Beautiful Soup是Python的一个网页解析库,处理快捷; 支持多种解析器,功能强大。教程细致讲解Beautiful Soup的深入使用、节点选择器、CSS选择器、Beautiful Soup4的方法选择器等重要知识点,是学好爬虫的基础课程。
节点选择器——关联选择的方法
学习目标
- 掌握关联选择的方法的使用
1. 关联选择
在做选择的时候,有时候不能做到一步就选到想要的节点元素,例如示例中的第二个a节点
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
需要先选中某一个节点元素,然后以它为基准再选择它的子节点、父节点、兄弟节点等,接下来我们来介绍如何选择这些节点元素。
1. 子节点
-
格式:
soup.tag.contents -
返回值:列表
-
示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element"> Foo</li> <li class="element">Bar</li> <li class="element">]ay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element"> Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') # 获取p节点的子节点 print(soup.p.contents) # 输出结果 ['Once upon a time there were three little sisters; and their names were\n', <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a>, ',\n', <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, ' and\n', <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, ';\nand they lived at the bottom of a well.'] -
格式:
soup.tag.children -
返回值:生成器
-
示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element"> Foo</li> <li class="element">Bar</li> <li class="element">]ay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element"> Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') # 获取p节点的每一个子节点 print(soup.p.children) for i, child in enumerate(soup.p.children): print(i, child) # 输出结果 <list_iterator object at 0x105e6c128> 0 Once upon a time there were three little sisters; and their names were 1 <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a> 2 , 3 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> 4 and 5 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> 6 ; and they lived at the bottom of a well.
2. 子孙节点
上面我们已经拿到了p节点的全部直系的子节点,如果我们想要获取p节点中的所有子孙节点的话,可以使用descendants属性。
-
格式:
soup.p.descendants -
返回值:生成器
-
示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element"> Foo</li> <li class="element">Bar</li> <li class="element">]ay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element"> Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') # 获取p节点所有的子孙节点 print(soup.p.descendants) for i, child in enumerate(soup.p.descendants): print(i, child) # 输出结果 <generator object descendants at 0x102334468> 0 Once upon a time there were three little sisters; and their names were 1 <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a> 2 <span>Elsie</span> 3 Elsie 4 , 5 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> 6 Lacie 7 and 8 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> 9 Tillie 10 ; and they lived at the bottom of a well.
3. 父节点
上面我们都是在选择子节点和子孙节点,接下来我们使用parent属性获取某节点元素的父节点。
-
格式:
soup.tag.parent -
返回值:节点元素
-
示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element"> Foo</li> <li class="element">Bar</li> <li class="element">]ay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element"> Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') # 打印选取的a节点 print(soup.a) # 获取a节点的父节点 print(soup.a.parent) # 输出结果 # 选取的a节点 <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a> # 所选a节点的父节点 <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p>
