一 关于TCP重传
-
TCP有重传是正常的机制,为了保障数据传输可靠性。只是局域网环境,网络质量有保障,因为网络问题出现重传应该极低;互联网或城域网环境,线路复杂(可以想象下城市地下管网,错综复杂的电线杆等),网络质量不好保障,重传出现概率较高。
-
TCP有重传,也不一定是网络层面的问题。也可能是接收端不存在,接收端receive buffer满了,应用程序有异常链接未正常关闭等等等。
二 TCP/IP相关
排查网络问题,要掌握TCP/IP原理,真相都在一个一个的数据包里。以下是和TCP重传比较关键的几个参数。
2.1 建立TCP链接时的参数
net.ipv4.tcp_syn_retries#syn包重传多少次后放弃,重传间隔是2的n次方(1s,2s,4s..)
net.ipv4.tcp_synack_retries#syn ack包重传多少次后放弃
net.ipv4.tcp_max_syn_backlog#syn包队列其他参考:
/proc/sys/net/ipv4/* Variables: https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
2.2 TCP重传类型
超时重传
在请求包发出去的时候,开启一个计时器,当计时器达到时间之后,没有收到ACK,则就进行重发请求的操作,一直重发直到达到重发上限次数或者收到ACK。
快速重传
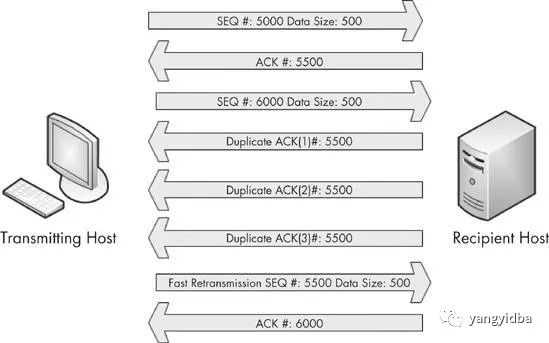
当接收方收到的数据包是不正常的序列号,那么接收方会重复把应该收到的那一条ACK重复发送,这个时候,如果发送方收到连续3条的同一个序列号的ACK,那么就会启动快速重传机制,把这个ACK对应的发送包重新发送一次。具体可以参考:
三 常见问题与措施
3.1单台机器或单个应用机器tcp重传,可能是链接的服务器或端口无法访问
排查思路
# 1、抓1000或者更多个tcp包
# 出现2次以上seq一样的包就是发生了重传
# syn包重传间隔是指数增加
# 已经建立了链接的tcp重传间隔,参考RTO
# 收到比较多ack重传,一般说明数据包出现乱序,seq较大的先到达了目的端,发送端收到3次sack会触发立即快速重传缺失的tcp分片。快速重传不太影响rt,但是发送窗口立即减半,会对吞吐带宽有一定影响
# 云环境虚拟机,还要考虑分析宿主机的问题
sudo ss -anti |grep -B 1 retrans #重传统计
