问:简单说说 HashMap 的底层原理?
答:当我们往 HashMap 中 put 元素时,先根据 key 的 hash 值得到这个 Entry 元素在数组中的位置(即下标),然后把这个 Entry 元素放到对应的位置中,如果这个 Entry 元素所在的位子上已经存放有其他元素就在同一个位子上的 Entry 元素以链表的形式存放,新加入的放在链头,从 HashMap 中 get Entry 元素时先计算 key 的 hashcode,找到数组中对应位置的某一 Entry 元素,然后通过 key 的 equals 方法在对应位置的链表中找到需要的 Entry 元素,所以 HashMap 的数据结构是数组和链表的结合,此外 HashMap 中 key 和 value 都允许为 null,key 为 null 的键值对永远都放在以 table[0] 为头结点的链表中。
之所以 HashMap 这么设计的实质是由于数组存储区间是连续的,占用内存严重,故空间复杂度大,但二分查找时间复杂度小(O(1)),所以寻址容易而插入和删除困难;而链表存储区间离散,占用内存比较宽松,故空间复杂度小,但时间复杂度大(O(N)),所以寻址困难而插入和删除容易;所以就产生了一种新的数据结构叫做哈希表,哈希表既满足数据的查找方便,同时不占用太多的内容空间,使用也十分方便,哈希表有多种不同的实现方法,HashMap 采用的是链表的数组实现方式。
特别说明,对于 JDK 1.8 开始 HashMap 实现原理变成了数组+链表+红黑树的结构,数组链表部分基本不变,红黑树是为了解决哈希碰撞后链表索引效率的问题,所以在 JDK 1.8 中当链表的节点大于 8 个时就会将链表变为红黑树。区别是 JDK 1.8 以前碰撞节点会在链表头部插入,而 JDK 1.8 开始碰撞节点会在链表尾部插入,对于扩容操作后的节点转移 JDK 1.8 以前转移前后链表顺序会倒置,而 JDK 1.8 中依然保持原序。
问:HashMap 默认的初始化长度是多少?为什么默认长度和扩容后的长度都必须是 2 的幂?
答:在 JDK 中默认长度是 16(在 Android SDK 中的 HashMap 默认长度为 4),并且默认长度和扩容后的长度都必须是 2 的幂。因为我们可以先看下 HashMap 的 put 方法核心,如下:
public V put(K key, V value) {
......
//计算出 key 的 hash 值
int hash = hash(key);
//通过 key 的 hash 值和当前动态数组的长度求当前 key 的 Entry 在数组中的下标
int i = indexFor(hash, table.length);
......
}
//最核心的求数组下标方法
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}可以看到获取数组索引的计算方式为 key 的 hash 值按位与运算数组长度减一,为了说明长度尽量是 2 的幂的作用我们假设执行了 put(“android”, 123); 语句且 “android” 的 hash 值为 234567,二进制为 111001010001000111,然后由于 HashMap 默认长度为 16,所以减一后的二进制为 1111,接着两数做按位与操作二进制结果为 111,即十进制的 7,所以 index 为 7,可以看出这种按位操作比直接取模效率要高。
如果假设 HashMap 默认长度不是 2 的幂,譬如数组长度为 6,减一的二进制为 101,与 111001010001000111 按位与操作二进制 101,此时假设我们通过 put 再放一个 key-value 进来,其 hash 为 111001010001000101,其与 101 按位与操作后的二进制也为 101,很容易发生哈希碰撞,这就不符合 index 的均匀分布了。
通过上面两个假设例子可以看出 HashMap 的长度为 2 的幂时减一的值的二进制位数一定全为 1,这样数组下标 index 的值完全取决于 key 的 hash 值的后几位,因此只要存入 HashMap 的 Entry 的 key 的 hashCode 值分布均匀,HashMap 中数组 Entry 元素的分部也就尽可能是均匀的(也就避免了 hash 碰撞带来的性能问题),所以当长度为 2 的幂时不同的 hash 值发生碰撞的概率比较小,这样就会使得数据在 table 数组中分布较均匀,查询速度也较快。不过即使负载因子和 hash 算法设计的再合理也免不了哈希冲突碰撞的情况,一旦出现过多就会影响 HashMap 的性能,所以在 JDK 1.8 中官方对数据结构引入了红黑树,当链表长度太长(默认超过 8)时链表就转为了红黑树,而红黑树的增删改查都比较高效,从而解决了哈希碰撞带来的性能问题。
问:简单说说你对 HashMap 构造方法中 initialCapacity(初始容量)、loadFactor(加载因子)的理解?
