一.总述
1.定义:计算机网络是一些互相连接的、自治的计算机的集合。因特网是网络的网络。
2.分类:
根据作用范围分类:
广域网 WAN (Wide Area Network)
局域网 LAN (Local Area Network)
城域网 MAN (Metropolitan Area Network)
个人区域网 PAN (Personal Area Network)
根据使用者分类:
公用网 (public network)
专用网 (private network)
3.计算机网络的性能指标
速率:
速率即数据率(data rate)或比特率(bit rate)是计算机网络中最重要的一个性能指标。速率的单位是 b/s,或kb/s, Mb/s, Gb/s 等。
带宽:
“带宽”(bandwidth)本来是指信号具有的频带宽度,单位是赫(或千赫、兆赫、吉赫等)。
现在“带宽”是数字信道所能传送的“最高数据率”的同义语,单位是“比特每秒”,或 b/s (bit/s)。
吞吐量:
吞吐量(throughput)表示在单位时间内通过某个网络(或信道、接口)的数据量。
吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的
带宽或网络的额定速率的限制。
时延:
时延主要包括:发送时延、传播时延、处理时延、排队时延等。
利用率:
信道利用率指出某信道有百分之几的时间是被利用的(有数据通过)。完全空闲的信道的利用率是零。网络利用率则是全
网络的信道利用率的加权平均值。信道利用率并非越高越好。
4.计算机网络的层次结构
相互通信的两个计算机系统必须高度协调工作才行,而这种“协调”是相当复杂的。
“分层”可将庞大而复杂的问题,转化为若干较小的局部问题,而这些较小的局部问题就比较易于研究和处理。
现在有两种国际标准,一种是OSI标准,是法律上的标准,但是没有被市场认可。一种是事实上的标准TCP/IP标准。
协议与层次划分:
计算机网络中的数据交换必须遵守事先约定好的规则。 这些规则明确规定了所交换的数据的格式以及有关的同步问题
(同步含有时序的意思)。网络协议(network protocol),简称为协议,是为进行网络中的数据交换而建立的规则、标准或约定。
网络协议的组成要素:
语法 数据与控制信息的结构或格式 。
语义 需要发出何种控制信息,完成何种动作以及做出何种响应。
同步 事件实现顺序的详细说明。
五层协议的体系结构:
应用层(application layer)
运输层(transport layer)
网络层(network layer)
数据链路层(data link layer)
物理层(physical layer)
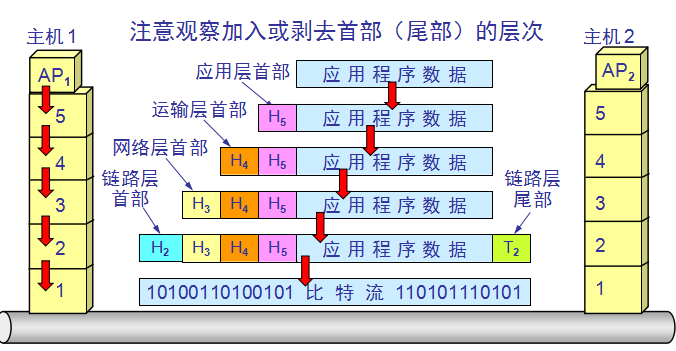
实体、协议、服务和服务访问点:
实体(entity) 表示任何可发送或接收信息的硬件或软件进程。
协议是控制两个对等实体进行通信的规则的集合。在协议的控制下,两个对等实体间的通信使得本层能够向上一层提供服务。
要实现本层协议,还需要使用下层所提供的服务。
本层的服务用户只能看见服务而无法看见下面的协议。
下面的协议对上面的服务用户是透明的。
协议是“水平的”,即协议是控制对等实体之间通信的规则。
服务是“垂直的”,即服务是由下层向上层通过层间接口提供的。
同一系统相邻两层的实体进行交互的地方,称为服务访问点 SAP (Service Access Point)。
TCP/IP体系结构:

二.物理层
1.物理层的主要任务描述为确定与传输媒体的接口的一些特性
机械特性:指明接口所用接线器的形状和尺寸、引线数目和排列、固定和锁定装置等等。
电气特性:指明在接口电缆的各条线上出现的电压的范围。
功能特性:指明某条线上出现的某一电平的电压表示何种意义。
过程特性:指明对于不同功能的各种可能事件的出现顺序。
2.相关术语及概念:
数据(data)——运送消息的实体。
信号(signal)——数据的电气的或电磁的表现。
“模拟的”(analogous)——代表消息的参数的取值是连续的。
“数字的”(digital)——代表消息的参数的取值是离散的。
码元(code)——在使用时间域(或简称为时域)的波形表示数字信号时,代表不同离散数值的基本波形。
单向通信(单工通信)——只能有一个方向的通信而没有反方向的交互。
双向交替通信(半双工通信)——通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
双向同时通信(全双工通信)——通信的双方可以同时发送和接收信息。
信噪比:
香农(Shannon)用信息论的理论推导出了带宽受限且有高斯白噪声干扰的信道的极限、无差错的信息传输速率。
信道的极限信息传输速率 C 可表达为
C = W log2(1+S/N) b/s
W 为信道的带宽(以 Hz 为单位);
S 为信道内所传信号的平均功率;
N 为信道内部的高斯噪声功率。
信道的带宽或信道中的信噪比越大,则信息的极限传输速率就越高。
只要信息传输速率低于信道的极限信息传输速率,就一定可以找到某种办法来实现无差错的传输。
若信道带宽 W 或信噪比 S/N 没有上限(当然实际信道不可能是这样的),则信道的极限信息传输速率 C 也就没有上限。
实际信道上能够达到的信息传输速率要比香农的极限传输速率低不少。
3.信道复用技术
信道复用技术有频分复用、时分复用、统计时分复用、码分复用、波分复用。
频分复用:用户在分配到一定的频带后,在通信过程中自始至终都占用这个频带。频分复用的所有用户在同样的时间占
用不同的带宽资源(请注意,这里的“带宽”是频率带宽而不是数据的发送速率)。
时分复用:时分复用则是将时间划分为一段段等长的时分复用帧(TDM 帧)。每一个时分复用的用户在每一个 TDM 帧
中占用固定序号的时隙。每一个用户所占用的时隙是周期性地出现(其周期就是 TDM 帧的长度)。TDM 信号也称为等
时(isochronous)信号。时分复用的所有用户是在不同的时间占用同样的频带宽度。
波分复用:波分复用就是光的频分复用。
码分复用:常用的名词是码分多址 CDMA (Code Division Multiple Access)。各用户使用经过特殊挑选的不同码型,因此彼
此不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。 每一个比特时间划
分为 m 个短的间隔,称为码片(chip)。
4.ADSL技术
ADSL 技术就是用数字技术对现有的模拟电话用户线进行改造,使它能够承载宽带业务。
标准模拟电话信号的频带被限制在 300~3400 Hz 的范围内,但用户线本身实际可通过的信号频率仍然超过 1 MHz。
ADSL 技术就把 0~4 kHz 低端频谱留给传统电话使用,而把原来没有被利用的高端频谱留给用户上网使用。
DSL 就是数字用户线(Digital Subscriber Line)的缩写。
三.数据链路层
1.数据链路层使用的信道主要有以下两种类型:
点对点信道:这种信道使用一对一的点对点通信方式。
广播信道:这种信道使用一对多的广播通信方式,因此过程比较复杂。广播信道上连接的主机很多,因此必须使用专用
的共享信道协议来协调这些主机的数据发送。
2.数据链路层的简单模型

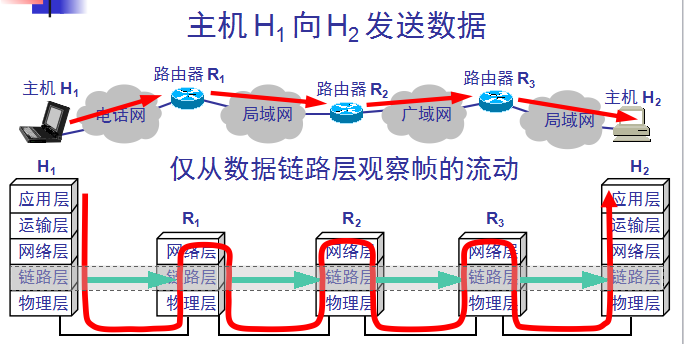
2.数据链路和帧
链路(link)是一条无源的点到点的物理线路段,中间没有任何其他的交换结点。一条链路只是一条通路的一个组成部分。
数据链路(data link) 除了物理线路外,还必须有通信协议来控制这些数据的传输。若把实现这些协议的硬件和软件加到链
路上,就构成了数据链路。现在最常用的方法是使用适配器(即网卡)来实现这些协议的硬件和软件。一般的适配器都包
括了数据链路层和物理层这两层的功能。
3.数据链路层的三个基本问题
(1) 封装成帧
封装成帧(framing)就是在一段数据的前后分别添加首部和尾部,然后就构成了一个帧。确定帧的界限。首部和尾部的一个
重要作用就是进行帧定界。
(2) 透明传输
透明传输问题是在一个数据帧中数据部分出现了和首部和尾部相同的数据。导致不能准确的进行帧定界。
解决办法:发送端的数据链路层在数据中出现控制字符“SOH”或“EOT”的前面插入一个转义字符“ESC”(其十六进制
编码是 1B)。
字节填充(byte stuffing)或字符填充(character stuffing)——接收端的数据链路层在将数据送往网络层之前删除插入的转义字符。
如果转义字符也出现数据当中,那么应在转义字符前面插入一个转义字符。当接收端收到连续的两个转义字符时,就删除其
中前面的一个。
(3) 差错控制
在传输过程中可能会产生比特差错:1 可能会变成 0 而 0 也可能变成 1。在一段时间内,传输错误的比特占所传输比特总数
的比率称为误码率 BER (Bit Error Rate)。误码率与信噪比有很大的关系。
为了保证数据传输的可靠性,在计算机网络传输数据时,必须采用各种差错检测措施。在数据链路层传送的帧中,广泛使用
了循环冗余检验 CRC 的检错技术。
5.点对点协议PPP
现在全世界使用得最多的数据链路层协议是点对点协议 PPP (Point-to-Point Protocol)。用户使用拨号电话线接入因特网时,一
般都是使用 PPP 协议。
PPP协议满足的需求:
简单——这是首要的要求
封装成帧
透明性
多种网络层协议
多种类型链路
差错检测
检测连接状态
最大传送单元
网络层地址协商
数据压缩协商
PPP协议不需要的功能:
纠错
流量控制
序号
多点线路
半双工或单工链路
PPP协议的三个组成部分:
一个将 IP 数据报封装到串行链路的方法。
链路控制协议 LCP (Link Control Protocol)。
网络控制协议 NCP (Network Control Protocol)。
PPP协议的帧格式:
PPP 是面向字节的,所有的 PPP 帧的长度都是整数字节。
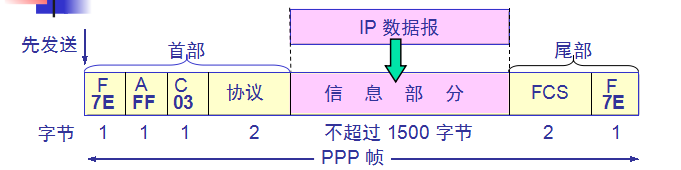
PPP协议的透明传输问题:
当 PPP 用在同步传输链路时,协议规定采用硬件来完成比特填充(和 HDLC 的做法一样)。
当 PPP 用在异步传输时,就使用一种特殊的字符填充法。
字符填充:
将信息字段中出现的每一个 0x7E 字节转变成为 2 字节序列(0x7D, 0x5E)。 若信息字段中出现一个 0x7D 的字节, 则将其
转变成为 2 字节序列(0x7D, 0x5D)。若信息字段中出现 ASCII 码的控制字符(即数值小于 0x20 的字符),则在该字符前
面要加入一个 0x7D 字节,同时将该字符的编码加以改变。
比特填充:
PPP 协议用在 SONET/SDH 链路时,是使用同步传输(一连串的比特连续传送)。这时 PPP 协议采用零比特填充方法来
实现透明传输。
在发送端,只要发现有 5 个连续 1,则立即填入一个 0。接收端对帧中的比特流进行扫描。每当发现 5 个连续1时,就把这
5 个连续 1 后的一个 0 删除。
PPP协议不提供序号和确认的可靠传输。原因:
在数据链路层出现差错的概率不大时,使用比较简单的 PPP 协议较为合理。在因特网环境下,PPP 的信息字段放入的数据
是 IP 数据报。数据链路层的可靠传输并不能够保证网络层的传输也是可靠的。帧检验序列 FCS 字段可保证无差错接受。
PPP协议的工作状态:
当用户拨号接入 ISP 时,路由器的调制解调器对拨号做出确认,并建立一条物理连接。PC 机向路由器发送一系列的 LCP 分
组(封装成多个 PPP 帧)。这些分组及其响应选择一些 PPP 参数,和进行网络层配置,NCP 给新接入的 PC机分配一个临
时的 IP 地址,使 PC 机成为因特网上的一个主机。通信完毕时,NCP 释放网络层连接,收回原来分配出去的 IP 地址。接
着,LCP 释放数据链路层连接。最后释放的是物理层的连接。
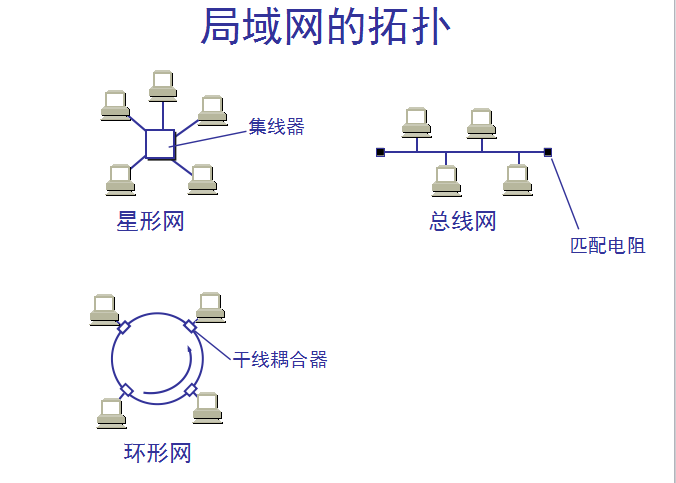
6.局域网
局域网最主要的特点是:网络为一个单位所拥有,且地理范围和站点数目均有限。局域网具有如下的一些主要优点:具有广
播功能,从一个站点可很方便地访问全网。局域网上的主机可共享连接在局域网上的各种硬件和软件资源。 便于系统的扩展
和逐渐地演变,各设备的位置可灵活调整和改变。提高了系统的可靠性、可用性和残存性。
局域网拓扑:
7.CSMA/CD协议
以太网的两种通信简便的措施:
采用较为灵活的无连接的工作方式,即不必先建立连接就可以直接发送数据。 以太网对发送的数据帧不进行编号,也不
要求对方发回确认。这样做的理由是局域网信道的质量很好,因信道质量产生差错的概率是很小的。
以太网提供的服务:
以太网提供的服务是不可靠的交付,即尽最大努力的交付。当目的站收到有差错的数据帧时就丢弃此帧,其他什么也不做。
差错的纠正由高层来决定。如果高层发现丢失了一些数据而进行重传,但以太网并不知道这是一个重传的帧,而是当作一个
新的数据帧来发送。
CSMA/CD(载波监听多点接入/碰撞检测)
“多点接入”表示许多计算机以多点接入的方式连接在一根总线上。
“载波监听”是指每一个站在发送数据之前先要检测一下总线上是否有其他计算机在发送数据,如果有,则暂时不要发送数据,
以免发生碰撞。
总线上并没有什么“载波”。因此, “载波监听”就是用电子技术检测总线上有没有其他计算机发送的数据信号。
“碰撞检测”就是计算机边发送数据边检测信道上的信号电压大小。
当几个站同时在总线上发送数据时,总线上的信号电压摆动值将会增大(互相叠加)。
当一个站检测到的信号电压摆动值超过一定的门限值时,就认为总线上至少有两个站同时在发送数据,表明产生了碰撞。
所谓“碰撞”就是发生了冲突。因此“碰撞检测”也称为“冲突检测”。
使用 CSMA/CD 协议的以太网不能进行全双工通信而只能进行双向交替通信(半双工通信)。每个站在发送数据之后的一小段
时间内,存在着遭遇碰撞的可能性。 这种发送的不确定性使整个以太网的平均通信量远小于以太网的最高数据率。
争用期:
最先发送数据帧的站,在发送数据帧后至多经过时间 2t(两倍的端到端往返时延)就可知道发送的数据帧是否遭受了碰撞。
以太网的端到端往返时延 2t称为争用期,或碰撞窗口。经过争用期这段时间还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
二进制指数类型退避算法
发生碰撞的站在停止发送数据后,要推迟(退避)一个随机时间才能再发送数据。
基本退避时间取为争用期 2t。
从整数集合[0,1,…, (2k -1)]中随机地取出一个数,记为 r。重传所需的时延就是 r 倍的基本退避时间。
参数 k 按下面的公式计算:
k = Min[重传次数, 10]
当 k <=10 时,参数 k 等于重传次数。
当重传达 16 次仍不能成功时即丢弃该帧,并向高层报告。
争用期的长度:
以太网取 51.2 us 为争用期的长度。
对于 10 Mb/s 以太网,在争用期内可发送512 bit,即 64 字节。
以太网在发送数据时,若前 64 字节没有发生冲突,则后续的数据就不会发生冲突。
最短有效帧长:
如果发生冲突,就一定是在发送的前 64 字节之内。 由于一检测到冲突就立即中止发送,这时已经发送出去的数据
一定小于 64 字节。
以太网规定了最短有效帧长为 64 字节,凡长度小于 64 字节的帧都是由于冲突而异常中止的无效帧。
以太网的MAC层:
在局域网中,硬件地址又称为物理地址,或 MAC 地址。
以太网的帧格式:
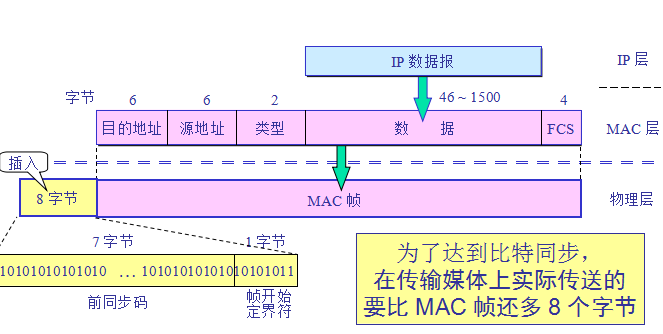
用集线器扩展局域网:
优点:使原来属于不同碰撞域的局域网上的计算机能够进行跨碰撞域的通信。扩大了局域网覆盖的地理范围。
缺点:碰撞域增大了,但总的吞吐量并未提高。如果不同的碰撞域使用不同的数据率,那么就不能用集线器将它们互连起来。
在数据链路层扩展局域网:
在数据链路层扩展局域网是使用网桥。网桥工作在数据链路层,它根据 MAC 帧的目的地址对收到的帧进行转发。网桥具有
过滤帧的功能。当网桥收到一个帧时,并不是向所有的接口转发此帧,而是先检查此帧的目的 MAC 地址,然后再确定将该
帧转发到哪一个接口 。
在数据链路层扩展局域网是使用网桥。网桥工作在数据链路层,它根据 MAC 帧的目的地址对收到的帧进行转发。网桥具有过
滤帧的功能。当网桥收到一个帧时,并不是向所有的接口转发此帧,而是先检查此帧的目的 MAC 地址,然后再确定将该帧转
发到哪一个接口 。
网桥的自学习算法:
网桥收到一帧后先进行自学习。查找转发表中与收到帧的源地址有无相匹配的项目。
如没有,就在转发表中增加一个项目(源地址、进入的接口和时间)。如有,则把原有的项目进行更新。
转发帧:查找转发表中与收到帧的目的地址有无相匹配的项目。
如没有,则通过所有其他接口(但进入网桥的接口除外)进行转发。
如有,则按转发表中给出的接口进行转发。
若转发表中给出的接口就是该帧进入网桥的接口,则应丢弃这个帧(因为这时不需要经过网桥进行转发)。
以太网交换机:
以太网交换机的每个接口都直接与主机相连,并且一般都工作在全双工方式。交换机能同时连通许多对的接口,
使每一对相互通信的主机都能像独占通信媒体那样,进行无碰撞地传输数据。 以太网交换机由于使用了专用的
交换结构芯片,其交换速率就较高。
对于普通 10 Mb/s 的共享式以太网,若共有 N 个用户,则每个用户占有的平均带宽只有总带宽(10 Mb/s)的 N 分之一。
使用以太网交换机时,虽然在每个接口到主机的带宽还是 10 Mb/s,但由于一个用户在通信时是独占而不是和其他网
络用户共享传输媒体的带宽,因此对于拥有 N 对接口的交换机的总容量为 N´10 Mb/s。这正是交换机的最大优点。
虚拟局域网VLAN:
虚拟局域网 VLAN 是由一些局域网网段构成的与物理位置无关的逻辑组。这些网段具有某些共同的需求。每一个 VLAN
的帧都有一个明确的标识符,指明发送这个帧的工作站是属于哪一个VLAN。虚拟局域网其实只是局域网给用户提供的一
种服务,而并不是一种新型局域网。
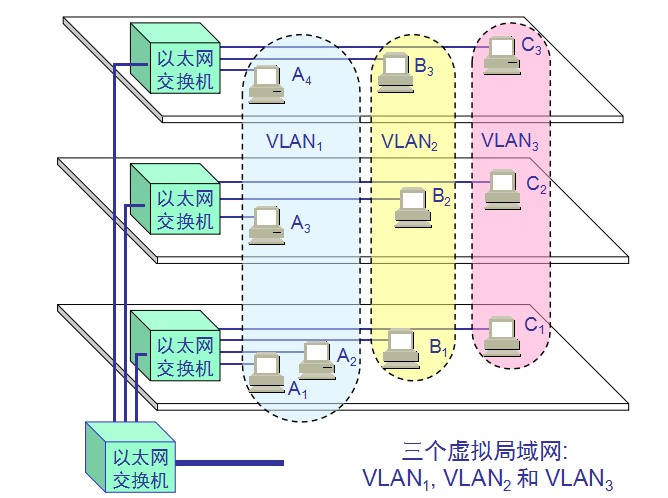
虚拟局域网协议允许在以太网的帧格式中插入一个 4 字节的标识符,称为 VLAN 标记(tag),
用来指明发送该帧的工作站属于哪一个虚拟局域网。
四.网络层
1.网络层提供的服务
网络层向上只提供简单灵活的、无连接的、尽最大努力交付的数据报服务。

2.网际协议IP
网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一。与 IP 协议配套使用的还有三个协议:
地址解析协议 ARP(Address Resolution Protocol)
网际控制报文协议 ICMP (Internet Control Message Protocol)
网际组管理协议 IGMP (Internet Group Management Protocol)
连接网络所使用的中间设备:
物理层中继系统:转发器(repeater)。
数据链路层中继系统:网桥或桥接器(bridge)。
网络层中继系统:路由器(router)。
网桥和路由器的混合物:桥路器(brouter)。
网络层以上的中继系统:网关(gateway)。
IP地址:
IP 地址就是给每个连接在因特网上的主机(或路由器)分配一个在全世界范围是唯一的 32 位的标识符。
IP地址的编址方法。:
分类的 IP 地址:这是最基本的编址方法,在 1981 年就通过了相应的标准协议。
子网的划分:这是对最基本的编址方法的改进,其标准[RFC 950]在 1985 年通过。
构成超网:这是比较新的无分类编址方法。1993 年提出后很快就得到推广应用。
1)分类的IP地址:
每一类地址都由两个固定长度的字段组成,其中一个字段是网络号 net-id,它标志主机(或路由器)所连接到的网络,
而另一个字段则是主机号 host-id,它标志该主机(或路由器)。
两级的 IP 地址可以记为:
IP 地址 ::= { <网络号>, <主机号>}

2)地址解析协议: 不管网络层使用的是什么协议,在实际网络的链路上传送数据帧时,最终还是必须使用硬件地址。
每一个主机都设有一个 ARP 高速缓存(ARP cache),里面有所在的局域网上的各主机和路由器的 IP 地址到硬件地址的映射表。
当主机 A 欲向本局域网上的某个主机 B 发送 IP 数据报时,就先在其 ARP 高速缓存中查看有无主机 B 的 IP 地址。如有,
就可查出其对应的硬件地址,再将此硬件地址写入 MAC 帧,然后通过局域网将该 MAC 帧发往此硬件地址。
为什么不直接用MAC地址进行通信?
