1.如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。这个值只可能在两个地方,一个是原下标的位置,另一种是在下标为<原下标+原容量>的位置
2.重新调整HashMap大小存在什么问题吗?
- 当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。(多线程的环境下不使用HashMap)
- 为什么多线程会导致死循环,它是怎么发生的?
HashMap的容量是有限的。当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高。这时候,HashMap需要扩展它的长度,也就是 进行Resize。
Resize是什么?首先我们先认识2个变量
1.Capacity
HashMap的当前长度。HashMap的长度是2的幂。
2.LoadFactor
HashMap负载因子,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:
HashMap.Size >= Capacity * LoadFactor
Resize步骤
1.扩容:创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
hash公式:index = HashCode(Key) & (Length – 1)
我们假设rehash之前的HashMap是这样的
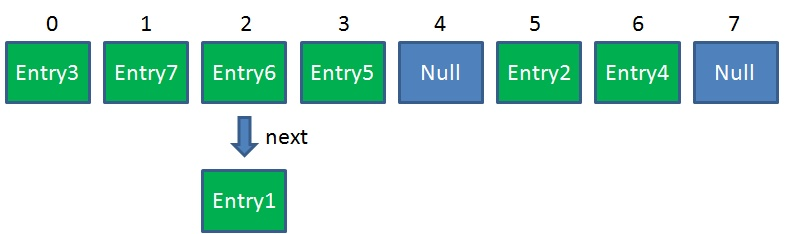
那么rehash之后可能是这样
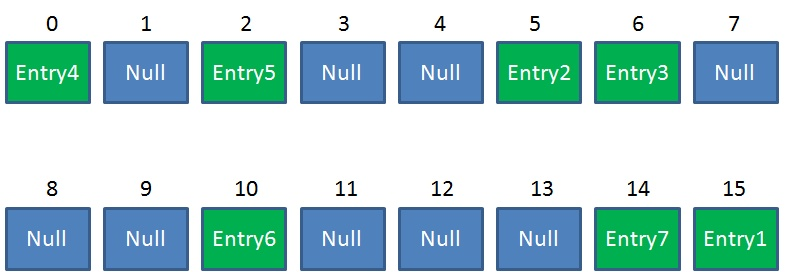
代码是这样的
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
现在假设一个场景,有一个hashmap如下
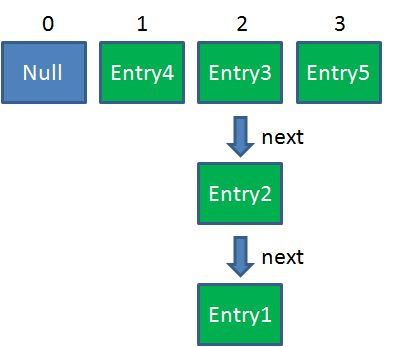
当有A,B这两个线程要对该hash map进行put操作
此时由于空间的不足,该hashmap必将进行扩容
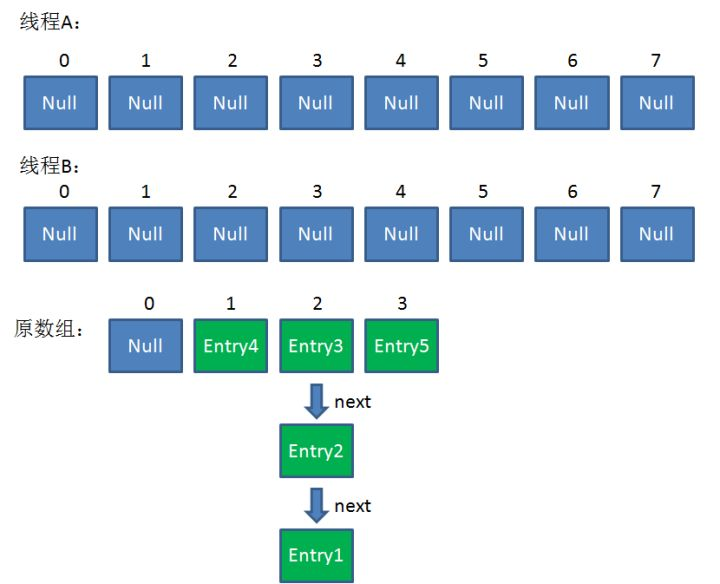
假如此时线程B遍历到Entry3对象,刚执行完红框里的这行代码,线程就被挂起。对于线程B来说:
e = Entry3
next = Entry2
这时候线程A畅通无阻地进行着Rehash,当ReHash完成后,结果如下(图中的e和next,代表线程B的两个引用):
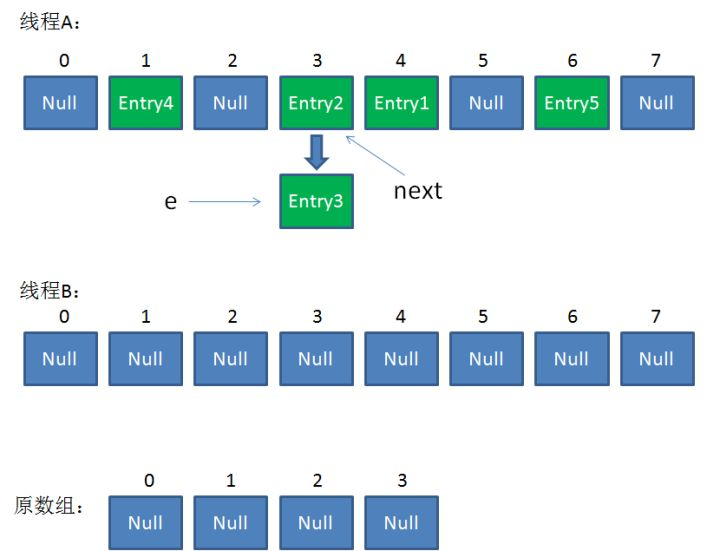
直到这一步,看起来没什么毛病。接下来线程B恢复,继续执行属于它自己的ReHash。线程B刚才的状态是:
e = Entry3
next = Entry2
我们继续执代码,Entry3放入了线程B的数组下标为3的位置,并且e指向了Entry2。此时e和next的指向如下:
e = Entry2
next = Entry2

接下来用头插法把Entry2插入到了线程B的数组的头结点
e = Entry2
next = Entry3

e = Entry3
next = Entry3.next = null

newTable[i] = Entry2这里若果是正常情况是newTable[i] =null,但是由于Entry2的hash被定为带同一个数组地址
e = Entry3
Entry2.next = Entry3
Entry3.next = Entry2
链表出现了环形!导致了死循环(多线程下请使用CocurrentHashMap)