(一)简介
tcmalloc是与glibc、malloc同一级别的内存管理库,tcmalloc会hack所有glibc提供的接口,为调用者提供透明的内存分配。
(二)总体结构
- PageHeap
内存管理单位:span(连续的page的内存)
- CentralCache
内存管理单位:object(由span切成的小块,同一个span切出来的object都是相同的规格)
- ThreadCache
线程私有的缓存,理想情况下,每个线程的内存需求都在自己的ThreadCache中完成,线程之间不需要竞争,非常高效。
内存管理单位:class(由span切成的小块)
(三)分配与回收
基本思想:前面的层次分配内存失败,则从下一层分配一批补充上来;前面的层次释放了过多的内存,则回收一批到下一层次。
- 分配
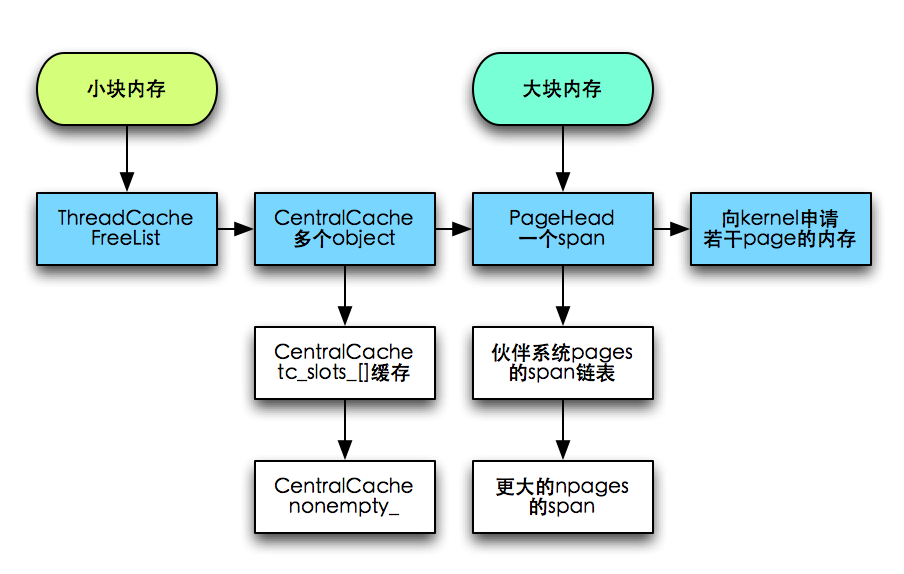
1)小块内存(<256KB)。
ThreadCache:先尝试在list_[class]的FreeList分配。
CentralCache:找到对应class的tc_slots链表,从链表中分配 -> 从nonempty_链表分配(尽量分配batch_size个object)
HeadPage:伙伴系统对应的npages的span链表 (normal->returned)-> 更大的npages的span链表,拆小
kernel:申请若干个page的内存(可能大于npages)
2)大块内存(>256KB)。
HeadPage:伙伴系统对应的npages的span链表 (normal->returned)-> 更大的npages的span链表,拆小
kernel:申请若干个page的内存(可能大于npages)
- 回收
与申请流程类似
1)ThreadCache => CentralCache
ThreadCache容量限额:
a、为每一个ThreadCache初始化一个比较小的限额,然后每当ThreadCache由于cache超限而触发object到CentralCache的回收时,就增大限额。
b、预设所有ThreadCache的总容量,一个ThreadCache容量不够时,从其他ThreadCache收刮(轮询)。
c、每个ThreadCache也有最大最小值限制,不能无限增大限额。
d、每个ThreadCache超过限额时,对其每个FreeList回收。
单个FreeList的限额:
a、慢启动。初始长度限制为1,限额1~batch_size之间为慢启动,每次限额+1。
b、超过batch_size,限额按照batch_size整数倍扩展。
c、FreeList限额超限,直接回收batch_size个object。
2)CentralCache => PageHeap
只要一个span里面的object都空闲了,就将它回收到PageHeap。
3)PageHead中的normal => returned
a、每当PageHeap回收到N个page的span时(这个过程中可能伴随着相当数目的span分配),触发一次normal到returned的回收,只回收一个span。
b、这个N值初始化为1G内存的page数,每次回收span到returned链之后,可能还会增加N值,但是最大不超过4G。
c、触发回收的过程,每次进来轮询伙伴系统中的一个normal链表,将链尾的span回收即可。
(四)数据结构
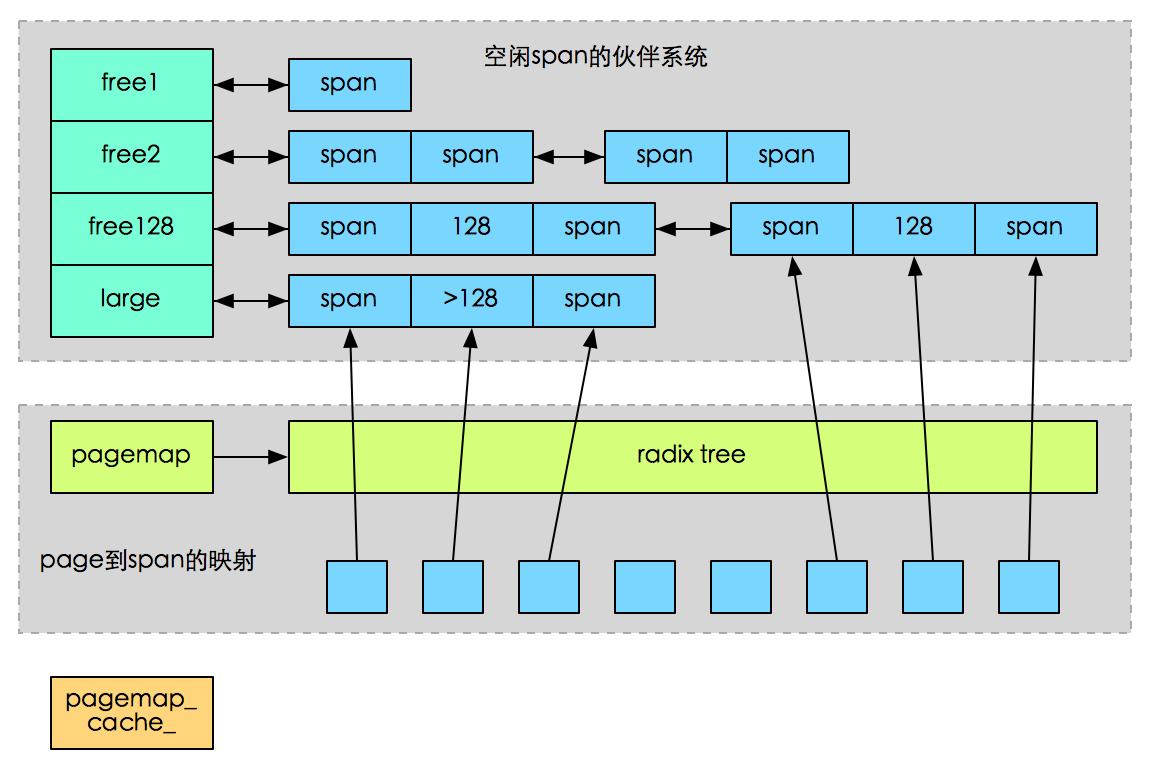
- PageHeap
1)page到span的映射关系通过radix tree来实现,逻辑上理解为一个大数组,以page的值作为偏移,就能访问到page对应的span节点。
2)为减少查询radix tree的开销,PageHeap还维护了一个最近最常使用的若干个page到object的对应关系cache。为了保持cache的效率,cache只提供64个固定坑位。