4. 祖先节点
如果想要获取,祖先节点,可以调用parents属性。
-
格式:
soup.tag.parents -
返回值:生成器
-
示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element"> Foo</li> <li class="element">Bar</li> <li class="element">]ay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element"> Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') # 获取a节点的所有祖先节点 print(soup.a.parents) # 打印a节点的所有祖先节点的类型 print(type(soup.a.parents)) # 获取a节点的所有祖先节点的内容 print(list(enumerate(soup.a.parents))) # 输出结果 <generator object parents at 0x102434468> <class 'generator'> [(0, <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p>), (1, <body> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body>), (2, <html><head><title>The Dormouse's story</title></head> <body> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body></html>), (3, <html><head><title>The Dormouse's story</title></head> <body> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"><span>Elsie</span></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body></html>)]
5. 兄弟节点
上面说明了子节点和父节点的获取方式,那如果想要获取同级的节点,应该怎么办呢?接下来我们来学习下,使用sibling获取兄弟节点。
-
获取后面一个节点
-
格式:
soup.tag.next_sibling -
返回值:节点元素
-
示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element"> Foo</li> <li class="element">Bar</li> <li class="element">]ay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element"> Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') # 获取a节点的后面一个节点 print(soup.a.next_sibling) # 获取类型 print(type(soup.a.next_sibling)) # 输出结果 , <class 'bs4.element.NavigableString'> -
获取后面所有的节点
-
格式:
soup.tag.next_siblings -
返回值:生成器
-
示例:
# 获取a节点的后面所有节点 print(soup.a.next_siblings) # 获取类型 print(type(soup.a.next_siblings)) # 获取所有内容 print(list(enumerate(soup.a.next_siblings))) # 输出结果 <generator object next_siblings at 0x102434468> <class 'generator'> [(0, ',\n'), (1, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>), (2, ' and\n'), (3, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>), (4, ';\nand they lived at the bottom of a well.')] -
获取前面一个节点
-
格式:
soup.tag.previous_sibling -
返回值:节点元素
-
示例:
# 获取a节点的前一个节点 print(soup.a.previous_sibling) # 获取类型 print(type(soup.a.previous_sibling)) # 输出结果 Once upon a time there were three little sisters; and their names were <class 'bs4.element.NavigableString'> -
获取前面的所有节点
-
格式:
soup.tag.previous_siblings -
返回值:生成器
-
示例:
# 获取a节点的前面所有节点 print(soup.a.previous_siblings) # 获取类型 print(type(soup.a.previous_siblings)) # 获取所有内容 print(list(enumerate(soup.a.previous_siblings))) # 输出结果 <generator object previous_siblings at 0x102334468> <class 'generator'> [(0, 'Once upon a time there were three little sisters; and their names were\n')]
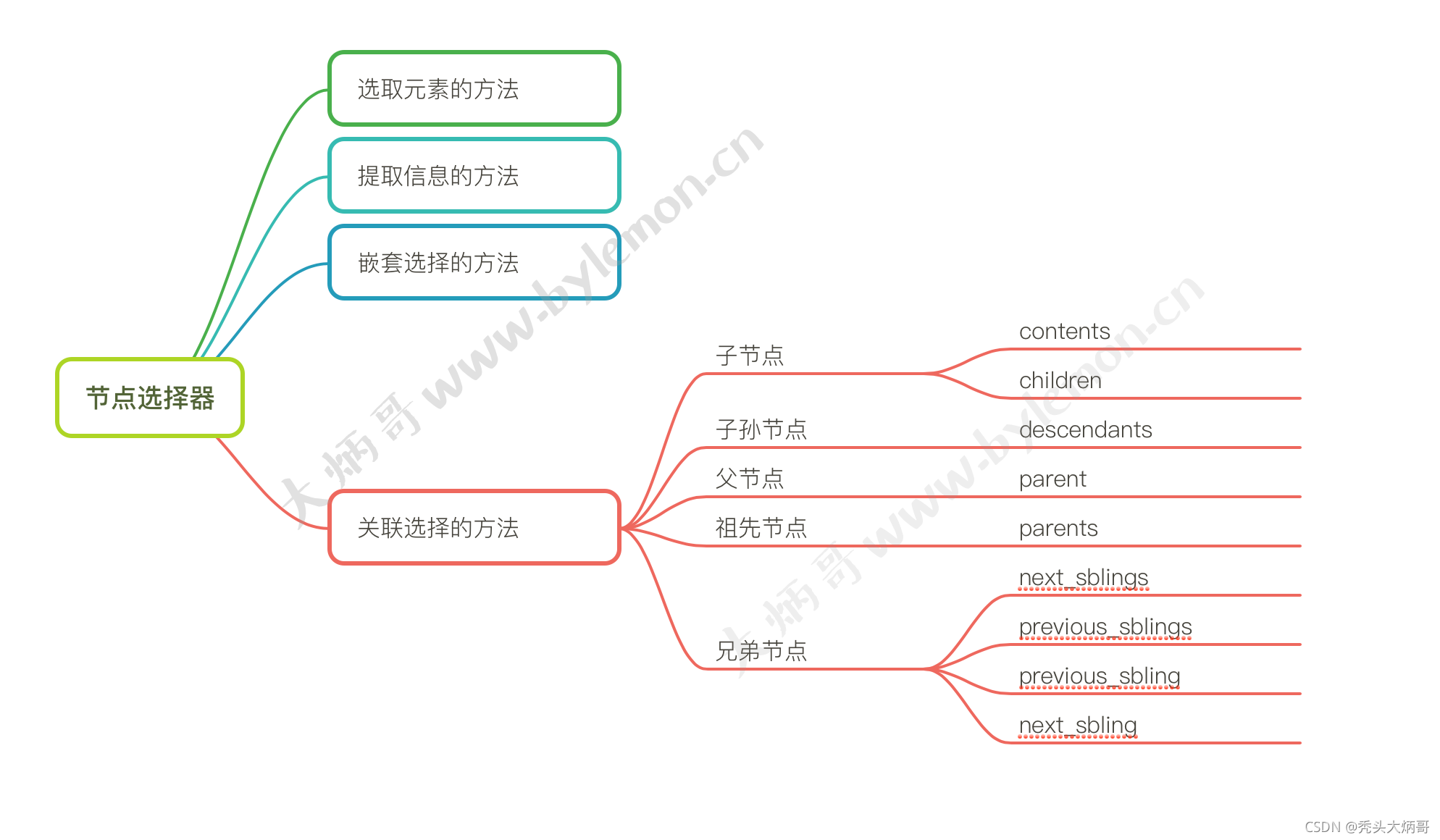
2. 总结
节点选择器 关联选择方法:
- 子节点
- soup.tag.contents
- soup.tag.children
- 子孙节点
- soup.tag.descendants
- 父节点
- soup.tag.parent
- 祖先节点
- soup.tag.parents
- 兄弟节点
- soup.tag.next_sibling
- soup.tag.next_siblings
- soup.tag…previous_sibling
- soup.tag…previous_siblings