if=bond0
sudo tcpdump -w /tmp/tcp.pcap -i $if -c 1000 -nn tcp 2>/dev/null
sudo tcpdump -nn -r /tmp/tcp.pcap | awk '{print $3,$5,$8,$9}' | sort | uniq -c | sort -rn |sed 's/^ \{1,\}//g'|egrep -v "^1 |Request"
2、联通性检查
ping $ip
nc -nvz $ip $port
3、接收端应用程序问题排查;来源和目的抓包,wireshark分析具体是什么包丢失导致了重传
3.2 多台机器或多个应用同时tcp重传,可能是网络抖动
排查思路
1、查看网络区域埋点,查看网络设备报警,看是否有区域网络抖动
2、区域网络没问题的话。可以用常见问题:1 的方法缩小排查范围3.3 带宽跑满
排查思路
1、查看主机监控,检查是否带宽跑满
2、检查重传联路上相关的网络设备是否有带宽跑满3.4 不常见问题
1 网络设备端口或光模块异常等导致包checksum失败
2 网络路由收敛抖动
3 主机网络驱动有bug,网络设备有bug等
四 如何监控
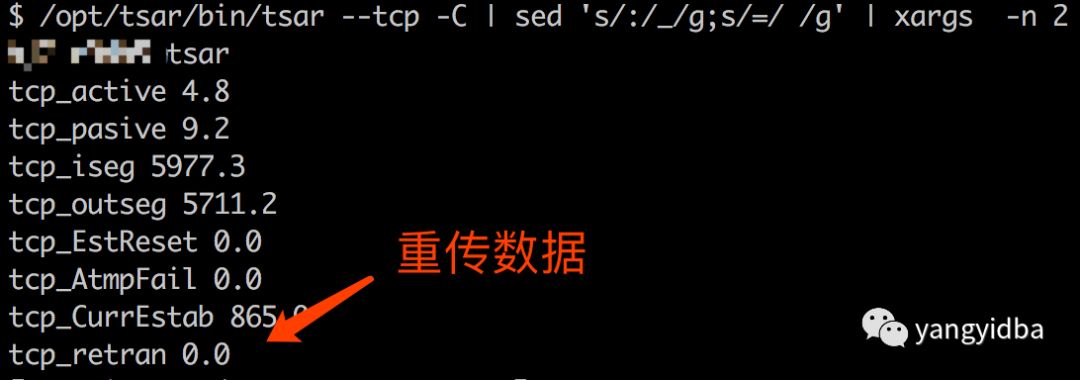
使用tsar -tcp -C 可以监控到tcp的retran属性也即是重传次数。
tsar –tcp -C | sed ‘s/:/_/g;s/=/ /g’ | xargs -n 2
感兴趣的朋友可以直接执行以下监控脚本获取tcp相关的状态监控数据,适用于open-falcon。
#!/usr/bin/env bashHOSTNAME=`hostname`
timestamp=`date +%s`
tagapp="app=tsar.collect"data_item=""tsarcollectstring=`/opt/tsar/bin/tsar --tcp -C | sed 's/:/_/g;s/=/ /g' | xargs -n 2 | tail -n +2|sed 's/ /|/'`for i in $tsarcollectstring
do
getkey=`echo $i|awk -F "|" '{print $1}'`
getvalue=`echo $i|awk -F "|" '{print $2}'`
