前面介绍过,work stealing queue是bthread种的重要机制,worker给自己的队列里添加任务,消化任务,也如果空闲下来了就会去其他worker的队列steal,这样能够充分利用好所有的worker,避免任务积压。但是可以想象,这个队列很可能回同时被多个worker访问,如果设计不合理同步开销是很大的,因此在brpc里实现了这么一个lock free的queue,其中就用到了各种memory order,关于c++的memory order前面专门得文章已经介绍得差不多了,这里刚好以WorkStealingQueue为例,介绍下memory order的实际使用,这个类代码量不大,也基本不涉及到其他模块,因此也很适合分析memory order的使用。
1. 基本介绍
每个worker(task group)有一个_rq的WorkStealingQueue类型变量,保存这待执行的bthread标识符:
WorkStealingQueue
worker会把要执行的bthread往队列里放,其他worker会来steal,worker自身的放(push)和取(pop)在一侧,其他worker的steal在另一侧,由于push和pop都只有当前worker调用,因此永远不会同时进行,但是steal会被其他worker调用,首先steal会和steal并发,而且steal也会和pop以及push并发。
下面是容量为4的简单的示意图:
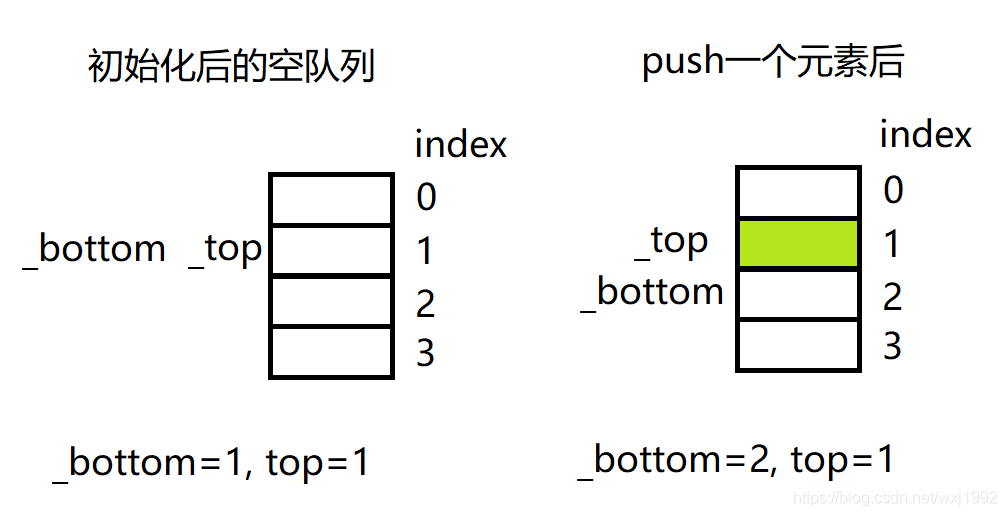
2. 类变量和初始化
因为是双向访问的队列,因此有_bottom和_top,自然还有容量_capacity,而_buffer就是实际保存数据的数组。
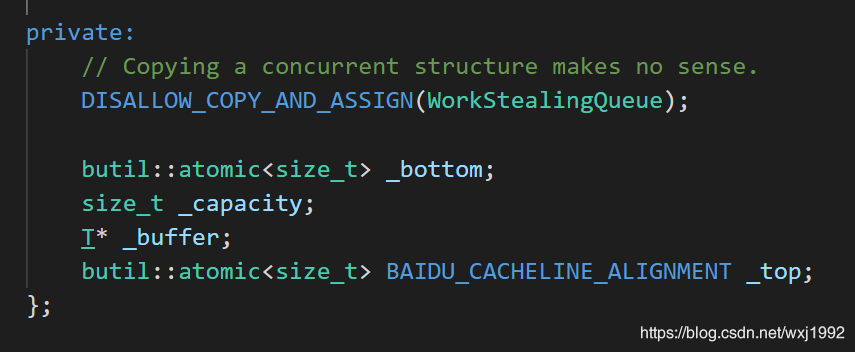
构造函数如下,未初始化前容量为0,bottom和top相等,均为1,buffer未分配空间。