答:这两个参数对于 HashMap 来说很重要,直接从一定程度决定了 HashMap 的性能问题。
initialCapacity 初始容量代表了哈希表中桶的初始数量,即 Entry< K,V>[] table 数组的初始长度,不过特别注意,table 数组的长度虽然依赖 initialCapacity,但是每次都会通过 roundUpToPowerOf2(initialCapacity) 方法来保证为 2 的幂次。
loadFactor 加载因子是哈希表在其容量自动增加之前可以达到多满的一种饱和度百分比,其衡量了一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。散列当前饱和度的计算为当前 HashMap 中 Entry 的存储个数除以当前 table 数组桶长度,因此当哈希表中 Entry 的数量超过了 loadFactor 加载因子乘以当前 table 数组桶长度时就会触发扩容操作。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大则对空间的利用更充分,从而导致查找效率的降低,如果负载因子太小则散列表的数据将过于稀疏,从而对空间造成浪费。系统默认负载因子为 0.75,一般情况下无需修改。
因此如果哈希桶数组很大则较差的 Hash 算法分部也会比较分散,如果哈希桶数组很小则即使好的 Hash 算法也会出现较多碰撞,所以就需要权衡好的 Hash 算法和扩容机制,也就是上面两个参数的作用。
问:简单说说 JDK1.7 中 HashMap 什么情况下会发生扩容?如何扩容?
答:HashMap 中默认的负载因子为 0.75,默认情况下第一次扩容阀值是 12(16 * 0.75),故第一次存储第 13 个键值对时就会触发扩容机制变为原来数组长度的二倍,以后每次扩容都类似计算机制;这也就是为什么 HashMap 在数组大小不变的情况下存放键值对越多查找的效率就会变低(因为 hash 碰撞会使数组变链表),而通过扩容就可以一定程度的平衡查找效率(尽量散列数组化)的原因所在。
下面给出 JDK 1.7 的具体扩容流程:
//JDK1.7扩容最核心的方法,newTable为新容量数组大小
void transfer(HashMapEntry[] newTable) {
//新容量数组桶大小为旧的table的2倍
int newCapacity = newTable.length;
//遍历旧的数组桶table
for (HashMapEntry<K,V> e : table) {
//如果这个数组位置上有元素且存在哈希冲突的链表结构则继续遍历链表
while(null != e) {
//取当前数组索引位上单向链表的下一个元素
HashMapEntry<K,V> next = e.next;
//重新依据hash值计算元素在扩容后数组中的索引位置
int i = indexFor(e.hash, newCapacity);
//将数组i的元素赋值给当前链表元素的下一个节点
e.next = newTable[i];
//将链表元素放入数组位置
newTable[i] = e;
//将当前数组索引位上单向链表的下一个元素赋值给e进行新的一圈链表遍历
e = next;
}
}
}可以看到,整个扩容过程就是一个取出数组元素(实际数组索引位置上的每个元素是每个独立单向链表的头部,也就是发生 Hash 冲突后最后放入的冲突元素)然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的 hash 值计算其在新数组中的下标然后进行交换(即原来 hash 冲突的单向链表尾部变成了扩容后单向链表的头部)。下面给出图解流程:

问:简单说说 JDK 1.8 中 HashMap 是如何扩容的?与 JDK 1.7 有什么区别?
