Xpath用法详细总结
HTML内容解析
网页的源代码是一种结构化的数据,如果仅仅使用正则表达式,那么这种结构化的优势就没有被很好地利用起来。
HTML简单介绍

<标签名>
文本
<标签名 属性1=“属性1的值” 属性2=“属性2的值”>
显示在网页上的文本

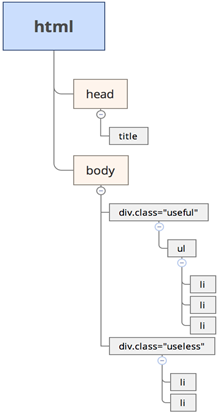
HTML标签的层级关系就像树形结构
xpath 介绍
XPath(XML Path)是一种查询语言,形象一点来说,XPath就是一种根据“地址”来“找人”的语言。
用正则表达式来提取信息,经常会出现无法提取想要内容的情况,最后即便绞尽脑汁把想要的内容提取了出来,却发现已浪费太多时间。而用XPath从HTML源代码中提取信息可以大大提高效率。
思考?
提取出以下信息,该怎么办?
我需要的信息1
我需要的信息2
我需要的信息3
 图:code
图:code
在看XPath的用法之前,请大家思考,如果使用正则表达式应该要写几行代码才能实现。
Xpath语法详解
如果使用XPath,代码只有一行:
info = selector.xpath('//div[@class="useful"]/ul/li/text()')
| 表达式 | 说明 |
|---|---|
| namenode | 选取nodename节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| . . | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取节点内的文本 |
举例
| 表达式 | 说明 |
|---|---|
| /html/body/div[1] | 选取属于body子节点下的第一个div |
| /html/body/div[last()] | 选取属于body子节点下的最后一个div |
| /html/body/div[last() – 1] | 选取属于body子节点下的倒数第二个div |
| /html/body/div[position() < 3] | 选取属于body子节点下的前两个div |
| /html/body/div[@id] | 选取属于body子节点下的所有具有id属性的div |
| /html/body/div[@id = “content”] | 选取属于body子节点下id为content的div |
| /html/body/div[XX>10.00] | 选取属于body子节点下xx元素大于10的div |
Xpath语法详解
info = selector.xpath('//div[@class="useful"]/ul/li/text()')
核心思想 :写xpath就是在写地址
获取文本:
//标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/..../text()
获取属性值:
//标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/..../@属性n
其中,[@属性=“属性值”]不是必需的。它的作用是帮助过滤相同的标签。在不需要过滤相同标签的情况下可以省略。
实例
获取图code中的“我需要的信息1”
标签1可以直接从html这个最外层的标签开始,一层一层往下找,因此,XPath语句应该是这样的:
/html/body/div[@class="useful"]/ul/li/text()
或者:
//div[@class="useful"]/ul/li/text()
在XPath里面找到一个标志性的“地标”,然后从这个标志性的“地标”开始往下找就可以了。标志性的“地标”前面的标签都可以省略。< ul >标签本身就没有属性,则写XPath的时候,其属性可以省略。标签如果有属性,但是所有属性值都相同,则可以省略属性。例如< li class=“info”>,所有的< li>标签都有一个class属性,值都为info,所以属性可以省略。
Xpath功能函数
| 功能函数 | 示例 | 说明 |
|---|---|---|
| starts-with | //div[starts-with(@id,”co”)] | 选取id值以co开头的div |
| contains | //div[contains(@id,”co”)] | 选取id值包含co的div |
| and | //div[contains(@id,”co”)and contains(@id,“go”)] | 选取id包含co和go的div |