3)空闲span的伙伴系统为上层提供span的分配与回收。当需要的span没有空闲时,可以把更大尺寸的span拆小;当span回收时,又需要判断相邻的span是否空闲,以便组合他们
4)normal和returned:多余的内存放到returned中,与normal隔离。normal的内存总是优先被使用,kernel倾向于一直保留他们;而returned的内存不常被使用,kernel内存不足时优先swap他们。
- CentralFreeList
1)维护span的链表,每个span下面再挂一个由这个span切分出来的object的链。便于在span内的object都已经free的情况下,将span整体回收给PageHeap;每个回收回来的object都需要寻找自己所属的span后才挂进freelist,比较耗时。
2)empty的span链和nonempty的span链:CentralFreeList中的span链表有nonempty_和empty_两个,根据span的object链是否有空闲,放入对应链表。如果span的内存已经用完则把这个span移到empty链表中。
3)通过页找到对应span:被CentralFreeList使用的span,都会把这个span上的所有页都注册到radixtree中,这样对于这个span上的任意页都可以通过页ID找到这个span。
4)如果span的内存已经完全被释放(span->refcount==0),则把这个span归还到PageHead中。

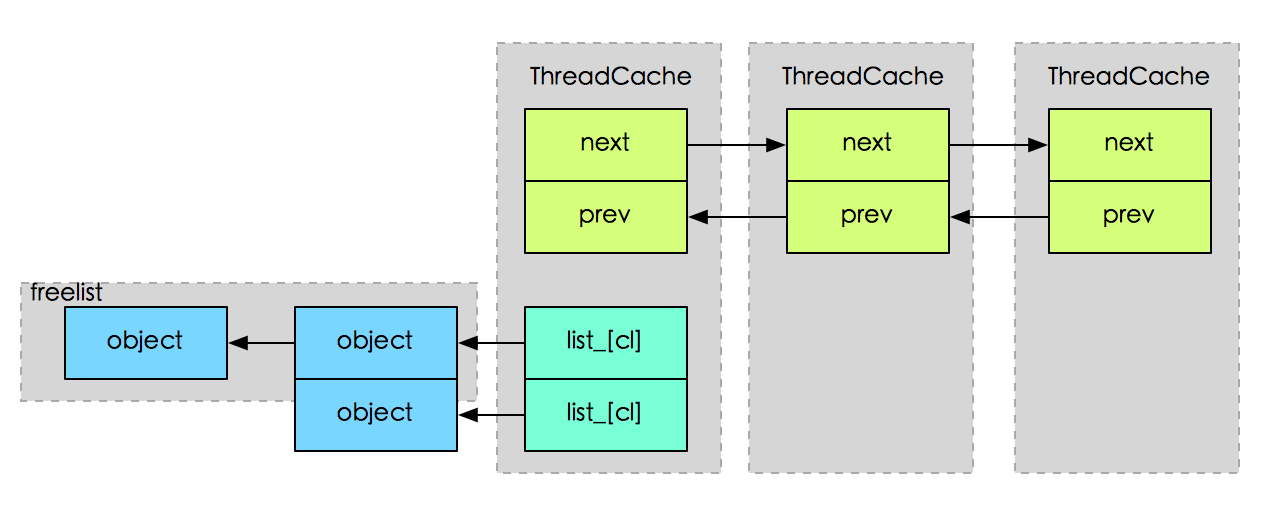
- ThreadCache
1)tcmalloc为每个线程创建一个ThreadCache对象,当线程结束的时候,ThreadCache对象会随之销毁。
2)ThreadCache为每种类型的内存都保存了一个单项链表。