由于全世界存在着各式各样的网络,它们使用不同的硬件地址。要使这些异构网络能够互相通信就必须进行非常复杂的硬件地址
转换工作,因此几乎是不可能的事。连接到因特网的主机都拥有统一的 IP 地址,它们之间的通信就像连接在同一个网络上那样简
单方便,因为调用 ARP 来寻找某个路由器或主机的硬件地址都是由计算机软件自动进行的,对用户来说是看不见这种调用过程的。
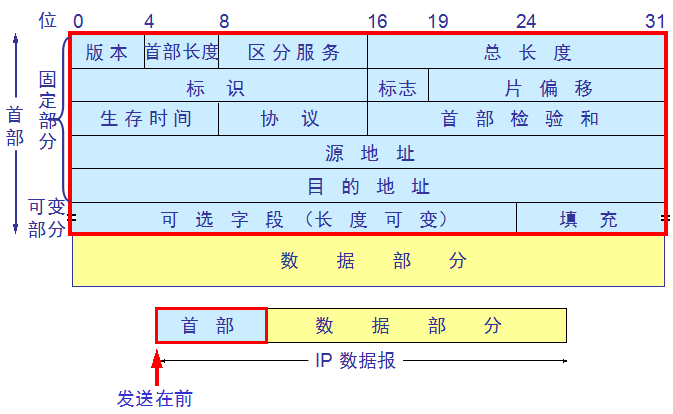
3)IP数据报
一个 IP 数据报由首部和数据两部分组成。首部的前一部分是固定长度,共 20 字节,是所有 IP 数据报必须具有的。在首部的固定
部分的后面是一些可选字段,其长度是可变的。
3)IP分组转发的流程
需要注意的问题:
IP 数据报的首部中没有地方可以用来指明“下一跳路由器的 IP 地址”。当路由器收到待转发的数据报,不是将下一跳路
由器的 IP 地址填入 IP 数据报,而是送交下层的网络接口软件。网络接口软件使用 ARP 负责将下一跳路由器的 IP 地址
转换成硬件地址,并将此硬件地址放在链路层的 MAC 帧的首部,然后根据这个硬件地址找到下一跳路由器。
分组转发算法 :
(1) 从数据报的首部提取目的主机的 IP 地址 D, 得出目的网络地址为 N。
(2) 若网络 N 与此路由器直接相连,则把数据报直接交付目的主机 D;否则是间接交付,执行(3)。
(3) 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行(4)。
(4) 若路由表中有到达网络 N 的路由,则把数据报传送给路由表指明的下一跳路由器;否则,执行(5)。
(5) 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则,执行(6)。
(6) 报告转发分组出错。
4)划分子网和构造超网
划分子网:
划分子网纯属一个单位内部的事情。单位对外仍然表现为没有划分子网的网络。
从主机号借用若干个位作为子网号 subnet-id,而主机号 host-id 也就相应减少了若干个位。
IP地址 ::= {<网络号>, <子网号>, <主机号>}
划分子网的基本思路:
凡是从其他网络发送给本单位某个主机的 IP 数据报,仍然是根据 IP 数据报的目的网络号 net-id,先找到连接在本单
位网络上的路由器。然后此路由器在收到 IP 数据报后,再按目的网络号 net-id 和子网号 subnet-id 找到目的子网。最后
就将 IP 数据报直接交付目的主机。
当没有划分子网时,IP 地址是两级结构。划分子网后 IP 地址就变成了三级结构。划分子网只是把 IP 地址的主机号 host-id
这部分进行再划分,而不改变 IP 地址原来的网络号 net-id。
从一个 IP 数据报的首部并无法判断源主机或目的主机所连接的网络是否进行了子网划分。使用子网掩码(subnet mask)可以
找出 IP 地址中的子网部分。
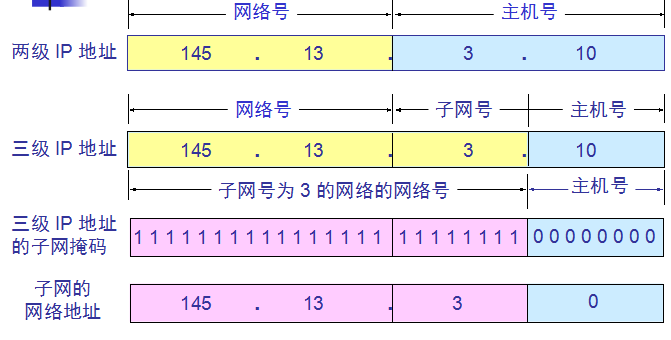
使用子网掩码的分组转发过程:
在划分子网的情况下路由器转发分组的算法:
(1) 从收到的分组的首部提取目的 IP 地址 D。
(2) 先用各网络的子网掩码和 D 逐位相“与”,看是否和相应的网络地址匹配。若匹配,则将分组直接交付。
否则就是间接交付,执行(3)。
(3) 若路由表中有目的地址为 D 的特定主机路由,则将分组传送给指明的下一跳路由器;否则,执行(4)。
(4) 对路由表中的每一行的子网掩码和 D 逐位相“与”,若其结果与该行的目的网络地址匹配,则将分组
传送给该行指明的下一跳路由器;否则,执行(5)。
(5) 若路由表中有一个默认路由,则将分组传送给路由表中所指明的默认路由器;否则,执行(6)。
(6) 报告转发分组出错。
5)无分类的编址CIDR
CIDR 消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,因而可以更加有效地分配 IPv4 的地址空间。
CIDR使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号。IP 地址从三级编址(
使用子网掩码)又回到了两级编址。
IP地址 ::= {<网络前缀>, <主机号>}
CIDR 还使用“斜线记法”(slash notation),它又称为CIDR记法,即在 IP 地址面加上一个斜线“/”,然后写上
网络前缀所占的位数(这个数值对应于三级编址中子网掩码中 1 的个数)。CIDR 把网络前缀都相同的连续的
IP 地址组成“CIDR 地址块”。
128.14.32.0/20 表示的地址块共有 212 个地址(因为斜线后面的 20 是网络前缀的位数,所以这个地址的
主机号是 12 位)。这个地址块的起始地址是 128.14.32.0。在不需要指出地址块的起始地址时,也可将这样的地址
块简称为“/20 地址块”。128.14.32.0/20 地址块的最小地址:128.14.32.0,128.14.32.0/20 地址块的最大地址:
128.14.47.255。全 0 和全 1 的主机号地址一般不使用。
构成超网:
前缀长度不超过 23 位的 CIDR 地址块都包含了多个 C 类地址。这些 C 类地址合起来就构成了超网。CIDR
地址块中的地址数一定是 2 的整数次幂。网络前缀越短,其地址块所包含的地址数就越多。而在三级结构的IP
地址中,划分子网是使网络前缀变长。
最长前缀匹配:
使用 CIDR 时,路由表中的每个项目由“网络前缀”和“下一跳地址”组成。在查找路由表时可能会得到不止
一个匹配结果。 应当从匹配结果中选择具有最长网络前缀的路由:最长前缀匹配(longest-prefix matching)。
网络前缀越长,其地址块就越小,因而路由就越具体(more specific) 。最长前缀匹配又称为最长匹配或最佳匹配。
3.网际控制报文协议 ICMP
为了提高 IP 数据报交付成功的机会,在网际层使用了网际控制报文协议 ICMP (Internet Control Message Protocol)。
ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告。ICMP 不是高层协议,而是 IP 层的协议。
ICMP 报文作为 IP 层数据报的数据,加上数据报的首部,组成 IP 数据报发送出去。
ICMP 报文的种类有两种,即 ICMP 差错报告报文和 ICMP 询问报文。 ICMP 报文的前 4 个字节是统一的格式,
共有三个字段:即类型、代码和检验和。接着的 4 个字节的内容与 ICMP 的类型有关。
ICMP差错报告报文:
终点不可达
源点抑制(Source quench)
时间超过
参数问题
改变路由(重定向)(Redirect)
不应发送 ICMP 差错报告报文的几种情况:
对 ICMP 差错报告报文不再发送 ICMP 差错报告报文。
对第一个分片的数据报片的所有后续数据报片都不发送 ICMP 差错报告报文。
对具有多播地址的数据报都不发送 ICMP 差错报告报文。
对具有特殊地址(如127.0.0.0 或 0.0.0.0)的数据报不发送 ICMP 差错报告报文。
ICMP询问报文:
回送请求和回答报文
时间戳请求和回答报文
PING 用来测试两个主机之间的连通性。PING 使用了 ICMP 回送请求与回送回答报文。PING 是应用层直接使用
网络层 ICMP 的例子,它没有通过运输层的 TCP 或UDP。
4.路由选择协议
因特网有两大类路由选择协议:
内部网关协议 IGP (Interior Gateway Protocol) 即在一个自治系统内部使用的路由选择协议。目前这类路由选
择协议使用得最多,如 RIP 和 OSPF 协议。
外部网关协议EGP (External Gateway Protocol) 若源站和目的站处在不同的自治系统中,当数据报传到一个自治
系统的边界时,就需要使用一种协议将路由选择信息传递到另一个自治系统中。这样的协议就是外部网关协议
EGP。在外部网关协议中目前使用最多的是 BGP-4。
1)RIP协议
工作原理:
路由信息协议 RIP 是内部网关协议 IGP中最先得到广泛使用的协议。RIP 是一种分布式的基于距离向量的路由选
择协议。RIP 协议要求网络中的每一个路由器都要维护从它自己到其他每一个目的网络的距离记录。
距离的解释:从一路由器到直接连接的网络的距离定义为 1。从一个路由器到非直接连接的网络的距离定义为所
经过的路由器数加 1。RIP 协议中的“距离”也称为“跳数”(hop count),因为每经过一个路由器,跳数就加 1。
这里的“距离”实际上指的是“最短距离”。
RIP 认为一个好的路由就是它通过的路由器的数目少,即“距离短”。