tags="$tagapp" metric="tsar.collect.$getkey" metric_item="{ \"endpoint\":\"${HOSTNAME}\",\"tags\":\"${tags}\",
\"timestamp\":${timestamp},\"metric\":\"$metric\",
\"value\":${getvalue},\"counterType\":\"GAUGE\",
\"step\":60}"
if [ "${data_item}x" = "x" ];then
data_item="$metric_item" else data_item="${data_item},${metric_item}" fi
done
echo "[$data_item]"
五 案例实践
1 在遇到丢包重传的机器上抓包并使用wireshark 分析该包,注意因为重传不是时刻都有的,所以抓包命令是要持续执行以便捕捉到重传的包。使用wireshark打开tcpdump的结果,在搜索框里入手tcp.analysis.retransmission 得到如下结果:

图1 表明服务端发生了三次重传动作。
2 由于包比较多,我们可以使用wireshark的追踪流功能获取重传相关的tcp流
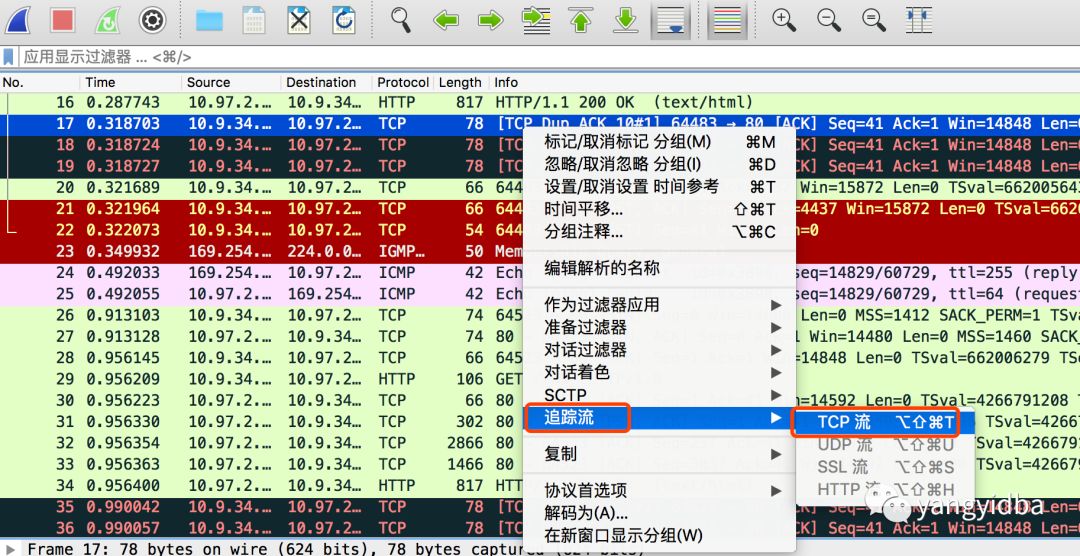
图二 追踪流–>TCP流 可以得到重传相关的数据包
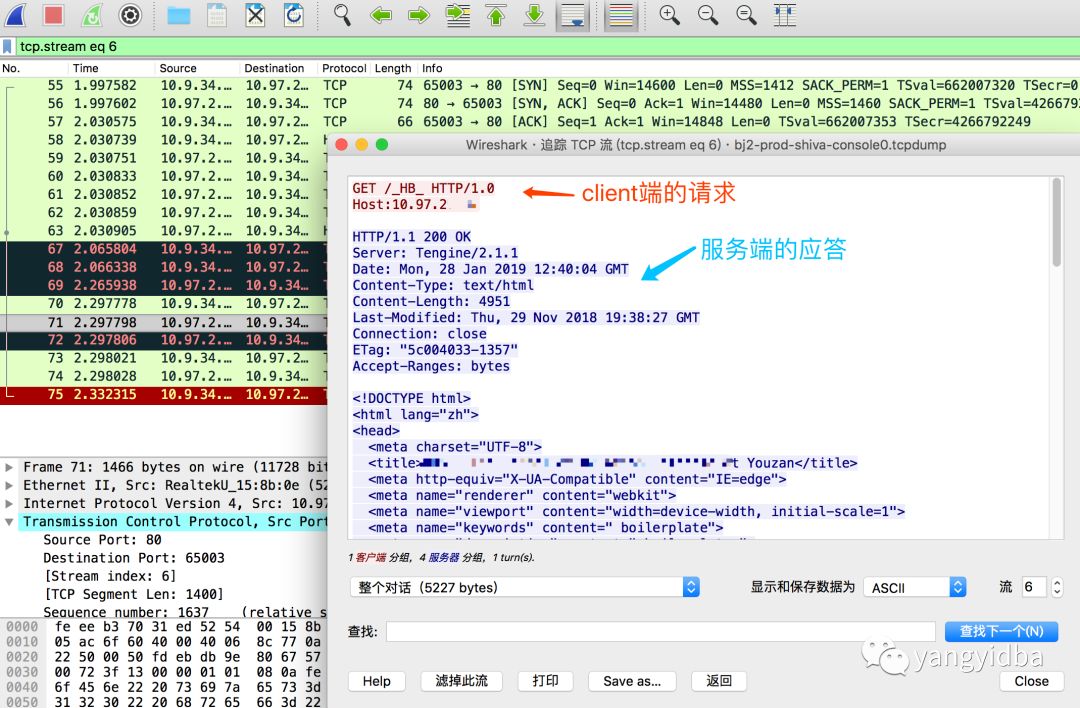
图三 可以看出客户端和服务端的请求与应答。
3 解析重传
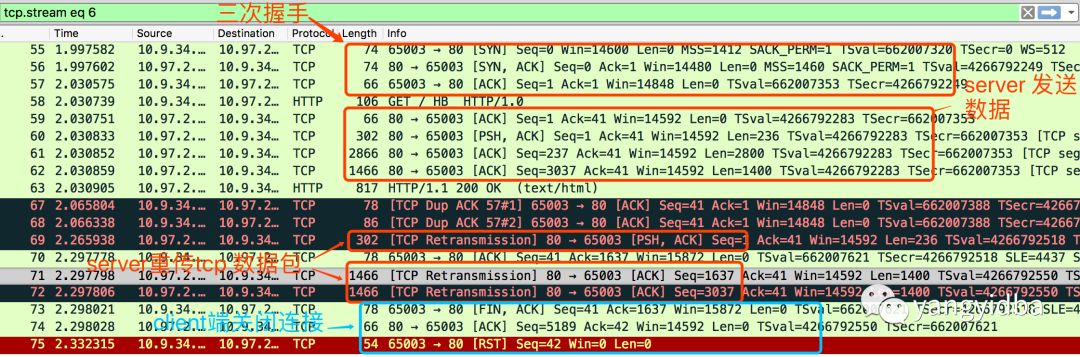
特别需要说明的是
NO 67,68 client端由于某些原因没有收到正确的包数据,向server端发送dup ack,参考基础知识提到的快速重传
NO.68和NO.69之间的时间差200ms(关注time那一列,其他都是相差小于1ms),server等待超时,于是重传。
NO 73-74是client端发送了一个fin包并主动关闭连接。
这个案例仅仅发生一次,没有复现,通过抓包解析出来分析没有得到明确的结论。
六 小结
本文总结自己工作过程中遇到的TCP重传问题的解决过程 ,侧重于大致的解决问题的思路与具体的实践,理论知识偏少,大家有兴趣的可以阅读推荐文章以便深入了解tcp的工作机制。