(五)适用场景
tcmalloc适用线程内小内存分配需求,一般情况下只有大空间分配才使用中央堆,中央堆分配回收我记得是需要加锁,成本高。
(六)使用遇到的坑
在一个项目中,使用thrift的threadpool模型+上游短连接+tcmalloc时,性能大幅下降,大概只有使用普通malloc的1/10。
效果对比图如下:

但是同样是使用tcmalloc,在短连接+多线程or长连接+线程池场景下,性能却不受影响:
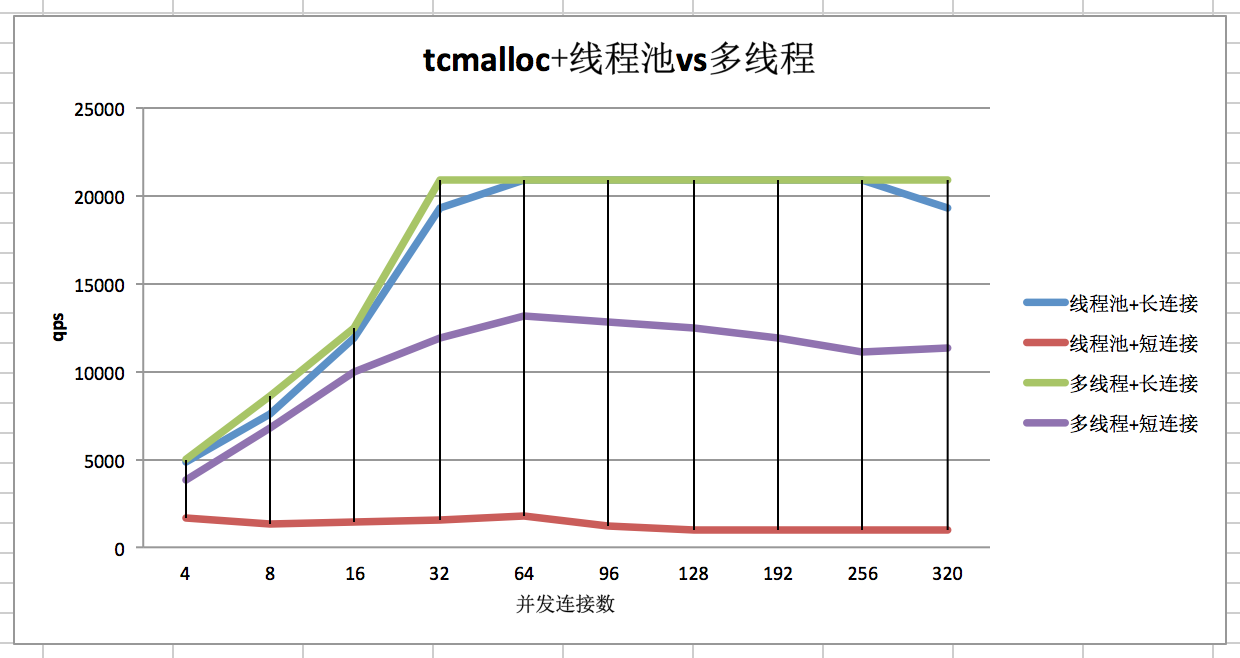
可以确定,是 tcmalloc+短连接+thrift线程池模型,才会出现这个坑。
使用oprofile工具对事件:1)分支预测错误;2)CPU时钟;3)指令数;4)L2缓存未命中 采样监控,观察服务一段时间,如下:
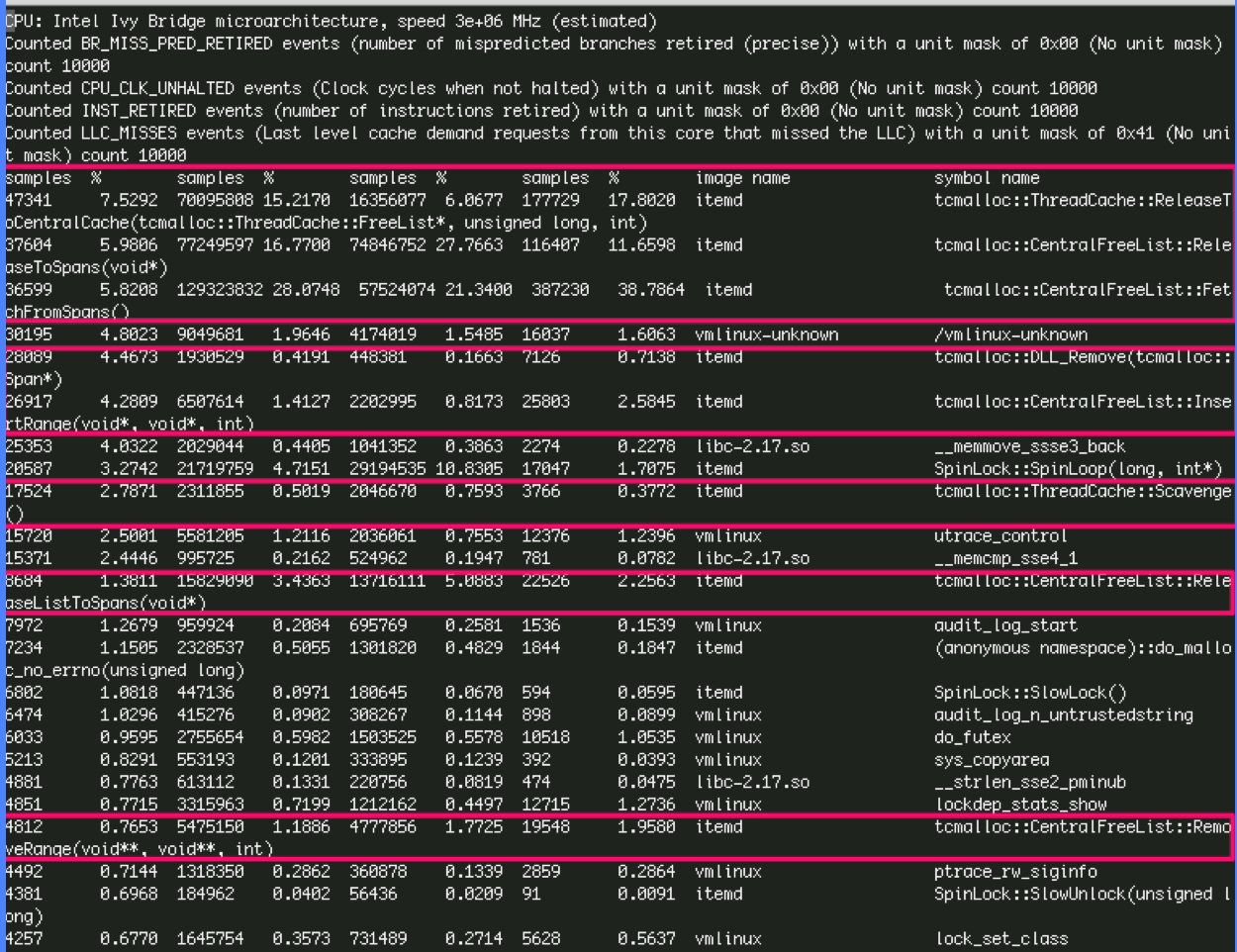
可以看到,CPU时钟占用的排序为:
tcmalloc::CentralFreeList::FetchFromSpans(spans->centralfreelist)、
tcmalloc::CentralFreeList::ReleaseToSpans(centralfreelist->spans)、
tcmalloc::ThreadCache::ReleaseToCentralCache(threadcache->centralcache)、
SpinLock::SpinLoop(分配pageheap时使用)、
tcmalloc::CentralFreeList::ReleaseListToSpans(centralfreelist->spans)
可以发现,服务过程中有频繁的CentralFreeList与PageHeap之间的内存申请and回收,而tcmalloc的PageHead申请是使用的spinlock锁,消耗大。