RIP 允许一条路径最多只能包含 15 个路由器。“距离”的最大值为16 时即相当于不可达。可见 RIP 只适用于
小型互联网。RIP 不能在两个网络之间同时使用多条路由。RIP 选择一个具有最少路由器的路由(即最短路由)
,哪怕还存在另一条高速(低时延)但路由器较多的路由。
三个要点:
仅和相邻路由器交换信息。
交换的信息是当前本路由器所知道的全部信息,即自己的路由表。
按固定的时间间隔交换路由信息,例如,每隔 30 秒。
距离向量算法:
收到相邻路由器(其地址为 X)的一个 RIP 报文:
(1) 先修改此 RIP 报文中的所有项目:把“下一跳”字段中的地址都改为 X,并把所有的“距离”字段的值加 1。
(2) 对修改后的 RIP 报文中的每一个项目,重复以下步骤:
若项目中的目的网络不在路由表中,则把该项目加到路由表中。
否则若下一跳字段给出的路由器地址是同样的,则把收到的项目替换原路由表中的项目。否则若收到项目中的距
离小于路由表中的距离,则进行更新,否则,什么也不做。
(3) 若 3 分钟还没有收到相邻路由器的更新路由表,则把此相邻路由器记为不可达路由器,即将距离置为16(距
离为16表示不可达)。
(4) 返回。
RIP协议的优缺点:
RIP 存在的一个问题是当网络出现故障时,要经过比较长的时间才能将此信息传送到所有的路由器。
RIP 协议最大的优点就是实现简单,开销较小。
RIP 限制了网络的规模,它能使用的最大距离为 15(16 表示不可达)。路由器之间交换的路由信息是路由器中
的完整路由表,因而随着网络规模的扩大,开销也就增加。
2)内部网关协议 OSPF(Open Shortest Path First)
OSPF 协议的基本特点:
“开放”表明 OSPF 协议不是受某一家厂商控制,而是公开发表的。
“最短路径优先”是因为使用了 Dijkstra 提出的最短路径算法SPF
OSPF 只是一个协议的名字,它并不表示其他的路由选择协议不是“最短路径优先”。是分布式的链路状态协议。
三个要点:
向本自治系统中所有路由器发送信息,这里使用的方法是洪泛法。
发送的信息就是与本路由器相邻的所有路由器的链路状态,但这只是路由器所知道的部分信息。“链路状态”就
是说明本路由器都和哪些路由器相邻,以及该链路的“度量”(metric)。
只有当链路状态发生变化时,路由器才用洪泛法向所有路由器发送此信息。
链路状态数据库:
由于各路由器之间频繁地交换链路状态信息,因此所有的路由器最终都能建立一个链路状态数据库。
这个数据库实际上就是全网的拓扑结构图,它在全网范围内是一致的(这称为链路状态数据库的同步)。
OSPF 的链路状态数据库能较快地进行更新,使各个路由器能及时更新其路由表。OSPF 的更新过程收敛得快是
其重要优点。
OSPF 不用 UDP 而是直接用 IP 数据报传送。
OSPF 构成的数据报很短。这样做可减少路由信息的通信量。
数据报很短的另一好处是可以不必将长的数据报分片传送。分片传送的数据报只要丢失一个,就无法组装成原来
的数据报,而整个数据报就必须重传。
OSPF的其他特点:
OSPF 对不同的链路可根据 IP 分组的不同服务类型 TOS 而设置成不同的代价。因此,OSPF 对于不同类型的业
务可计算出不同的路由。
如果到同一个目的网络有多条相同代价的路径,那么可以将通信量分配给这几条路径。这叫作多路径间的负载平衡。
所有在 OSPF 路由器之间交换的分组都具有鉴别的功能。
支持可变长度的子网划分和无分类编址 CIDR。
每一个链路状态都带上一个 32 位的序号,序号越大状态就越新。
由于一个路由器的链路状态只涉及到与相邻路由器的连通状态,因而与整个互联网的规模并无直接关系。因此当
互联网规模很大时,OSPF 协议要比距离向量协议 RIP 好得多。
OSPF 没有“坏消息传播得慢”的问题,据统计,其响应网络变化的时间小于 100 ms。
3)外部网关协议 BGP
BGP 是不同自治系统的路由器之间交换路由信息的协议。边界网关协议 BGP 只能是力求寻找一条能够到达目的
网络且比较好的路由(不能兜圈子),而并非要寻找一条最佳路由。
BGP发言人:每一个自治系统的管理员要选择至少一个路由器作为该自治系统的“ BGP 发言人” 。一般说来,
两个 BGP 发言人都是通过一个共享网络连接在一起的,而 BGP 发言人往往就是 BGP 边界路由器,但也可以不
是 BGP 边界路由器。
BGP交换路由信息:
一个 BGP 发言人与其他自治系统中的 BGP 发言人要交换路由信息,就要先建立 TCP 连接,然后在此连接上交换
BGP 报文以建立 BGP 会话(session),利用 BGP 会话交换路由信息。使用 TCP 连接能提供可靠的服务,也简化了
路由选择协议。使用 TCP 连接交换路由信息的两个 BGP 发言人,彼此成为对方的邻站或对等站。
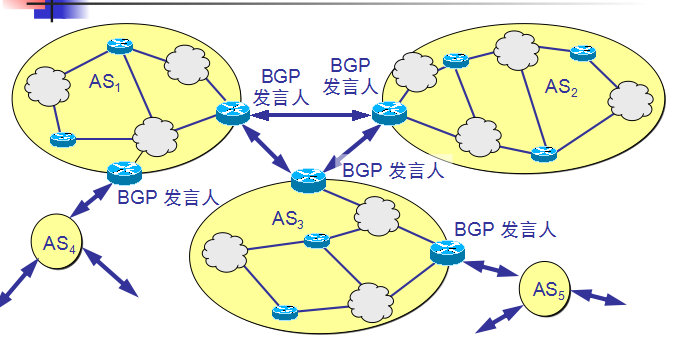
OSPF协议的特点:
BGP 支持 CIDR,因此 BGP 的路由表也就应当包括目的网络前缀、下一跳路由器,以及到达该目的网络所
要经过的各个自治系统序列。
在BGP 刚刚运行时,BGP 的邻站是交换整个的 BGP 路由表。但以后只需要在发生变化时更新有变化的部分。
这样做对节省网络带宽和减少路由器的处理开销方面都有好处。
2)路由器在网际互连中的作用
路由器的结构:
路由器是一种具有多个输入端口和多个输出端口的专用计算机,其任务是转发分组。也就是说,将路由器某
个输入端口收到的分组,按照分组要去的目的地(即目的网络),把该分组从路由器的某个合适的输出端口
转发给下一跳路由器。下一跳路由器也按照这种方法处理分组,直到该分组到达终点为止。
转发和路由选择的区别:
“转发”(forwarding)就是路由器根据转发表将用户的 IP 数据报从合适的端口转发出去。
“路由选择”(routing)则是按照分布式算法,根据从各相邻路由器得到的关于网络拓扑的变化情况,动态地改变
所选择的路由。
路由表是根据路由选择算法得出的。而转发表是从路由表得出的。
在讨论路由选择的原理时,往往不去区分转发表和路由表的区别。
3)IP多播
(1) 多播使用组地址—— IP 使用 D 类地址支持多播。多播地址只能用于目的地址,而不能用于源地址。
(2) 永久组地址——由因特网号码指派管理局 IANA 负责指派。
(3) 动态的组成员
(4) 使用硬件进行多播
网际组管理协议 IGMP
和 ICMP 相似,IGMP 使用 IP 数据报传递其报文(即 IGMP 报文加上 IP 首部构成 IP 数据报),但它也向
IP 提供服务。因此,我们不把 IGMP 看成是一个单独的协议,而是属于整个网际协议 IP 的一个组成部分。
第一阶段:当某个主机加入新的多播组时,该主机应向多播组的多播地址发送IGMP 报文,声明自己要成为
该组的成员。本地的多播路由器收到 IGMP 报文后,将组成员关系转发给因特网上的其他多播路由器。
第二阶段:因为组成员关系是动态的,因此本地多播路由器要周期性地探询本地局域网上的主机,以便知
道这些主机是否还继续是组的成员。
只要对某个组有一个主机响应,那么多播路由器就认为这个组是活跃的。
但一个组在经过几次的探询后仍然没有一个主机响应,则不再将该组的成员关系转发给其他的多播路由器。
4)虚拟专用网 VPN 和网络地址转换 NAT
本地地址——仅在机构内部使用的 IP 地址,可以由本机构自行分配,而不需要向因特网的管理机构申请。
全球地址——全球唯一的IP地址,必须向因特网的管理机构申请。
本地专用地址:
10.0.0.0 到 10.255.255.255
172.16.0.0 到 172.31.255.255
192.168.0.0 到 192.168.255.255
这些地址只能用于一个机构的内部通信,而不能用于和因特网上的主机通信。专用地址只能用作本地地址
而不能用作全球地址。在因特网中的所有路由器对目的地址是专用地址的数据报一律不进行转发。
内联网 intranet 和外联网 extranet(都是基于 TCP/IP 协议)
由部门 A 和 B 的内部网络所构成的虚拟专用网 VPN 又称为内联网(intranet),表示部门 A 和 B 都是在
同一个机构的内部。
一个机构和某些外部机构共同建立的虚拟专用网 VPN 又称为外联网(extranet)。
网络地址转换 NAT:
需要在专用网连接到因特网的路由器上安装 NAT 软件。装有 NAT 软件的路由器叫做 NAT路由器,它至
少有一个有效的外部全球地址 IPG。
所有使用本地地址的主机在和外界通信时都要在 NAT 路由器上将其本地地址转换成 IPG 才能和因特网连接。
内部主机 X 用本地地址 IPX 和因特网上主机 Y 通信所发送的数据报必须经过 NAT 路由器。
NAT 路由器将数据报的源地址 IPX 转换成全球地址 IPG,但目的地址 IPY 保持不变,然后发送到因特网。
