Bthread是brpc用到的一个线程库,也是brpc的核心之一,默认情况下,包括用户代码在内的绝大部分代码都是运行在bthread里的,bthread也是brpc实现高性能的基石。
一、概述
bthread在官方文档里定义如下:
bthread是baidu-rpc使用的M:N线程库,目的是在提高程序的并发度的同时,降低编码难度,并在核数日益增多的CPU上提供更好的scalability, cache locality。”M:N“是指M个bthread会映射至N个pthread,一般M远大于N。由于linux当下的pthread实现(NPTL)是1:1的,M个bthread也相当于映射至N个LWP。
Goals
1.用户可以延续同步的编程模式,能很快地建立bthread,可以用多种原语同步。
2.bthread所有接口可以在pthread中被调用并有合理的行为,使用bthread的代码可以在pthread中正常执行。 能充分利用多核。
3.更好的cache locality,更低的延时。
NonGoals
1.提供pthread的兼容接口,只需链接即可使用。拒绝理由:bthread没有优先级,不适用于所有的场景,链接的方式容易使用户在不知情的情况下误用bthread,造成bug。
2.修改内核让pthread支持同核快速切换。拒绝理由:拥有大量pthread后,每个线程对资源的需求被稀释了,基于thread-local cache的代码效果都会很差,比如tcmalloc。而独立的bthread不会有这个问题,因为它最终还是被映射到了少量的pthread。
官方地定义很好地总结了bthread的设计理念,个人认为核心就是用户可以延续同步的编程模式,但获得优秀的并发,并且保持了作为用户态线程的合理的克制,虽然能在pthread运行但对pthread没有侵入性。关于bthread的官方文档非常详细,想要深入了解可以参考官方文档,这里着重介绍一下在实际使用过程中bthread的一些运行机制。
