**#相关介绍:xpath是在XML文档中搜索内容的一门语言;html是xml的一个子集。
一、首先安装lxml模块,这里以pycharm开发环境为例,在Terminal命令行输入pip install lxml 出现如下页面即是安装成功。
1.再介入案例之前,首先看一个小例子:
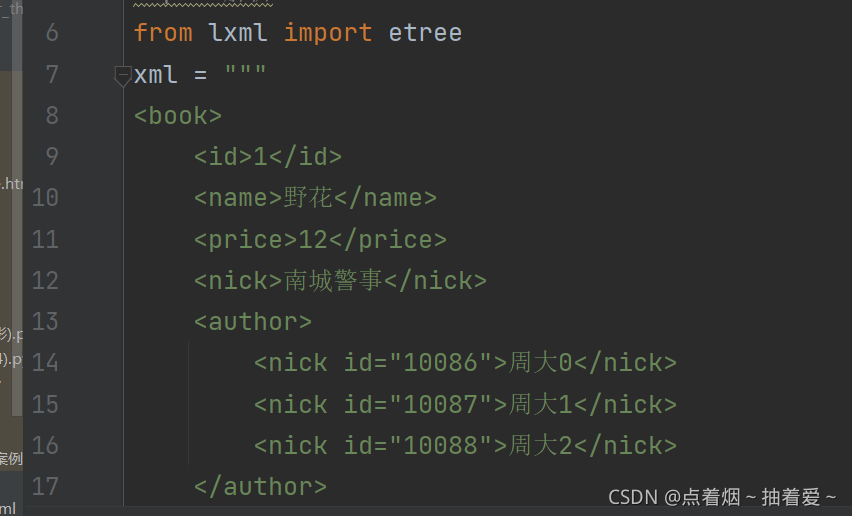
(1)先从lxml模块导入etree包;
(2)xml可以看作是网页源代码(相关知识html标签语言)
(3)第20行拿到页面源代码(调用XML方法);
(4)调用xpath方法。
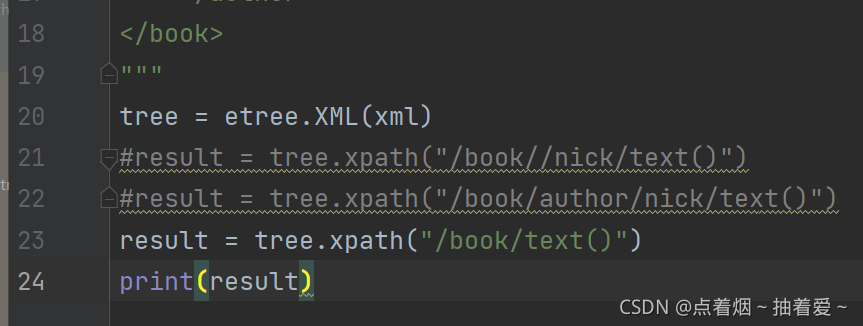
输出结果如下:

二、关于xpath基本案例
1.拿到页面源代码(以猪八戒网为例)
import requests
from lxml import etree
url = "https://taiyuan.zbj.com/sem_search/f/?kw=sass"
res = requests.get(url)
2.HTML对源代码进行解析
xml = etree.HTML(res.text)
3.拿到每一个服务商的div
divs = xml.xpath("/html/body/div[6]/div/div/div[2]/div[7]/div/div[1]")
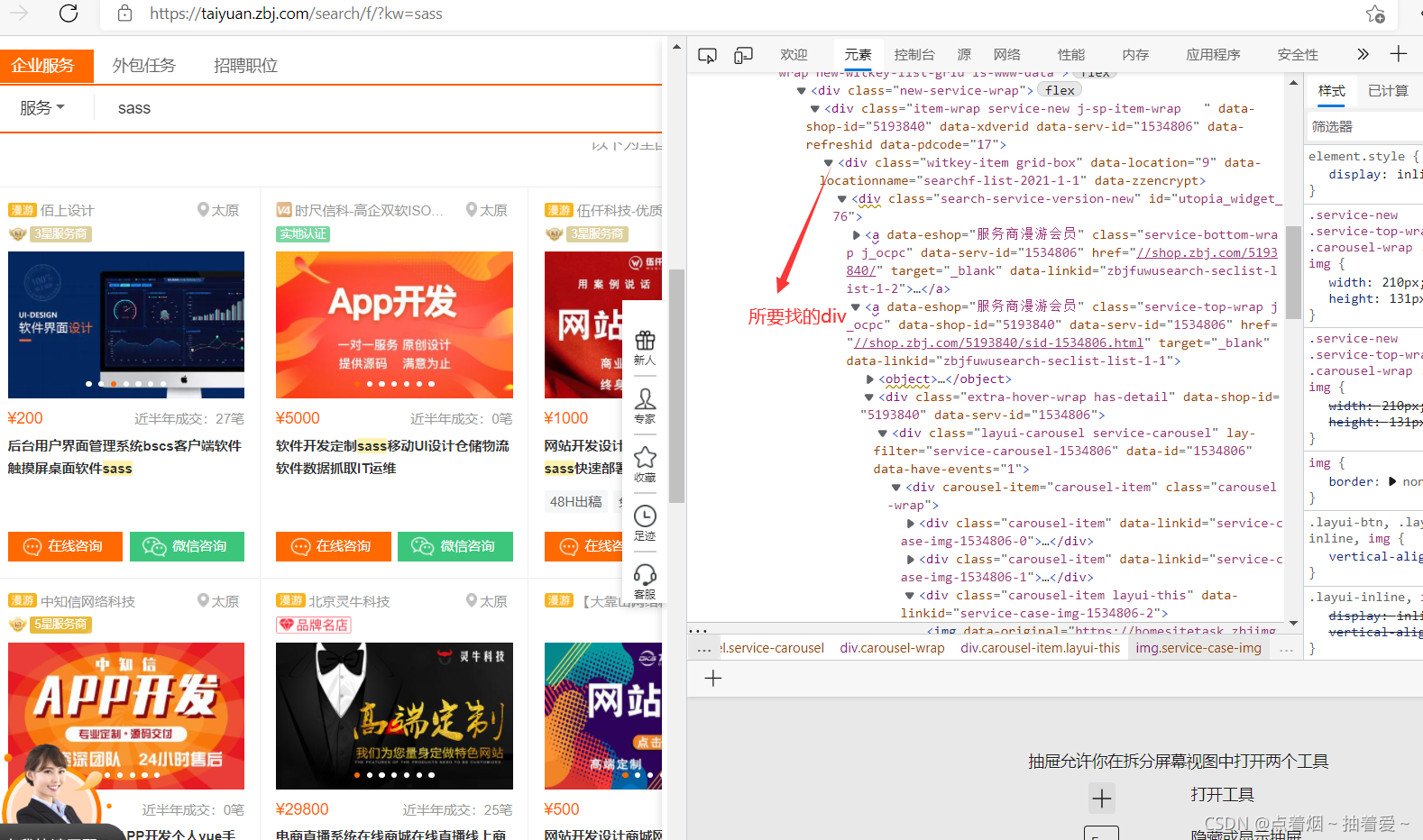
右击选择复制->复制xpath,然后粘贴到代码区。
4.遍历服务商信息
for div in divs:#每一个服务商信息
result1 = div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()")
result2 = div.xpath("./div/div/a[2]/div[2]/div[1]/span[2]/text()")
print(result1, result2)
['¥5000'] ['近半年成交:0笔']
成功爬取此信息。小伙伴们也可以用同样的方法爬取更多的信息。