NAT 路由器收到主机 Y 发回的数据报时,知道数据报中的源地址是 IPY 而目的地址是 IPG。
根据 NAT 转换表,NAT 路由器将目的地址 IPG 转换为 IPX,转发给最终的内部主机 X。
五.运输层
TCP/IP 的运输层有两个不同的协议:
(1) 用户数据报协议 UDP (User Datagram Protocol)
(2) 传输控制协议 TCP(Transmission Control Protocol)
两个对等运输实体在通信时传送的数据单位叫作运输协议数据单元 TPDU (Transport Protocol Data Unit)。
TCP 传送的数据单位协议是 TCP 报文段(segment)
UDP 传送的数据单位协议是 UDP 报文或用户数据报。
运输层的协议:
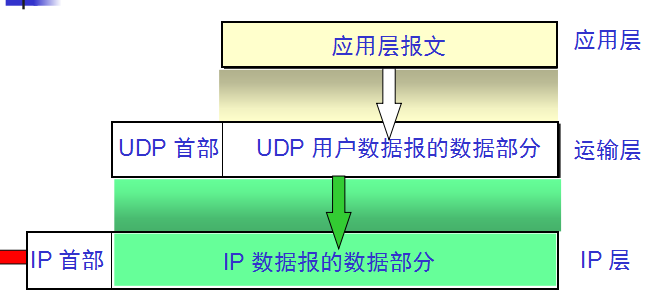
UDP 在传送数据之前不需要先建立连接。对方的运输层在收到 UDP 报文后,不需要给出任何确认。虽然
UDP 不提供可靠交付,但在某些情况下 UDP 是一种最有效的工作方式。
TCP 则提供面向连接的服务。TCP 不提供广播或多播服务。由于 TCP 要提供可靠的、面向连接的运输
服务,因此不可避免地增加了许多的开销。这不仅使协议数据单元的首部增大很多,还要占用许多的处理机资源。
运输层的 UDP 用户数据报与网际层的IP数据报有很大区别。IP 数据报要经过互连网中许多路由器的存储
转发,但 UDP 用户数据报是在运输层的端到端抽象的逻辑信道中传送的。
TCP 报文段是在运输层抽象的端到端逻辑信道中传送,这种信道是可靠的全双工信道。但这样的信道却不知
道究竟经过了哪些路由器,而这些路由器也根本不知道上面的运输层是否建立了 TCP 连接。
软件端口与硬件端口:
在协议栈层间的抽象的协议端口是软件端口。路由器或交换机上的端口是硬件端口。硬件端口是不同硬件设备
进行交互的接口,而软件端口是应用层的各种协议进程与运输实体进行层间交互的一种地址。
三类端口:
熟知端口,数值一般为 0~1023。
登记端口号,数值为1024~49151,为没有熟知端口号的应用程序使用的。使用这个范围的端口号必须在 IANA
登记,以防止重复。
客户端口号或短暂端口号,数值为49152~65535,留给客户进程选择暂时使用。当服务器进程收到客户进程的报
文时,就知道了客户进程所使用的动态端口号。通信结束后,这个端口号可供其他客户进程以后使用。
UDP概述:
UDP 只在 IP 的数据报服务之上增加了很少一点的功能,即端口的功能和差错检测的功能。虽然 UDP 用户
数据报只能提供不可靠的交付,但 UDP 在某些方面有其特殊的优点。
UDP的主要特点:
UDP 是无连接的,即发送数据之前不需要建立连接。
UDP 使用尽最大努力交付,即不保证可靠交付,同时也不使用拥塞控制。
UDP 是面向报文的。UDP 没有拥塞控制,很适合多媒体通信的要求。
UDP 支持一对一、一对多、多对一和多对多的交互通信。
UDP 的首部开销小,只有 8 个字节。
发送方 UDP 对应用程序交下来的报文,在添加首部后就向下交付 IP 层。UDP 对应用层交下来的报文,既不合
并,也不拆分,而是保留这些报文的边界。
应用层交给 UDP 多长的报文,UDP 就照样发送,即一次发送一个报文。
接收方 UDP 对 IP 层交上来的 UDP 用户数据报,在去除首部后就原封不动地交付上层的应用进程,一次交付
一个完整的报文。
应用程序必须选择合适大小的报文。
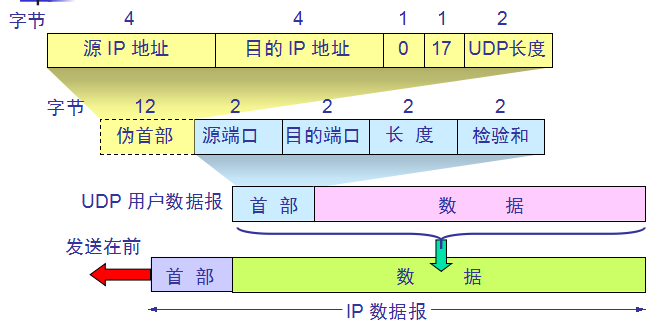
UDP首部格式:
TCP概述:
TCP 是面向连接的运输层协议。每一条 TCP 连接只能有两个端点(endpoint),每一条 TCP 连接只能是点对点的
(一对一)。 TCP 提供可靠交付的服务。 TCP 提供全双工通信。面向字节流。
TCP 连接是一条虚连接而不是一条真正的物理连接。TCP 对应用进程一次把多长的报文发送到TCP 的缓存中是不
关心的。TCP 根据对方给出的窗口值和当前网络拥塞的程度来决定一个报文段应包含多少个字节(UDP 发送的报
文长度是应用进程给出的)。TCP 可把太长的数据块划分短一些再传送。TCP 也可等待积累有足够多的字节后再构
成报文段发送出去。
TCP 把连接作为最基本的抽象。每一条 TCP 连接有两个端点。TCP 连接的端点不是主机,不是主机的IP 地址,不
是应用进程,也不是运输层的协议端口。TCP 连接的端点叫做套接字(socket)或插口。
端口号拼接到(contatenated with) IP 地址即构成了套接字。
套接字 socket = (IP地址: 端口号)
TCP 连接 ::= {socket1, socket2} = {(IP1: port1), (IP2: port2)}
Socket的不同含义:
应用编程接口 API 称为 socket API, 简称为 socket。
socket API 中使用的一个函数名也叫作 socket。
调用 socket 函数的端点称为 socket。
调用 socket 函数时其返回值称为 socket 描述符,可简称为 socket。
在操作系统内核中连网协议的 Berkeley 实现,称为 socket 实现。
在发送完一个分组后,必须暂时保留已发送的分组的副本。分组和确认分组都必须进行编号。超时计时器的重传时间
应当比数据在分组传输的平均往返时间更长一些。
可靠通信的实现:
使用上述的确认和重传机制,我们就可以在不可靠的传输网络上实现可靠的通信。
这种可靠传输协议常称为自动重传请求ARQ (Automatic Repeat reQuest)。ARQ 表明重传的请求是自动进行的。接收方
不需要请求发送方重传某个出错的分组 。
积累确认:接收方一般采用累积确认的方式。即不必对收到的分组逐个发送确认,而是对按序到达的最后一个分组发
送确认,这样就表示:到这个分组为止的所有分组都已正确收到了。累积确认有的优点是:容易实现,即使确认丢失
也不必重传。缺点是:不能向发送方反映出接收方已经正确收到的所有分组的信息。
TCP可靠通信的具体实现:
TCP 连接的每一端都必须设有两个窗口,一个发送窗口和一个接收窗口。TCP 的可靠传输机制用字节的序号进行控制。
TCP 所有的确认都是基于序号而不是基于报文段。TCP 两端的四个窗口经常处于动态变化之中。TCP连接的往返时间
RTT 也不是固定不变的。需要使用特定的算法估算较为合理的重传时间。
TCP报文段:
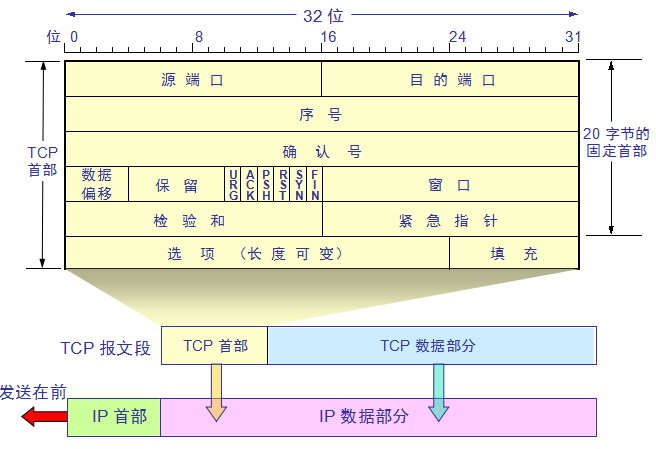
源端口和目的端口字段——各占 2 字节。端口是运输层与应用层的服务接口。运输层的复用和分用功能都要通过
端口才能实现。
序号字段——占 4 字节。TCP 连接中传送的数据流中的每一个字节都编上一个序号。序号字段的值则指的是本报
文段所发送的数据的第一个字节的序号。
确认号字段——占 4 字节,是期望收到对方的下一个报文段的数据的第一个字节的序号。
数据偏移(即首部长度)——占 4 位,它指出 TCP 报文段的数据起始处距离 TCP 报文段的起始处有多远。“
数据偏移”的单位是 32 位字(以 4 字节为计算单位)。
保留字段——占 6 位,保留为今后使用,但目前应置为 0。
紧急 URG —— 当 URG =1 时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应尽快传送(相当
于高优先级的数据)。
确认 ACK —— 只有当 ACK = 1 时确认号字段才有效。当 ACK = 0 时,确认号无效。
推送 PSH (PuSH) —— 接收 TCP 收到 PSH = 1 的报文段,就尽快地交付接收应用进程,而不再等到整个缓存都
填满了后再向上交付。
复位 RST (ReSeT) —— 当 RST = 1 时,表明 TCP 连接中出现严重差错(如由于主机崩溃或其他原因),必须
释放连接,然后再重新建立运输连接。
同步 SYN —— 同步 SYN = 1 表示这是一个连接请求或连接接受报文。
终止 FIN (FINis) —— 用来释放一个连接。FIN = 1 表明此报文段的发送端的数据已发送完毕,并要求释放运输
连接。
窗口字段 —— 占 2 字节,用来让对方设置发送窗口的依据,单位为字节。
检验和 —— 占 2 字节。检验和字段检验的范围包括首部和数据这两部分。在计算检验和时,要在 TCP 报文段
的前面加上 12 字节的伪首部。
紧急指针字段 —— 占 16 位,指出在本报文段中紧急数据共有多少个字节(紧急数据放在本报文段数据的最前面)。
选项字段 —— 长度可变。TCP 最初只规定了一种选项,即最大报文段长度 MSS。MSS 告诉对方 TCP:“我的
缓存所能接收的报文段的数据字段的最大长度是 MSS 个字节。”
滑动窗口机制:

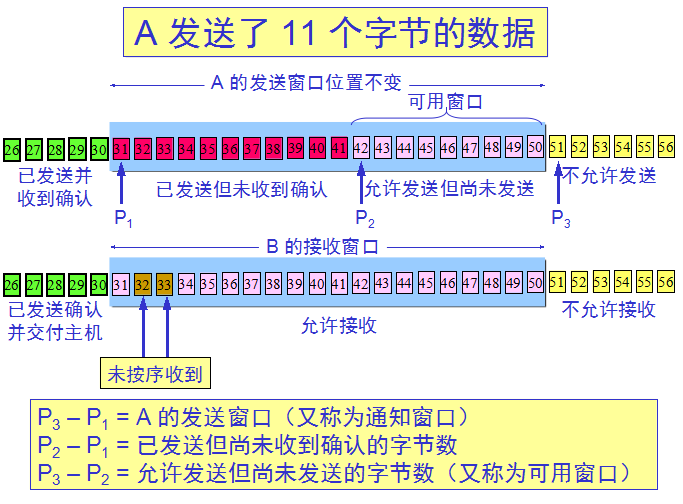

发送缓存与接收缓存的作用:
发送缓存用来暂时存放:发送应用程序传送给发送方 TCP 准备发送的数据; TCP 已发送出但尚未收到确认的数据。
接收缓存用来暂时存放: 按序到达的、但尚未被接收应用程序读取的数据;不按序到达的数据。
注意:
A 的发送窗口并不总是和 B 的接收窗口一样大(因为有一定的时间滞后)。TCP 标准没有规定对不按序到达的数
据应如何处理。通常是先临时存放在接收窗口中,等到字节流中所缺少的字节收到后,再按序交付上层的应用进程。
TCP 要求接收方必须有累积确认的功能,这样可以减小传输开销。
TCP流量控制:
利用滑动窗口实现流量控制
一般说来,我们总是希望数据传输得更快一些。但如果发送方把数据发送得过快,接收方就可能来不及接收,这就
会造成数据的丢失。
流量控制(flow control)就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。利用
滑动窗口机制可以很方便地在 TCP 连接上实现流量控制。
TCP拥塞控制:
在某段时间,若对网络中某资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏——产生拥塞(congestion)。
几种拥塞控制的方法:
- 慢开始和拥塞避免:
发送方维持一个叫做拥塞窗口 cwnd (congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞窗口。如再考虑到接收方的接收能力,则发送窗口还可能小于拥塞窗口。发送方控制拥塞窗口的原则是:只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
慢开始算法:在主机刚刚开始发送报文段时可先设置拥塞窗口 cwnd = 1,即设置为一个最大报文段 MSS 的数值。在每收到一个对新的报文段的确认后,将拥塞窗口加 1,即增加一个 MSS 的数值。
设置慢开始门限状态变量ssthresh
当 cwnd < ssthresh 时,使用慢开始算法。 当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。
当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞避免算法。
拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢地增大,即每经过一个往返时间 RTT 就把发送方的拥塞窗口 cwnd 加 1,而不是加倍,使拥塞窗口 cwnd 按线性规律缓慢增长。
无论在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有按时收到确认),就要把慢开始门限 ssthresh 设置为出现拥塞时的发送方窗口值的一半(但不能小于2)。
然后把拥塞窗口 cwnd 重新设置为 1,执行慢开始算法。
这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。


“拥塞避免”并非指完全能够避免了拥塞。利用以上的措施要完全避免网络拥塞还是不可能的。“拥塞避免”是说在拥塞避免阶段把拥塞窗口控制为按线性规律增长,使网络比较不容易出现拥塞。
- 快重传和快恢复
快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认。这样做可以让发送方及早知道有报文段没有到达接收方。
发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段。 不难看出,快重传并非取消重传计时器,而是在某些情况下可更早地重传丢失的报文段。
快恢复算法 :
(1) 当发送端收到连续三个重复的确认时,就执行“乘法减小”算法,把慢开始门限 ssthresh 减半。但接下去不执行慢开始算法。
(2)由于发送方现在认为网络很可能没有发生拥塞,因此现在不执行慢开始算法,即拥塞窗口 cwnd 现在不设置为 1,而是设置为慢开始门限 ssthresh 减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。

发送窗口的上限值 =Min [rwnd, cwnd]
TCP运输连接管理:
1.运输连接的三个阶段:
运输连接就有三个阶段,即:连接建立、数据传送和连接释放。运输连接的管理就是使运输连接的建立和释放都能正常地进行。
连接建立过程中要解决以下三个问题:
要使每一方能够确知对方的存在。
要允许双方协商一些参数(如最大报文段长度,最大窗口大小,服务质量等)。
能够对运输实体资源(如缓存大小,连接表中的项目等)进行分配。
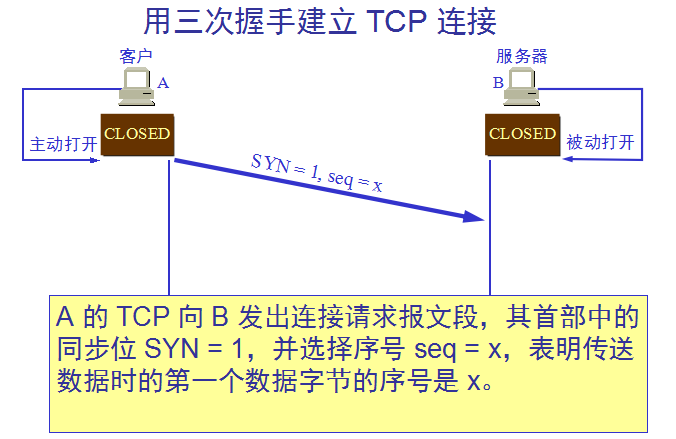
TCP 连接的建立都是采用客户服务器方式。主动发起连接建立的应用进程叫做客户(client)。被动等待连接建立的应用进程叫做服务器(server)。
TCP连接的三次握手:
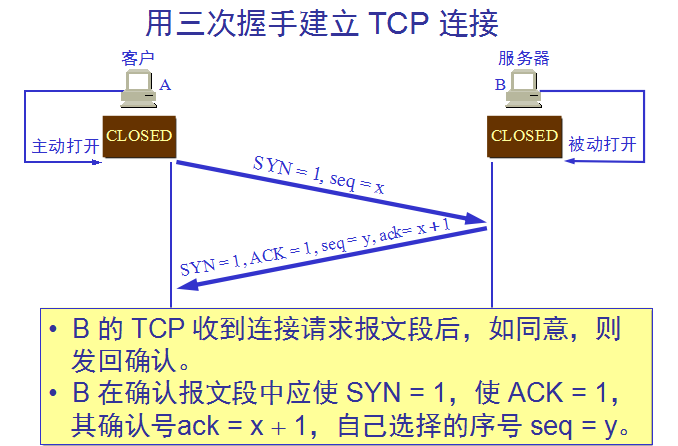
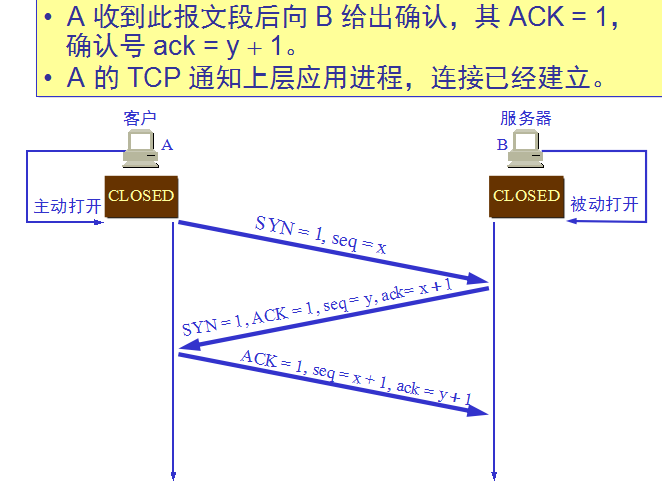
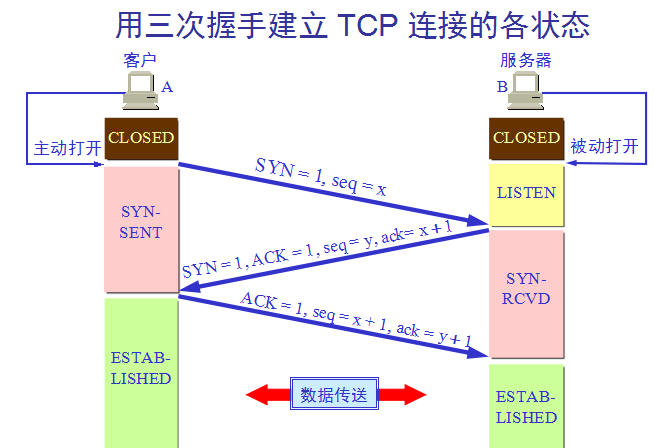
TCP连接的释放(四次挥手):

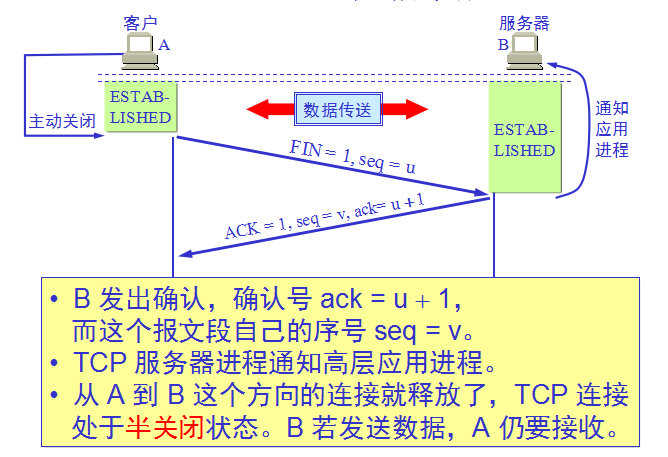
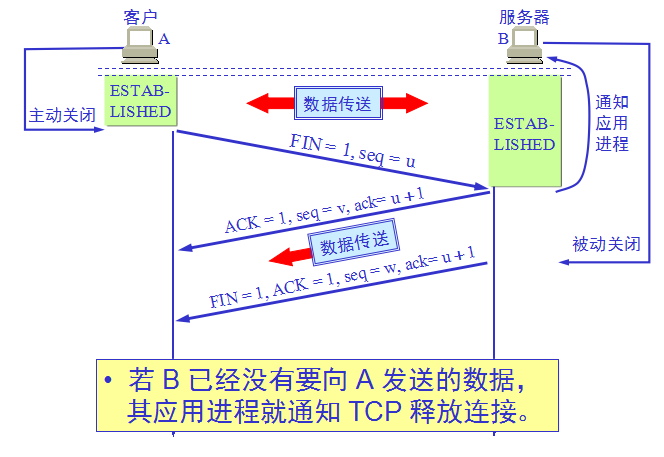

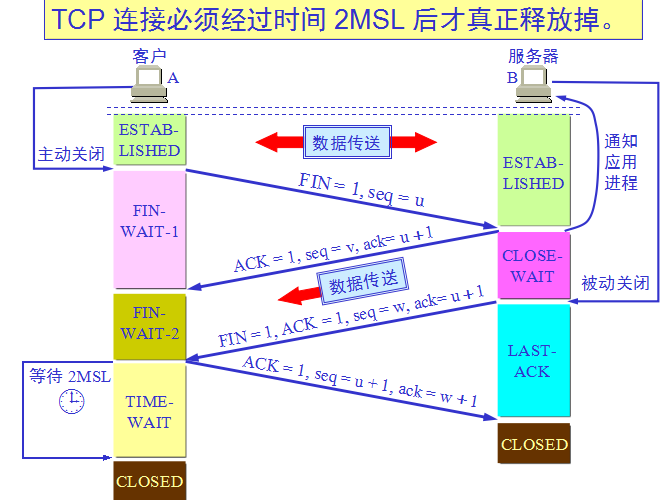
A 必须等待 2MSL 的时间
第一,为了保证 A 发送的最后一个 ACK 报文段能够到达 B。
第二,防止 “已失效的连接请求报文段”出现在本连接中。A 在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以使本连接持续的时间内所产生的所有报文段,都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
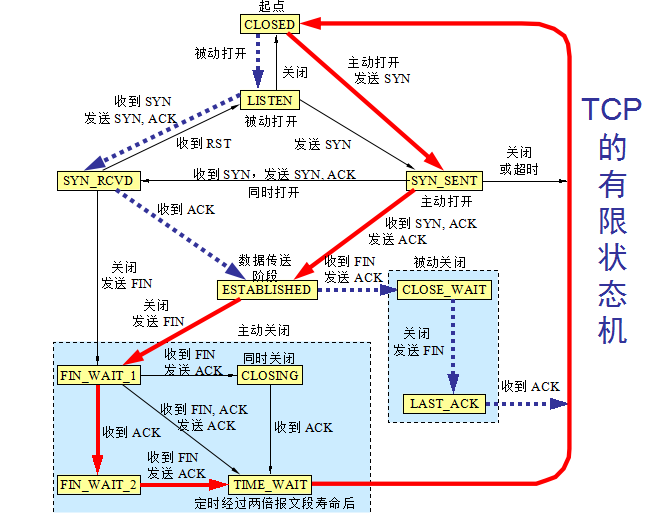
TCP 的有限状态机:
TCP 有限状态机的图中每一个方框都是 TCP 可能具有的状态。
每个方框中的大写英文字符串是 TCP 标准所使用的 TCP 连接状态名。状态之间的箭头表示可能发生的状态变迁。
箭头旁边的字,表明引起这种变迁的原因,或表明发生状态变迁后又出现什么动作。
图中有三种不同的箭头。
粗实线箭头表示对客户进程的正常变迁。
粗虚线箭头表示对服务器进程的正常变迁。
另一种细线箭头表示异常变迁。
六.应用层
应用层协议的特点:
每个应用层协议都是为了解决某一类应用问题,而问题的解决又往往是通过位于不同主机中的多个应用进程之间的通信和协同工作来完成的。应用层的具体内容就是规定应用进程在通信时所遵循的协议。应用层的许多协议都是基于客户服务器方式。客户(client)和服务器(server)都是指通信中所涉及的两个应用进程。客户服务器方式所描述的是进程之间服务和被服务的关系。客户是服务请求方,服务器是服务提供方。
域名系统DNS:
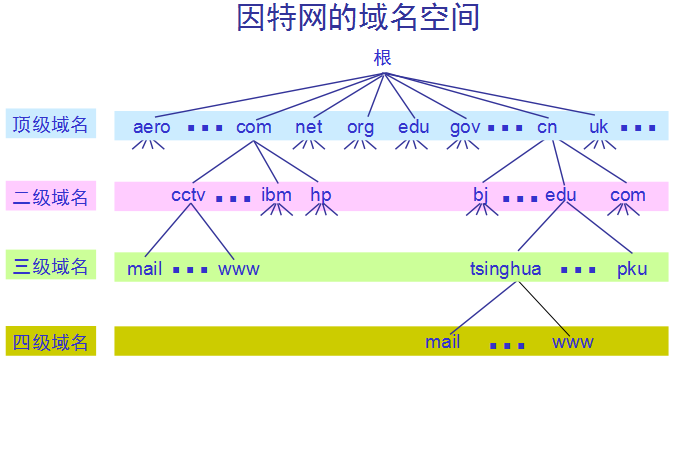
许多应用层软件经常直接使用域名系统 DNS (Domain Name System),但计算机的用户只是间接而不是直接使用域名系统。因特网采用层次结构的命名树作为主机的名字,并使用分布式的域名系统 DNS。名字到 IP 地址的解析是由若干个域名服务器程序完成的。域名服务器程序在专设的结点上运行,运行该程序的机器称为域名服务器。
顶级域名 TLD (Top Level Domain):
(1) 国家顶级域名 nTLD:如: .cn 表示中国,.us 表示美国,.uk 表示英国,等等。
(2) 通用顶级域名 gTLD:最早的顶级域名是:
.com (公司和企业)
.net (网络服务机构)
.org (非赢利性组织)
.edu (美国专用的教育机构()
.gov (美国专用的政府部门)
.mil (美国专用的军事部门)
.int (国际组织)
(3) 基础结构域名(infrastructure domain):这种顶级域名只有一个,即 arpa,用于反向域名解析,因此又称为反向域名。
.aero (航空运输企业)
.biz (公司和企业)
.cat (加泰隆人的语言和文化团体)
.coop (合作团体)
.info (各种情况)
.jobs (人力资源管理者)
.mobi (移动产品与服务的用户和提供者)
.museum (博物馆)
.name (个人)
.pro (有证书的专业人员)
.travel (旅游业)
