位法找到扇区对应物理结构的位置,同样,我们也需要通过一个扇区编号这种线性地址来确定扇区所在的位置:
我们可以来举一个例子:
假设一块磁盘有800GB,有4块盘面,那么每块盘面就有200GB,为了便于分析,同时假设每个盘面有100个磁道,且这些磁道有相同数量的扇区,则每块盘面就有
419,430,400个扇区,每个磁道就有419,430,4个扇区:
现有一个扇区编号为
index那么,他所在的盘面为
index / 盘面有的扇区个数,同时可以得到他在这块盘面的偏移量为tmp = index % 盘面有的扇区个数通过偏移量
tmp,就可以得出他所在的磁道tmp / 磁道有的扇区个数,同时也就可以得到他在这个磁道上的偏移量tmp % 磁道有的扇区个数从而也就得到了某个扇区在磁盘的具体位置

通过上面的方法,我们就可以将一个线性地址转换为CHS地址
2.2 数据块

上面我们提到,磁盘IO的基本单位为一个扇区,也就是514字节,但是文件系统认为,一次之和磁盘交互512字节效率过于低下,因此规定,文件系统IO的基本单位为4Kb,也就是8个扇区。这一基本单位被称为数据块
从而,文件系统访问磁盘中的文件就变成了对特定数据块的访问,而为了找到指定的数据块,就需要用到LBA地址
LBA地址是用来标识数据块位置的,每个LBA地址都表示一个数据块
LBA地址可以通过磁盘控制器转换为CHS地址,从而找到特定的扇区,从而文件系统对磁盘文件进行读取时就避免了
CHS地址这种三维的读取方式,转而使用LBA地址这种一维的方式,进而大大提高了读取效率。
2.3 分区与分组
上面我们将磁盘空间分割成了基本单位为4Kb的线性空间,但是由于磁盘大小往往有几百甚至上千GB,数据块的数量太过庞大
因此操作系统对磁盘空间进行管理时需要采用分治策略:
- 将磁盘空间划分为数个区域(这些区域的大小可以相等也可以不相等),例如常见的电脑C盘、D盘:
- 继续将每一个分区进行分组
- 最后,只要操作系统将每个组管理好了,就可以将每个分区管理好,静儿就可以将整个磁盘空间管理好了

2.3.1 分区的格式化

我们用鼠标右击电脑中的磁盘文件,可以看到“格式化”这一选项:
实际上,通常来说磁盘在出厂时就已经被格式化好了。但是如果我们要对这个磁盘进行分区管理(例如将D盘分200G给E盘),我们就要对分区进行格式化操作:
- 格式化磁盘分区是分区使用前的必要步骤
- 被格式化后的分区就是一个文件系统
- 格式化会清空分区原有的数据,因此要注意重要数据的备份
2.3.1 组(group)的管理
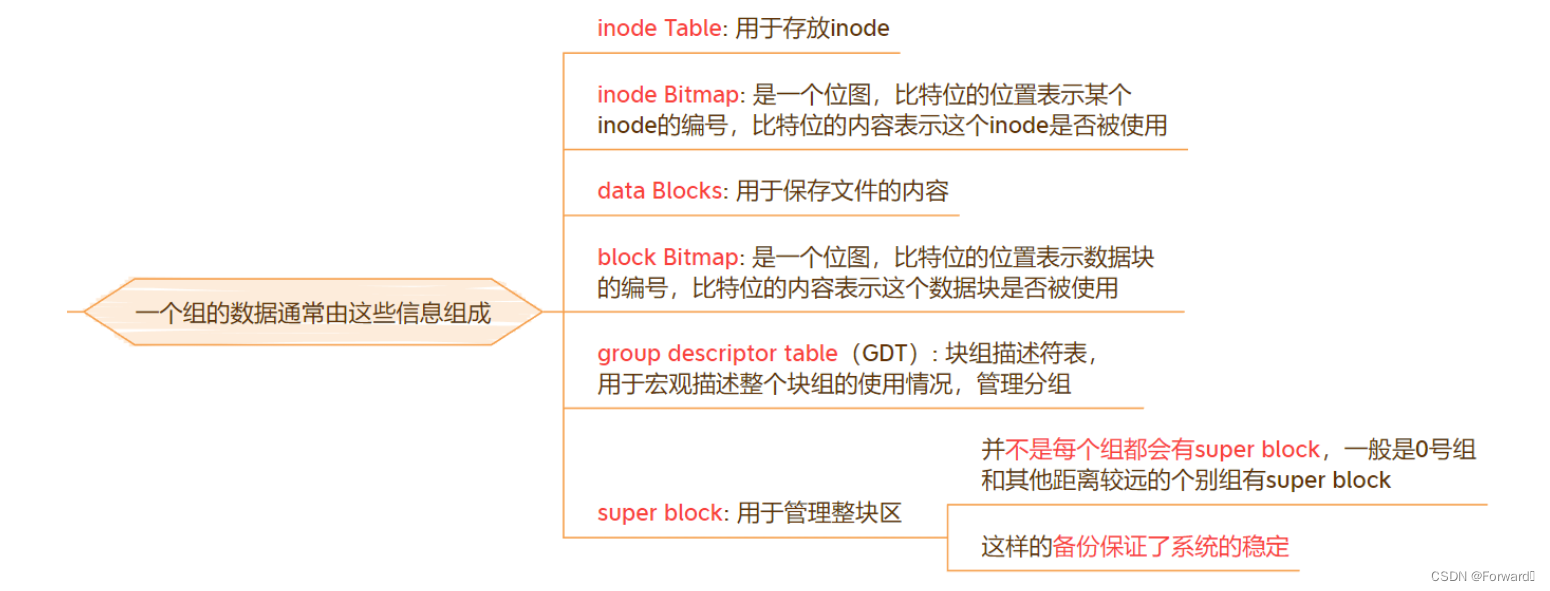
一个组(group)的内容通常由下面这些内容组成:

为了方便理解这些内容,我们先来回顾一下文件这一概念:
大家都知道,文件 = 内容 + 属性
文件的属性是由一系列有限的变量来描述的,例如文件大小、文件的创建时间、修改时间等,由于这些变量的大小一定,因此文件属性的大小也是确定的
- 需要注意,文件名不属于文件的属性,因为文件名是一个字符串,其大小会跟着文件名的改变而改变
文件的内容显然会随着文件存放的数据而改变,因此文件内容的大小是不确定的
文件的内容和属性时分开存放的
inode Table && inode Bitmap:
何为inode:
- 文件的所有属性实际上都存放在一个名为
inode的结构体中,通常inode结构体的大小为128字节- 每一个文件都有一个唯一的
inode 编号,可以用命令ll -i来查看一个文件的inode编号:
inode Table:
inode Table是用来存放文件inode的区域inode Bitmap:
inode Bitmap是一个位图,比特位的位置表示inode Table中inode的某一编号,比特位的内容表示这一编号的inode是否被使用关于
inode 编号:
系统用来识别一个文件时,直接使用的不是文件名,而是
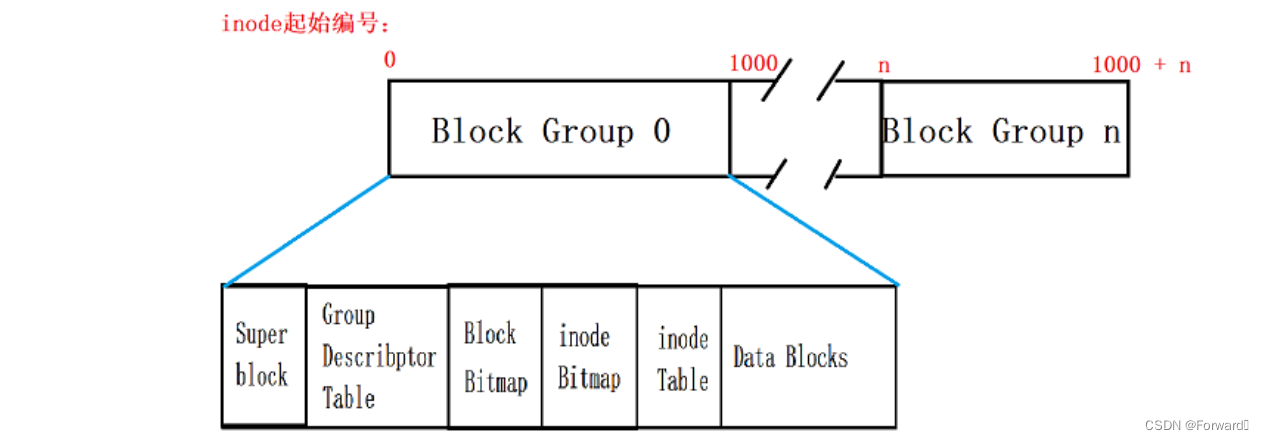
inode编号实际上,对于每个分组,他都有一个起始的indoe编号。例如,如果一个分组有1000个inode:
对于每一个
inode编号,我们可以通过这样的方式来确定他具体所在的位置:编号 / 1000就可以求得这个inode在哪个组,编号 % 1000就可以得到他在这个分组中inode Table的具体位置反过来,我们也可以通过类似的方式来求得一个特定
inode的inode编号:inode编号 = 所在分组的起始inode编号 + 偏移量