答:JDK 1.7 中 HashMap 的扩容机制可以查看前一篇推文《[文末调查] Java 1.7 中 HashMap 扩容相关的两个经典问题》,简单总结如下图:
可以看见,1.7 中整个扩容过程就是一个取出数组元素(实际数组索引位置上的每个元素是每个独立单向链表的头部,也就是发生 Hash 冲突后最后放入的冲突元素)然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的 hash 值计算其在新数组中的下标然后进行交换(即原来 hash 冲突的单向链表尾部变成了扩容后单向链表的头部)。
而在 JDK 1.8 中 HashMap 的扩容操作就显得更加的骚气了,由于扩容数组的长度是 2 倍关系,所以对于假设初始 tableSize =4 要扩容到 8 来说就是 0100 到 1000 的变化(左移一位就是 2 倍),在扩容中只用判断原来的 hash 值与左移动的一位按位与操作是 0 或 1 就行,0 的话索引就不变,1 的话索引变成原索引加上扩容前数组,所以其实现如下流程图所示:
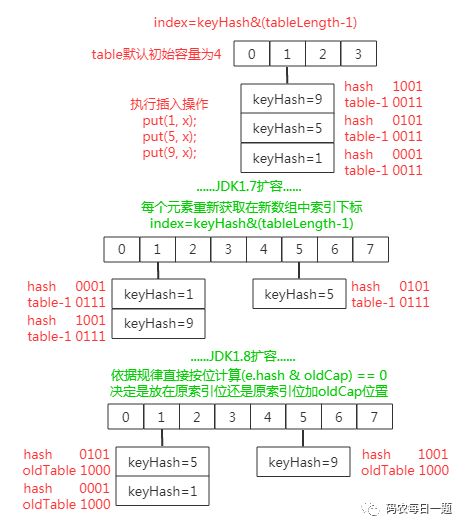
上图就是 1.8 与 1.7 扩容的核心流程图区别,其 1.8 源码核心实现如下:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//记住扩容前的数组长度和最大容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//超过数组在java中最大容量就无能为力了,冲突就只能冲突
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
} //长度和最大容量都扩容为原来的二倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}......
......
//更新新的最大容量为扩容计算后的最大容量
threshold = newThr;
//更新扩容后的新数组长度
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//遍历老数组下标索引
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果老数组对应索引上有元素则取出链表头元素放在e中
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果老数组j下标处只有一个元素则直接计算新数组中位置放置
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //如果是树结构进行单独处理
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//能进来说明数组索引j位置上存在哈希冲突的链表结构
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//循环处理数组索引j位置上哈希冲突的链表中每个元素
do {
next = e.next;
//判断key的hash值与老数组长度与操作后结果决定元素是放在原索引处还是新索引
if ((e.hash & oldCap) == 0) {
//放在原索引处的建立新链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//放在新索引(原索引+oldCap)处的建立新链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
//放入原索引处
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
//放入新索引处
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}可以看见,这个设计非常赞,因为 hash 值本来就是随机性的,所以 hash 按位与上 newTable 得到的 0(扩容前的索引位置)和 1(扩容前索引位置加上扩容前数组长度的数值索引处)就是随机的,所以扩容的过程就能把之前哈西冲突的元素再随机的分布到不同的索引去,这算是 JDK1.8 的一个优化点。
此外,在 JDK1.7 中扩容操作时哈西冲突的数组索引处的旧链表元素扩容到新数组时如果扩容后索引位置在新数组的索引位置与原数组中索引位置相同,则链表元素会发生倒置(即如上面图1,原来链表头扩容后变为尾巴);而在 JDK1.8 中不会出现链表倒置现象。
其次,由于 JDK1.7 中发生哈西冲突时仅仅采用了链表结构存储冲突元素,所以扩容时仅仅是重新计算其存储位置而已,而 JDK1.8 中为了性能在同一索引处发生哈西冲突到一定程度时链表结构会转换为红黑数结构存储冲突元素,故在扩容时如果当前索引中元素结构是红黑树且元素个数小于链表还原阈值(哈西冲突程度常量)时就会把树形结构缩小或直接还原为链表结构(其实现就是上面代码片段中的 split() 方法)。