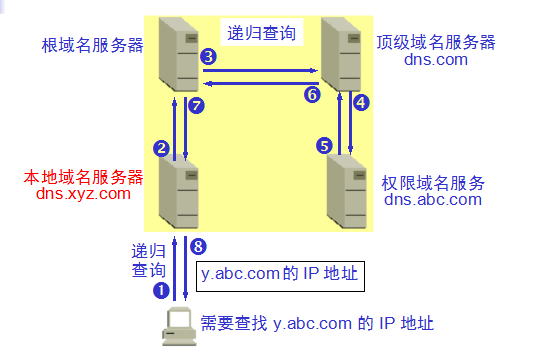
域名的解析过程 :
主机向本地域名服务器的查询一般都是采用递归查询。如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向其他根域名服务器继续发出查询请求报文。本地域名服务器向根域名服务器的查询通常是采用迭代查询。当根域名服务器收到本地域名服务器的迭代查询请求报文时,要么给出所要查询的 IP 地址,要么告诉本地域名服务器:“你下一步应当向哪一个域名服务器进行查询”。然后让本地域名服务器进行后续的查询。
本地域名服务器采用迭代查询:

本地域名服务器采用递归查询:
文件传送协议:
FTP协议:
文件传送协议 FTP (File Transfer Protocol) 是因特网上使用得最广泛的文件传送协议。FTP 提供交互式的访问,允许客户指明文件的类型与格式,并允许文件具有存取权限。FTP 屏蔽了各计算机系统的细节,因而适合于在异构网络中任意计算机之间传送文件。
文件传送协议 FTP 只提供文件传送的一些基本的服务,它使用 TCP 可靠的运输服务。FTP 的主要功能是减少或消除在不同操作系统下处理文件的不兼容性。FTP 使用客户服务器方式。一个 FTP 服务器进程可同时为多个客户进程提供服务。FTP 的服务器进程由两大部分组成:一个主进程,负责接受新的请求;另外有若干个从属进程,负责处理单个请求。
工作步骤:
打开熟知端口(端口号为 21),使客户进程能够连接上。
等待客户进程发出连接请求。
启动从属进程来处理客户进程发来的请求。从属进程对客户进程的请求处理完毕后即终止,但从属进程在运行期间根据需要还可能创建其他一些子进程。
回到等待状态,继续接受其他客户进程发来的请求。主进程与从属进程的处理是并发地进行。
控制连接在整个会话期间一直保持打开,FTP 客户发出的传送请求通过控制连接发送给服务器端的控制进程,但控制连接不用来传送文件。
实际用于传输文件的是“数据连接”。服务器端的控制进程在接收到 FTP 客户发送来的文件传输请求后就创建“数据传送进程”和“数据连接”,用来连接客户端和服务器端的数据传送进程。数据传送进程实际完成文件的传送,在传送完毕后关闭“数据传送连接”并结束运行。
当客户进程向服务器进程发出建立连接请求时,要寻找连接服务器进程的熟知端口(21),同时还要告诉服务器进程自己的另一个端口号码,用于建立数据传送连接。接着,服务器进程用自己传送数据的熟知端口(20)与客户进程所提供的端口号码建立数据传送连接。由于 FTP 使用了两个不同的端口号,所以数据连接与控制连接不会发生混乱。
简单文件传送协议 TFTP:
TFTP 是一个很小且易于实现的文件传送协议。TFTP 使用客户服务器方式和使用 UDP 数据报,因此 TFTP 需要有自己的差错改正措施。TFTP 只支持文件传输而不支持交互。TFTP 没有一个庞大的命令集,没有列目录的功能,也不能对用户进行身份鉴别。
TFTP的特点:
(1) 每次传送的数据 PDU 中有 512 字节的数据,但最后一次可不足 512 字节。
(2) 数据 PDU 也称为文件块(block),每个块按序编号,从 1 开始。 (3) 支持 ASCII 码或二进制传送。
(4) 可对文件进行读或写。
(5) 使用很简单的首部。
在一开始工作时。TFTP 客户进程发送一个读请求 PDU 或写请求 PDU 给 TFTP 服务器进程,其熟知端口号码为 69。
TFTP 服务器进程要选择一个新的端口和 TFTP 客户进程进行通信。
若文件长度恰好为 512 字节的整数倍,则在文件传送完毕后,还必须在最后发送一个只含首部而无数据的数据 PDU。若文件长度不是 512 字节的整数倍,则最后传送数据 PDU 的数据字段一定不满512字节,这正好可作为文件结束的标志。
远程终端协议 TELNET:
TELNET 是一个简单的远程终端协议,也是因特网的正式标准。
用户用 TELNET 就可在其所在地通过 TCP 连接注册(即登录)到远地的另一个主机上(使用主机名或 IP 地址)。
TELNET 能将用户的击键传到远地主机,同时也能将远地主机的输出通过 TCP 连接返回到用户屏幕。这种服务是透明的,因为用户感觉到好像键盘和显示器是直接连在远地主机上。
万维网WWW:
万维网 WWW (World Wide Web)并非某种特殊的计算机网络。万维网是一个大规模的、联机式的信息储藏所。万维网用链接的方法能非常方便地从因特网上的一个站点访问另一个站点,从而主动地按需获取丰富的信息。这种访问方式称为“链接”。
万维网是分布式超媒体(hypermedia)系统,它是超文本(hypertext)系统的扩充。
一个超文本由多个信息源链接成。利用一个链接可使用户找到另一个文档。这些文档可以位于世界上任何一个接在因特网上的超文本系统中。超文本是万维网的基础。
万维网的工作方式:
万维网以客户-服务器方式工作。
浏览器就是在用户计算机上的万维网客户程序。万维网文档所驻留的计算机则运行服务器程序,因此这个计算机也称为万维网服务器。
客户程序向服务器程序发出请求,服务器程序向客户程序送回客户所要的万维网文档。在一个客户程序主窗口上显示出的万维网文档称为页面(page)。
万维网必须解决的问题 :
(1) 怎样标志分布在整个因特网上的万维网文档?
使用统一资源定位符 URL (Uniform Resource Locator)来标志万维网上的各种文档。使每一个文档在整个因特网的范围内具有唯一的标识符 URL。
(2) 用何协议实现万维网上各种超链的链接?
在万维网客户程序与万维网服务器程序之间进行交互所使用的协议,是超文本传送协议 HTTP (Hyper Text Transfer Protocol)。HTTP 是一个应用层协议,它使用 TCP 连接进行可靠的传送。
(3) 怎样使各种万维网文档都能在因特网上的各种计算机上显示出来,同时使用户清楚地知道在什么地方存在着超链?
超文本标记语言 HTML (Hyper Text Markup Language)使得万维网页面的设计者可以很方便地用一个超链从本页面的某处链接到因特网上的任何一个万维网页面,并且能够在自己的计算机屏幕上将这些页面显示出来。
(4) 怎样使用户能够很方便地找到所需的信息?
为了在万维网上方便地查找信息,用户可使用各种的搜索工具(即搜索引擎)。
统一资源定位符 URL:
URL 给资源的位置提供一种抽象的识别方法,并用这种方法给资源定位。
一般格式:
<协议>://<主机>:<端口>/<路径>
超文本传送协议 HTTP:
为了使超文本的链接能够高效率地完成,需要用 HTTP 协议来传送一切必须的信息。
从层次的角度看,HTTP 是面向事务的(transaction-oriented)应用层协议,它是万维网上能够可靠地交换文件(包括文本、声音、图像等各种多媒体文件)的重要基础。
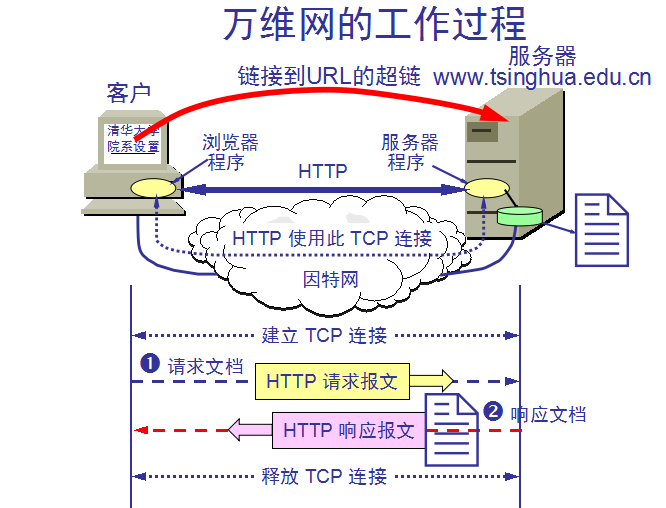
用户点击鼠标后所发生的事件:
(1) 浏览器分析超链指向页面的 URL。
(2) 浏览器向 DNS 请求解析 www.tsinghua.edu.cn 的 IP 地址。
(3) 域名系统 DNS 解析出清华大学服务器的 IP 地址。
(4) 浏览器与服务器建立 TCP 连接
(5) 浏览器发出取文件命令:GET /chn/yxsz/index.htm。
(6) 服务器给出响应,把文件 index.htm 发给浏览器。
(7) TCP 连接释放。
(8) 浏览器显示“清华大学院系设置”文件 index.htm 中的所有文本。
HTTP 的主要特点 :
HTTP 是面向事务的客户服务器协议。
HTTP 1.0 协议是无状态的(stateless)。
HTTP 协议本身也是无连接的,虽然它使用了面向连接的 TCP 向上提供的服务。
代理服务器:
代理服务器(proxy server)又称为万维网高速缓存(Web cache),它代表浏览器发出 HTTP 请求。万维网高速缓存把最近的一些请求和响应暂存在本地磁盘中。当与暂时存放的请求相同的新请求到达时,万维网高速缓存就把暂存的响应发送出去,而不需要按 URL 的地址再去因特网访问该资源。
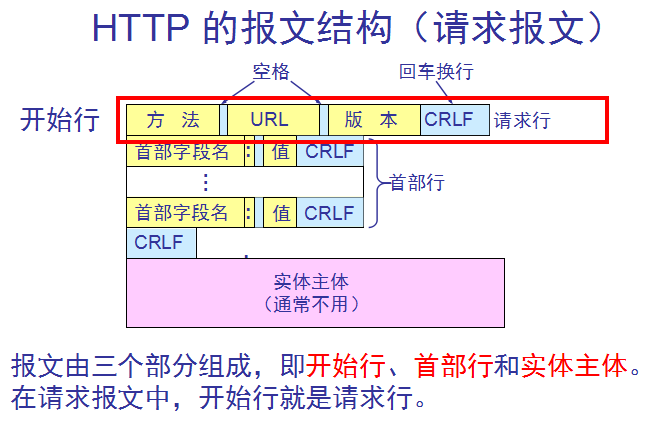
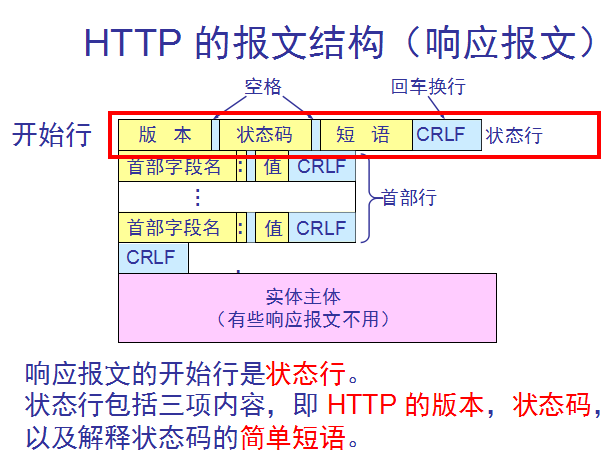
HTTP的报文结构:
HTTP 有两类报文:
请求报文——从客户向服务器发送请求报文。
响应报文——从服务器到客户的回答。
由于 HTTP 是面向正文的(text-oriented),因此在报文中的每一个字段都是一些 ASCII 码串,因而每个字段的长度都是不确定的。
方法(操作) 意义
OPTION 请求一些选项的信息
GET 请求读取由 URL所标志的信息
HEAD 请求读取由 URL所标志的信息的首部