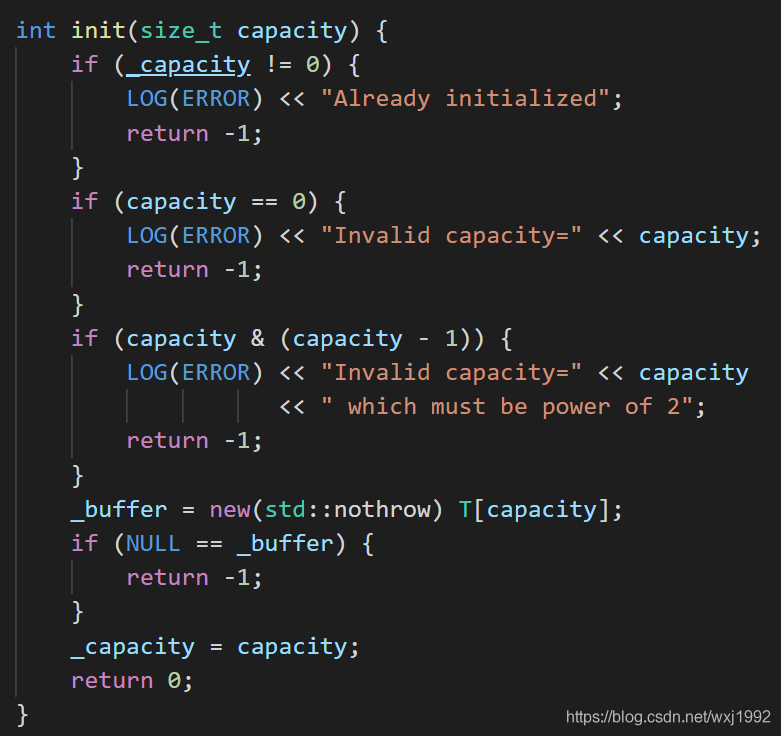
初始化函数如下,主要是传入容量分配所需空间,注意容量必须是2的幂,这个要求和上面bottom和top初始化为1都是为了快速定位到访问元素并且支持循环访问。
3. push函数

push 是往队列的bottom侧添加元素,只有worker自己会调用,成功返回true,因为满了无法push返回false。
首先是读取bottom和top,bottom的load采用了relaxed,top的load用的acquire,如果是x86-64架构,relaxed和acquire以及release没有任何区别,因为cpu本身就保证了release acquire语义。考虑跨平台通用性的话,这个函数里_buffer没有同步的需求,我理解其实top的load用acquire也是没必要的,因为用acquire是可以保证读到了别的线程修改的top后修改top前的修改可见,能和push同时运行的只有steal。而steal对top的修改之前并没有任何对需要同步的数据的修改。
接下来就是常规的判断容量写入数据,注意b & (_capacity – 1)的定位方式,bottom和top都是可以一直往上加的。因为_capacity是2的幂,二进制也就是0010、0100、1000这样的,对应的(_capacity – 1)是0001、0011、0111,利用一直加和按位与可以巧妙地实现队列地循环。
注意bottom的store用了release,这是为了保证对_buffer的数据写入对steal的acquire读取可见。
4. pop函数
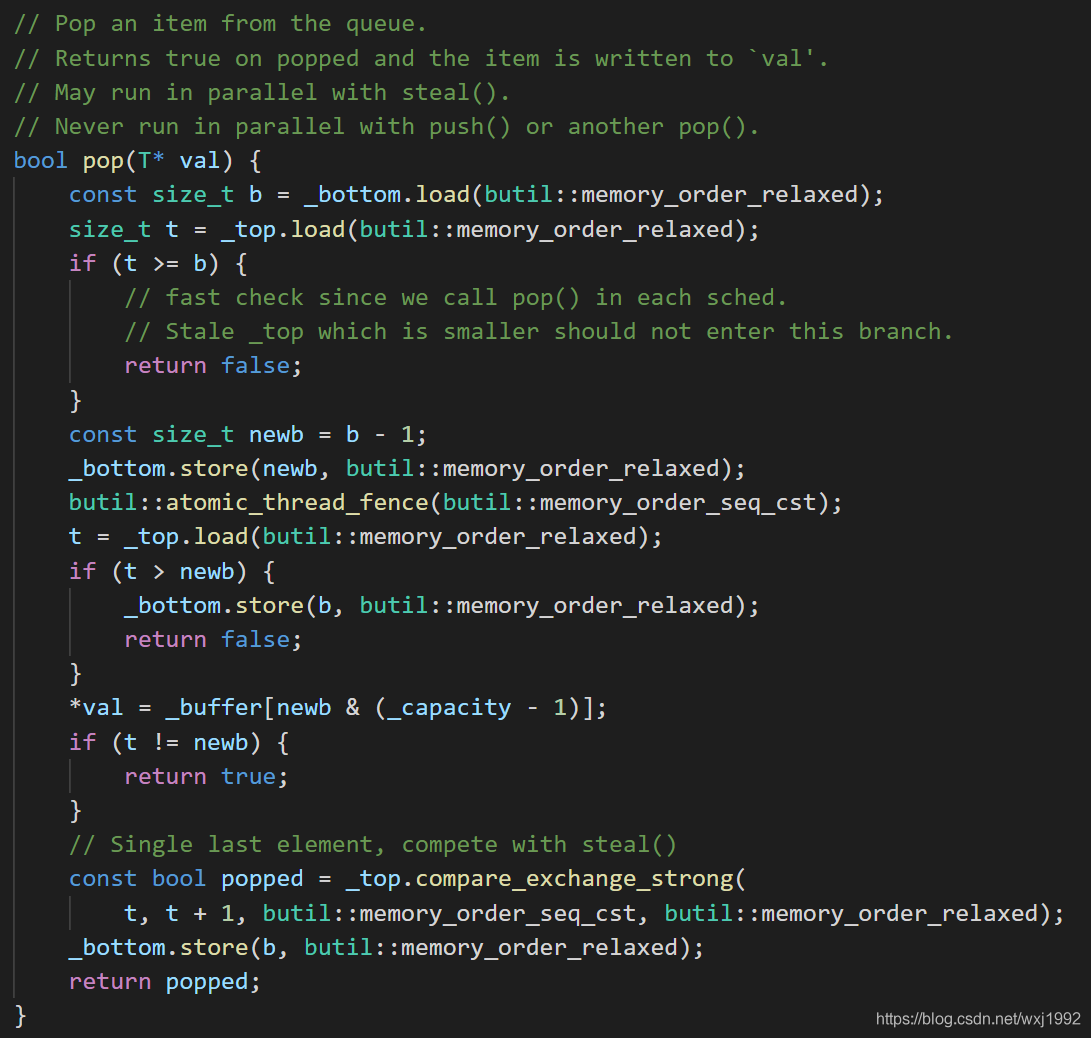
pop是从bottom侧取数据,因为会和从top侧取的steal同时运行,核心思想是先把bottom减1,锁定掉一个元素,防止被steal取,在只有一个元素的时候会和steal竞争。而且很重要的一点,这个bottom的减1一定要被steal及时感知到,否则就会出现一个元素多次拿到的问题。