之所以要采用这么一种M:N的机制,是为了兼顾当前多核cpu以及调度竞争上,考虑两种极端情况,一是每个用户线程对应一个内核线程,如果是这种模型,对多核cpu的利用会很充分,但是调度成本(用户态内核态的切换)以及线程间的数据同步成本都比较高,而是所有的用户线程都在一个内核线程的情况,这种情况下调度成本和数据同步成本低,但很难利用多核cpu的能力,同时用户线程也容易block。所以M:N线程库bthread的主要思想就是,M 个bthread 可以运行在N个内核线程上,也就是有N个worker分别运行在N个pthread上,所有的bthread都是在worker上调度运行,woker运行完一个bthread后就会去队列里调度下一个bthread,既可以从当前worker的本地队列里调度,也可以从其他worker的队列里取,也就是所谓的work stealing机制,该机制也是bthread核心设计之一。
二、启动入口函数
作为一个线程库,用户最常用的自然是启动线程,bthread的启动入口函数有两个:
(1)bthread_start_urgent:让出当前worker立即执行新bthread。
(2)bthread_start_background:将要启动的bthread放入队列等待调度。
函数名也说明了各自的行为。函数声明如下:
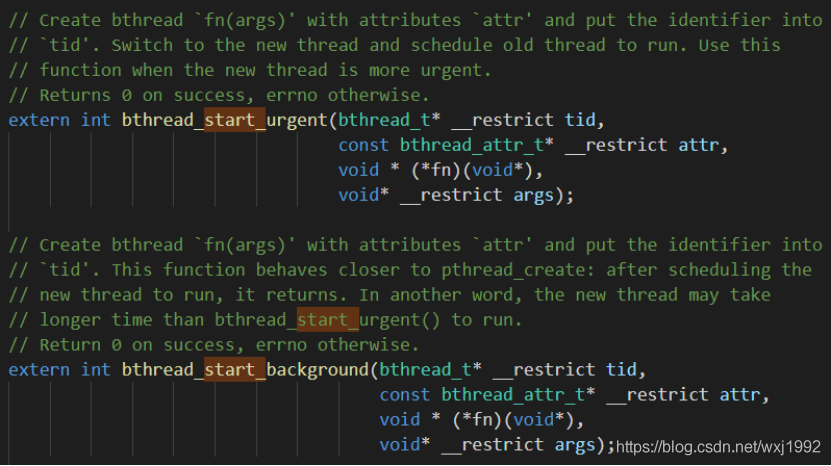
函数定义如下:
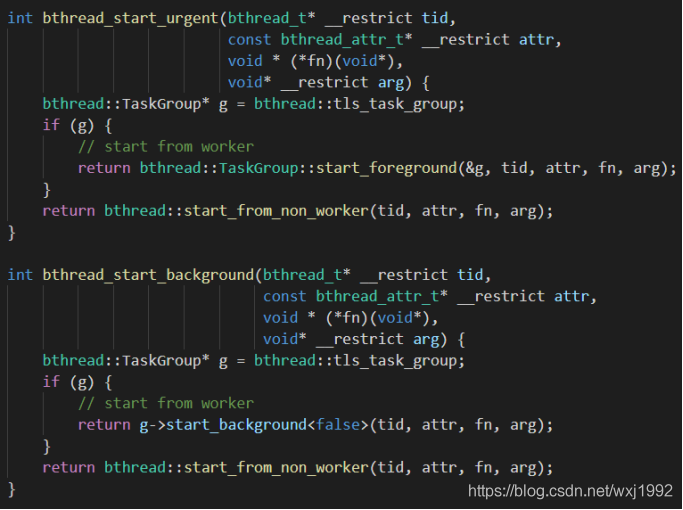
可以看到,二者很类似,都是先去获取了一个TaskGroup指针类型的变量g,然后根据g是否为null执行不同的逻辑。这里就涉及到bthread的taskgroup的概念,taskgroup的字面意思是任务组,一个taskgroup对应一个worker,所有的taskgroup由一个task_control的单例控制。在task_group.cpp里,有一个__thread变量tls_task_group,该变量在bthread.cpp里和task_control.cpp里均通过extern方式共用,也就是有一个thread-local的全局变量bthread::tls_task_group:

这个tls变量很重要,表明当前线程所归属的taskgroup,如果为null,说明当前线程不是bthread。