POST 给服务器添加信息(例如,注释)
PUT 在指明的 URL下存储一个文档
DELETE 删除指明的 URL所标志的资源
TRACE 用来进行环回测试的请求报文
CONNECT 用于代理服务器
万维网站点使用 Cookie 来跟踪用户。Cookie 表示在 HTTP 服务器和客户之间传递的状态信息。使用 Cookie 的网站服务器为用户产生一个唯一的识别码。利用此识别码,网站就能够跟踪该用户在该网站的活动。
超文本标记语言 HTML:
超文本标记语言 HTML 中的 Markup 的意思就是“设置标记”。HTML 定义了许多用于排版的命令(即标签)。HTML 把各种标签嵌入到万维网的页面中。这样就构成了所谓的 HTML 文档。HTML 文档是一种可以用任何文本编辑器创建的 ASCII 码文件。
电子邮件:
电子邮件(e-mail)是因特网上使用得最多的和最受用户欢迎的一种应用。电子邮件把邮件发送到收件人使用的邮件服务器,并放在其中的收件人邮箱中,收件人可随时上网到自己使用的邮件服务器进行读取。
电子邮件不仅使用方便,而且还具有传递迅速和费用低廉的优点。
现在电子邮件不仅可传送文字信息,而且还可附上声音和图像。
发送邮件的协议:SMTP
读取邮件的协议:POP3 和 IMAP
MIME 在其邮件首部中说明了邮件的数据类型(如文本、声音、图像、视像等),使用 MIME 可在邮件中同时传送多种类型的数据。
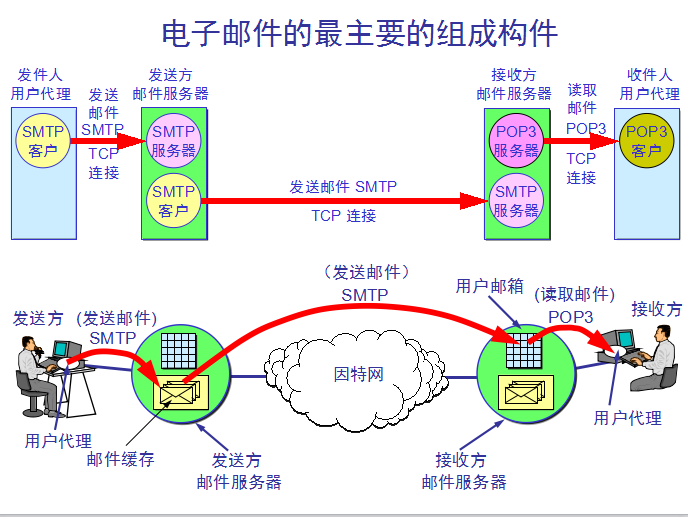
发送和接收电子邮件的几个重要步骤:
发件人调用 PC 中的用户代理撰写和编辑要发送的邮件。
发件人的用户代理把邮件用 SMTP 协议发给发送方邮件服务器,
SMTP 服务器把邮件临时存放在邮件缓存队列中,等待发送。
发送方邮件服务器的 SMTP 客户与接收方邮件服务器的 SMTP 服务器建立 TCP 连接,然后就把邮件缓存队列中的邮件依次发送出去。
运行在接收方邮件服务器中的SMTP服务器进 程收到邮件后,把邮件放入收件人的用户邮箱中,等待收件人进行读取。
‘ 收件人在打算收信时,就运行 PC 机中的用户代理,使用 POP3(或 IMAP)协议读取发送给自己的邮件。
请注意,POP3 服务器和 POP3 客户之间的通信是由 POP3 客户发起的。
电子邮件由信封(envelope)和内容(content)两部分组成。
电子邮件的传输程序根据邮件信封上的信息来传送邮件。用户在从自己的邮箱中读取邮件时才能见到邮件的内容。
在邮件的信封上,最重要的就是收件人的地址。
TCP/IP 体系的电子邮件系统规定电子邮件地址的格式如下:
收件人邮箱名@邮箱所在主机的域名
SMTP 通信的三个阶段 :
1. 连接建立:连接是在发送主机的 SMTP 客户和接收主机的 SMTP 服务器之间建立的。SMTP不使用中间的邮件服务器。
2. 邮件传送
3. 连接释放:邮件发送完毕后,SMTP 应释放 TCP 连接。
邮件读取协议POP3 和 IMAP:
邮局协议 POP 是一个非常简单、但功能有限的邮件读取协议,现在使用的是它的第三个版本 POP3。POP 也使用客户服务器的工作方式。在接收邮件的用户 PC 机中必须运行 POP 客户程序,而在用户所连接的 ISP 的邮件服务器中则运行 POP 服务器程序。
IMAP 协议,IMAP 也是按客户服务器方式工作,现在较新的是版本 4,即 IMAP4。用户在自己的 PC 机上就可以操纵 ISP 的邮件服务器的邮箱,就像在本地操纵一样。因此 IMAP 是一个联机协议。当用户 PC 机上的 IMAP 客户程序打开 IMAP 服务器的邮箱时,用户就可看到邮件的首部。若用户需要打开某个邮件,则该邮件才传到用户的计算机上。
注意:
不要将邮件读取协议 POP 或 IMAP 与邮件传送协议 SMTP 弄混。发信人的用户代理向源邮件服务器发送邮件,以及源邮件服务器向目的邮件服务器发送邮件,都是使用 SMTP 协议。
而 POP 协议或 IMAP 协议则是用户从目的邮件服务器上读取邮件所使用的协议。
基于万维网的电子邮件:
电子邮件从 A 发送到网易邮件服务器是使用 HTTP 协议。
两个邮件服务器之间的传送使用 SMTP。
邮件从新浪邮件服务器传送到 B 是使用 HTTP 协议。

动态主机配置协议 DHCP:
为了将软件协议做成通用的和便于移植,协议软件的编写者把协议软件参数化。这就使得在很多台计算机上使用同一个经过编译的二进制代码成为可能。一台计算机和另一台计算机的区别,都可通过一些不同的参数来体现。在软件协议运行之前,必须给每一个参数赋值。
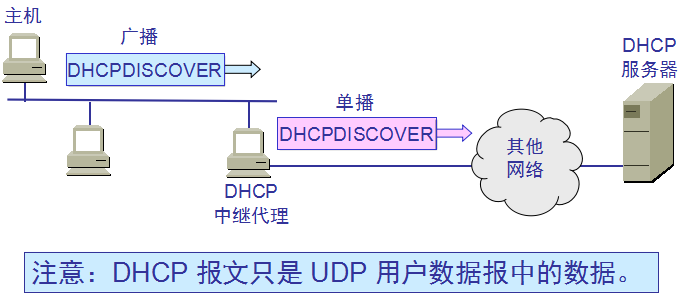
动态主机配置协议 DHCP 提供了即插即用连网(plug-and-play networking)的机制。这种机制允许一台计算机加入新的网络和获取IP地址而不用手工参与。
需要 IP 地址的主机在启动时就向 DHCP 服务器广播发送发现报文(DHCPDISCOVER),这时该主机就成为 DHCP 客户。
本地网络上所有主机都能收到此广播报文,但只有 DHCP 服务器才回答此广播报文。
DHCP 服务器先在其数据库中查找该计算机的配置信息。若找到,则返回找到的信息。若找不到,则从服务器的 IP 地址池(address pool)
中取一个地址分配给该计算机。DHCP 服务器的回答报文叫做提供报文(DHCPOFFER)。
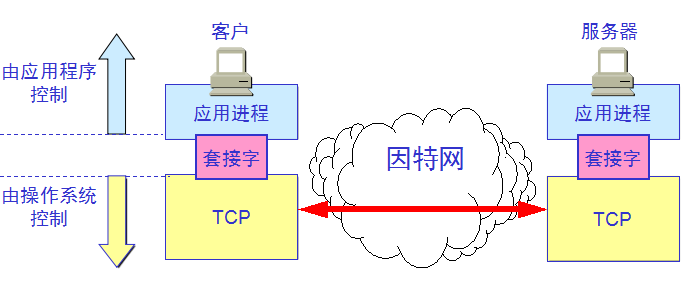
应用进程跨越网络的通信:
大多数操作系统使用系统调用(system call)的机制在应用程序和操作系统之间传递控制权。对程序员来说,每一个系统调用和一般程序设计中的函数调用非常相似,只是系统调用是将控制权传递给了操作系统。

应用编程接口 API(Application Programming Interface):
当某个应用进程启动系统调用时,控制权就从应用进程传递给了系统调用接口。此接口再将控制权传递给计算机的操作系统
。操作系统将此调用转给某个内部过程,并执行所请求的操作。内部过程一旦执行完毕,控制权就又通过系统调用接口返回给
应用进程。系统调用接口实际上就是应用进程的控制权和操作系统的控制权进行转换的一个接口,即应用编程接口 API。
几种应用编程接口 API :
Berkeley UNIX 操作系统定义了一种 API,它又称为套接字接口(socket interface)。
微软公司在其操作系统中采用了套接字接口 API,形成了一个稍有不同的 API,并称之为 Windows Socket。
AT&T 为其 UNIX 系统 V 定义了一种 API,简写为 TLI (Transport Layer Interface)。
应用进程通过套接字接入到网络:
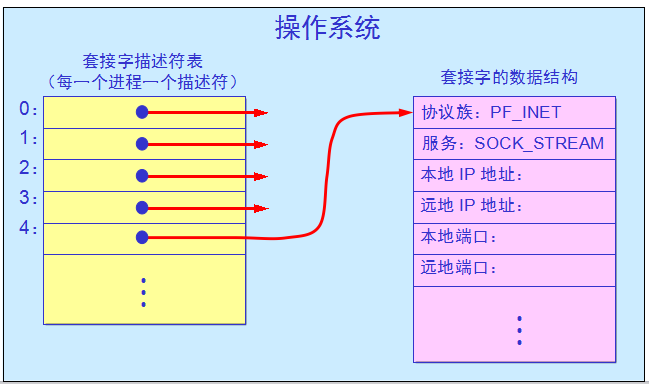
套接字的作用:
当应用进程需要使用网络进行通信时就发出系统调用,请求操作系统为其创建“套接字”,以便把网络通信所需要的系统资源分配给该应用进程。操作系统为这些资源的总和用一个叫做套接字描述符的号码来表示,并把此号码返回给应用进程。应用进程所进行的网络操作都必须使用这个号码。通信完毕后,应用进程通过一个关闭套接字的系统调用通知操作系统回收与该“号码”相关的所有资源。
调用 socket 创建套接字:
几种常用的系统调用:
连接建立阶段:
当套接字被创建后,它的端口号和 IP 地址都是空的,因此应用进程要调用 bind(绑定)来指明套接字的本地地址。在服务器端调用 bind 时就是把熟知端口号和本地IP地址填写到已创建的套接字中。这就叫做把本地地址绑定到套接字。服务器在调用 bind 后,还必须调用 listen(收听)把套接字设置为被动方式,以便随时接受客户的服务请求。UDP服务器由于只提供无连接服务,不使用 listen 系统调用。服务器紧接着就调用 accept(接受),以便把远地客户进程发来的连接请求提取出来。系统调用 accept 的一个变量就是要指明从哪一个套接字发起的连接。
几种常用的系统调用并发方式工作的服务器 :
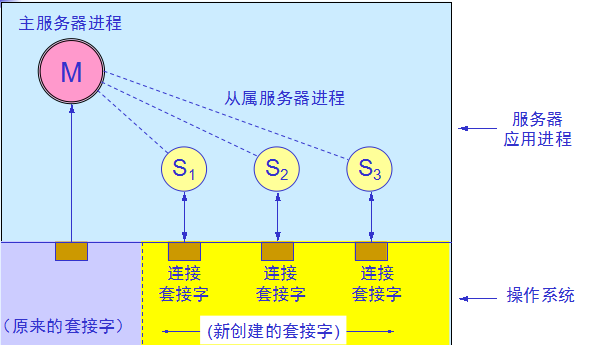
系统调用使用顺序的例子:

七 总结:
计算机网络(TCP/IP)有一套方法思想,根据我自己的理解就是一种自顶向下、逐层分解的思想。有点类似于设计模式中的松耦合的原则。就是把整体分层,层数不能太多也不能太少,要考虑实现的难度。还有要屏蔽来自各个方面的差异,每一层的每一个协议都代表了一个功能点和一个组合模块。每一个模块都实现之后就可以从整体的角度去把握,根据需要组合各个模块,提供不同的功能。这样一来就能适应现在纷繁的变化。在特定情况下修改策略的代价就会变小。这样说起来计算机网络的设计思想和软件工程的方法是相近。在我看来由各种协议和硬件资源整合起来的计算机网络的开发就是一个巨大的动态的软件工程。