t > new判断是否有可取元素,没有就直接返回false。有的话暂存准备返回的数据,t如果等于newb那么说明是最后一个元素,有可能其他的steal也在取这个元素,因此随后用compare_exchange_strong去竞争,如果成功则返回,否则回退掉b的改动。
butil::atomic_thread_fence(butil::memory_order_seq_cst);则是保证数据同步的关键,前面memory order相关的文章介绍过,这行代码在x86-64cpu上对应的典型指令是MFENCE,可以保证MFENCE之后的指令在执行之前MFENCE前面的修改全局可见,也就可以保证t赋值完成后bottom的store已经全局可见了。
5. steal函数
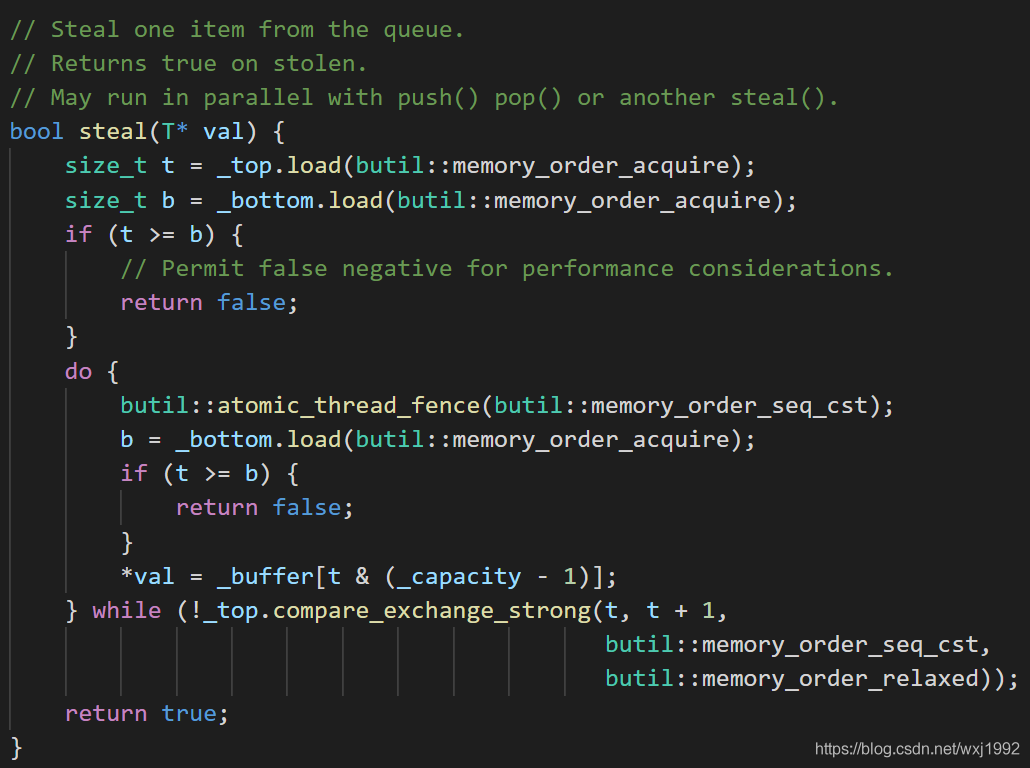
steal是要从top侧读数据,因此需要acquire读bottom确保push写入的buffer元素的可见性,至于top我理解不需要acquire,这里应该是为了一致。
t>=b认为是空队列直接返回失败,这里说的false negtive是指t>=b的时候队列可能并不空,因为bottom 和top这种共享变量都是有同步延迟的。
随后是用cas操作来执行具体的steal逻辑,先预读后尝试为t加1,因为会其他的steal和pop竞争,因此可能会失败,所以用了一个do while循环,只要队列不为空就持续尝试steal。do while循环的开头是一个seq_cst fence,如果是用mfence实现的,由于有pop里的fence的存在,steal里的fence是可以不需要的,看戈神在相关issue里的回复是担心实现的不确定性,以及为了明确所以用单独的fence也加上了。
6. atomic_thread_fence(butil::memory_order_seq_cst)的必要性