Data Blocks && Block Bitmap:
Data Blocks:
Data Blocks用于存放文件的内容Block Bitmap:
Block Bitmap是一个位图,比特位的位置表示数据块的编号,比特位的内容表示这个数据块是否被占用
文件内容和属性的联系:
既然文件的内容和属性时分开存储的,但系统读取文件是通过
inode 编号,那么怎么通过文件的inode 编号来找到文件的内容?
- 实际上,用于描述文件属性的
inode结构体中有一个数组int block[15]- 对于下标[0, 11]的空间,其存储着这个文件内容使用的数据块的编号
- 对于下标[12, 13],其不直接存储数据块的编号,而是指向一个数据块,但这个数据块并不存储文件的内容,而是继续存放着数据块的编号,这样就成了一个二级索引
- 对于下标[14],和下标[12, 13]类似,只不过这是一个三级索引
- 通过上面的方式一个较小空间的数组
block就可以映射到大量的数据块,从而可以通过文件的inode 编号找到文件的内容
Group Descriptor Table:
- 存放着描述这个组(group)的各种信息,例如
inode 起始编号,该组有多少个inode,多少个数据块等Group Descriptor Table管理着整个组(group),因此如果其发生错误,整个组(group)便无法使用
Super Block
- 存放着所在分区的各种信息,例如组(group)的个数、组的大小等
- 并不是每个组都有
Super BlockSuper Block管理着整个分区,因此如果其发生错误,整个分区便无法使用- 为了提高文件系统的容错性,除了第一个组有
Super Block外,每隔一段距离的分组也会包含相同的Super Block,这样的备份就大大提高了分区的容错性
2.3.2 目录、文件名与inode

在Linux中,一切皆文件。因此我们知道目录也是一个文件,因此目录也有它的inode与inode 编号:

而目录的内容,存放的就是目录里面文件名和文件对应inode 编号的映射关系
我们前面提到过,系统查找一个文件时,直接使用的不是文件名,而是该文件的inode 编号,具体过程应该是这样的:
- 例如系统要访问一个文件
/home/Test/test.s,仅仅提供文件名test.c是不够的,还需要找到这个文件所在的目录Test- 又由于目录
Test也是一个文件,要找到这个文件,我们也需要找到其所在的目录home- 最后要找到目录文件
home,就要回到根目录/
因此我们可以得出这样的结论:
- 文件的增、删、查、改都是和文件所在的目录有关的
- 查找一个文件,都要逆向回溯到根目录
/,从根目录进行路径解析,从而得到文件的具体位置
有了对inode的理解,我们也可以重新回顾一下目录权限的概念:
目录的内容是包含的文件名与文件inode编号的映射关系
- 如果目录没有
r读权限:无法读取文件名与文件inode编号的映射关系,也就无法通过inode编号来找到文件的属性和内容,从而无法查看一个文件- 如果目录没有
w写权限:没有写权限,也就无法在目录内新建文件,即无法建立文件名与文件inode编号的映射关系,即无法改变文件内容
2.3.3 重谈文件的新建与删除
新建文件:
- 首先在
inode Bitmap中查看空闲的inode编号,并将文件的属性写入到inode Table中空闲的位置,同时修改inode Bitmap特定比特位的内容- 类似的方法,将文件的内容写入到
Data Block中空闲的位置,并建立内容和属性的映射关系同时修改Block Bitmap特定比特位的内容- 根据
inode 编号 = 分组起始inode编号 + 偏移量求得inode编号- 最后将inode编号与新建文件的文件名建立映射关系
删除文件:
- 根据文件的
inode编号找到文件所在的分组以及其inode Bitmap的偏移量,将所在位置的比特位置零,即表示属性删除完毕- 同理,根据
inode编号也可以找到文件的inode,从而找到文件内容占用数据块的编号,也就是Block Bitmap中的偏移量,将这些比特位置零,即表示内容删除完毕
注意:
- 通过上面的描述可以发现,删除文件只需要修改内容和属性对应比特位的内容,表示对应编号的inode和数据块没被占用即可
- 而不需要删除
inode Table以及Block Table中的内容(这些内容被新文件的属性和内容覆盖即可)- 因此,这也就和现实对应了起来:删除文件的速度往往远快于下载文件的速度