在上述启动bthread的函数里,首先就会判断taskgroup是否为null,如果不为null,则表明当前就是bthread而且taskgroup指明了对应的taskgroup,在对应taskgroup(worker)执行新bthread的启动即可,区别就是bthread_start_urgent调用内部的start_foreground,而bthread_start_background调用内部的start_background,否则属于在非worker上新启bthread,这个场景两个入口函数效果一样。
三、内部启动函数
bthread_start_urgent调用的TaskGroup::start_foreground函数核心部分如下:

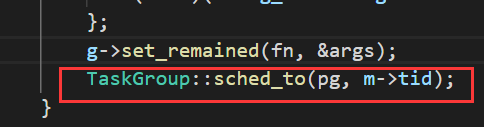
这个函数里主要就是为要执行的任务新建taskmeta并对各种变量赋值,最重要的部分是fn和arg的赋值,然后最终直接调度执行。
而start_background和start_foreground最大的区别在于不是直接调度执行,如下:

REMOTE是函数模板参数,表明是否是从worker启动,为false说明不是远程,也就是是从worker启动。上面bthread_start_background直接调用start_foreground用的参数就是false,因为是从worker启动的。这个参数决定了调用ready_to_run_romote还是ready_to_run,二者分别如下:
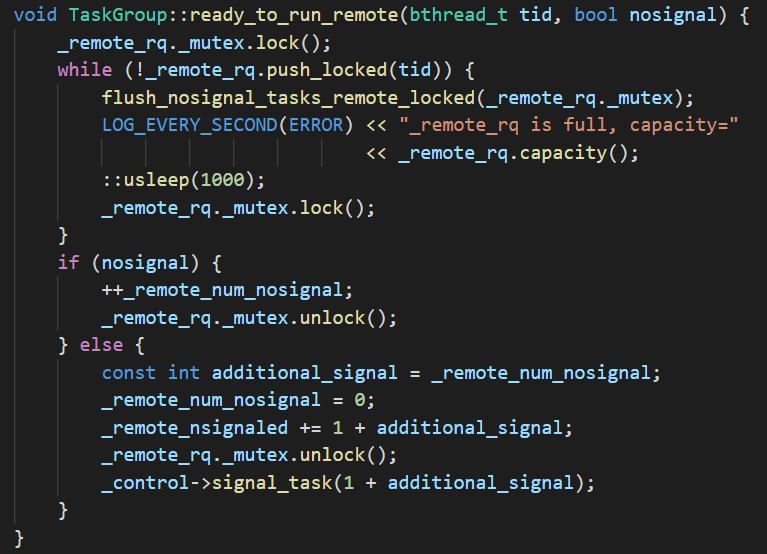
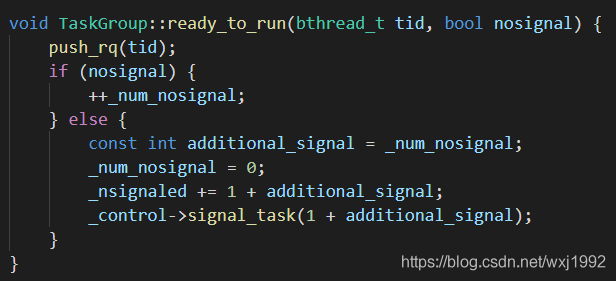
二者的主要区别是对于来自非worker的bthread,放入_remote_rq队列,来自worker的放入_rq队列,总的来说是一个把任务加入队列然后调用signal按需唤醒woker的过程。调度顺序上,本地队列_rq的优先级比_remote_rq高,而且_rq是wait-free的,_remote_rq是用mutex保护的。
入口函数bthread_start_urgent或者bthread_start_background如果发现taskgroup是为null,则说明调用方不是在bthread里,这个时候去调用的start_from_non_worker函数如下:
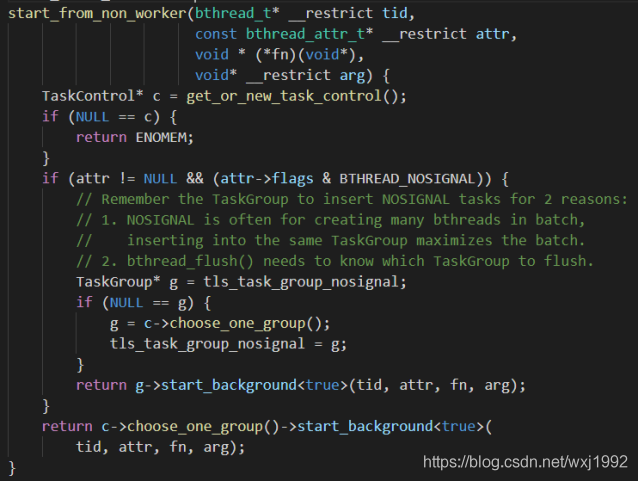
该函数里会首先检查是否已经有task_control单例了,如果有说明其他地方已经建立过bthread了,也就已经启动了一定数量的taskgroup,如果没有说明是首次启动bthread,需要创建,new taskcontrol后会执行taskcontrol的init,核心就是用pthread启动指定数量的worker,如下:
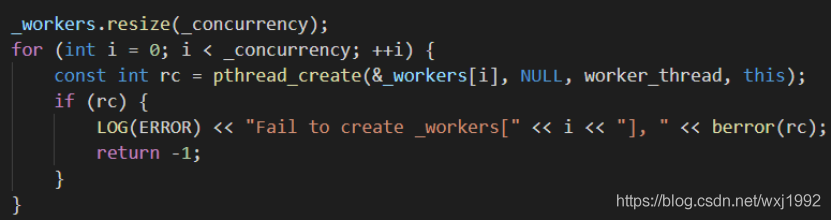
得到taskcontrol单例后,用taskcontrol选取一个taskgroup,新建bthread进行调度。
上图里worker_thread函数如下:
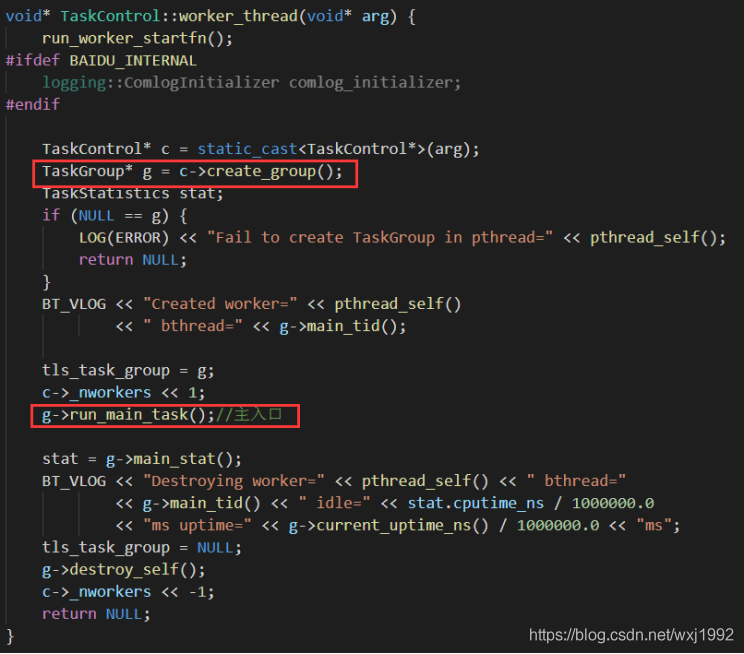
先是调用create_group新建并初始化task_group,随后调用run_main_task,也就是worker的工作入口
四、worker工作入口
run_main_task的核心就是不断循环等待可以执行的bthread,包括去其他的woker steal,然后执行。如下:
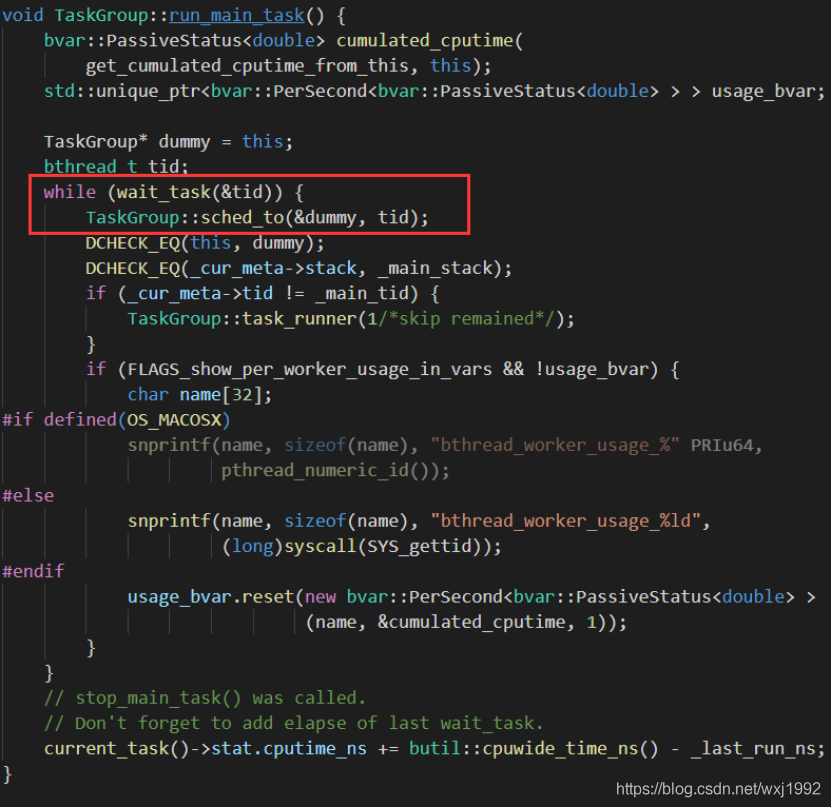
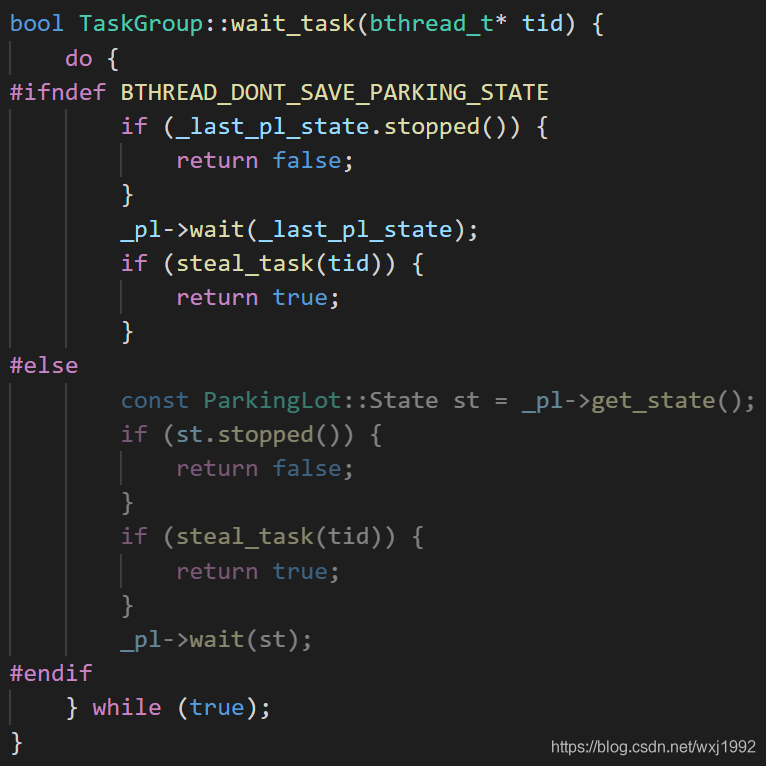
一旦拿到了可以执行的任务,则调用sched_to进行执行,里面是一些context的切换后执行之类的底层操作。前面提到了,如果在一个bthread里执行bthread_start_urgent,会调用TaskGroup::start_foreground,里面也是调用TaskGroup::sched_to立即让出当前worker。
上面调用的TaskGroup::sched_to函数如下:
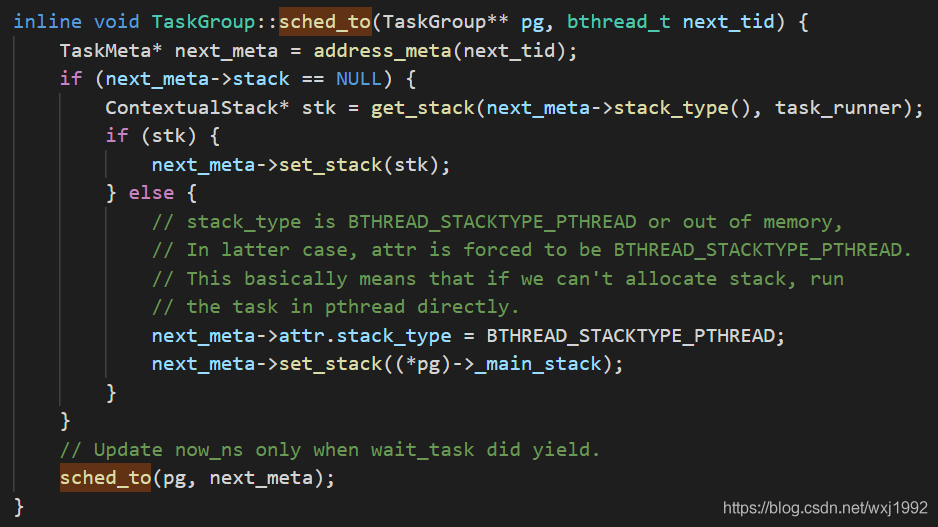
根据传入的next_tid取出对应bthread的meta信息,如果对应meta的stack为空,说明这是一个新建的bthread,则会调用get_stack从一个object pool类型的资源池里取出stack对象赋给bthread,object pool继承自resource pool。get_stack函数如下:
 注意get_stack所用的参数:get_stack(next_meta->stack_type(), task_runner),第一个参数是stack类型,主要是按大小分为了好几种,第二个task_runner则是真正的用户函数的入口函数,task_runner内部核心代码如下:
注意get_stack所用的参数:get_stack(next_meta->stack_type(), task_runner),第一个参数是stack类型,主要是按大小分为了好几种,第二个task_runner则是真正的用户函数的入口函数,task_runner内部核心代码如下:

m->fn(m-arg)就是使用启动bthread时提供的用户函数和对应参数进行调用。这个task_runner经过层层调用最终会作为一个叫做bthread_make_fcontext的汇编实现的函数的参数,该函数真正构造一个从taskrunner开始执行的stack,如下:

确保stack就绪后再调用内部的另一个void TaskGroup::sched_to(TaskGroup** pg, TaskMeta* next_meta)重载去执行切换操作。这个函数里比较长,核心部分如下:

切换threadlocal变量
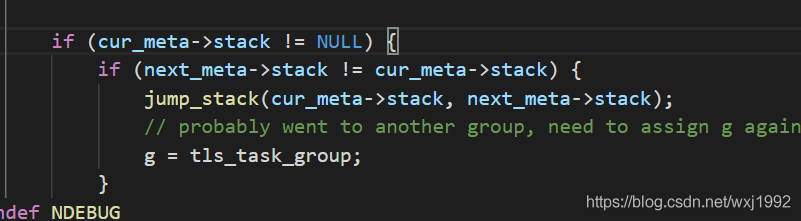
进行堆栈的切换,也是bthread切换最关键的部分,jump_stack函数如下:

调用的是bthread_jump_fcontext,和bthread_jump_fcontext一样也是由汇编实现的,真正的去操作寄存器等完成线程切换。
五、总结
这篇文章介绍了bthread主要的启动和调度过程。除了这些,bthread还实现了butex,提供了类似pthread的同步原语,同时也有和pthread类似的bthread_join接口和tls支持接口等,总的来说接口和pthread很类似,同时因为bthread是跑在pthread里的,也支持在bthread里调用阻塞的pthread接口直接阻塞worker,具体的可以参照官方文档和注释很清晰的源码,这里不再赘述。