atomic_thread_fence(butil::memory_order_seq_cst)是为了保证取元素竞争情况下的正确性。在pop确定t的时候一定要保证 bottom的store全局可见。
戈神举过一个相关例子,前面文章也有人问到了这个,这里阐述下,假设top=1,bottom=3,pop先置newb=2,bottom=newb=2,然后读取了一个t=top=1,随后有两个steal争抢,其中一个成功了,此时top=2,失败的继续循环,如果因为数据同步的原因此时没看到pop置的bottom=2,也就是没有全局可见,那么steal线程里仍然是b=bottom=3,这次cas能成功置top=3,因为pop线程是原来读取的t,t!=newb成立也成功,导致一个元素返回了两次。
而一旦pop函数里有了atomic_thread_fence(butil::memory_order_seq_cst),在x86-64的实际实现上通常是插入mfence指令,这个指令会让前面的store全局可见,这样一来,无论那两个steal的第一次cas循环读到的是新的bottom还是老的bottom,失败后再循环的那一个第二次读到的肯定是新的bottom,随即因为t>=b失败,这样就只有pop返回了。如果atomic_thread_fence(butil::memory_order_seq_cst)是用mfence实现的,这个场景的steal里的butil::atomic_thread_fence(butil::memory_order_seq_cst)是可以不需要的,看戈神在那个issue里的回复是担心实现的不确定性,以及为了明确所以也写了。
7. volatile_size函数
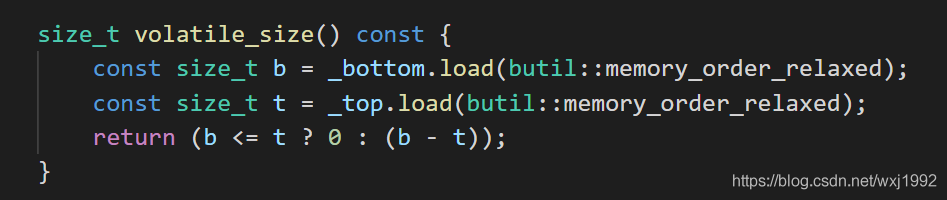
这就是个简单的获取大小的,名字是volatile_size而不是size,是因为这种结构没法获取到精确的size。