一、前言
在堆上申请和释放内存的性能不高,这应该是常识了,尤其释放大块内存时,耗时更长,甚至会阻塞其他线程。做性能优化时,一般会采用内存池等手段避免频繁的申请和释放内存。本文从内核的角度分析申请和释放内存时的阻塞瓶颈,及化解方法。
为了便于理解,本文从用户申请、访问、释放内存的角度出发,逐步深入探讨Linux的内存管理。本文以阻塞为线索,从堆内存和栈内存的区别,到malloc的原理,再到内存页的管理,逐步找出释放大块内存时阻塞的原因,然后再给出一种化解的方法。
限于篇幅,没有面面俱到的阐述,只介绍了和本文主旨相关的关键点。能力和时间有限,难免有纰漏甚至错误,欢迎指正。
二、堆和栈
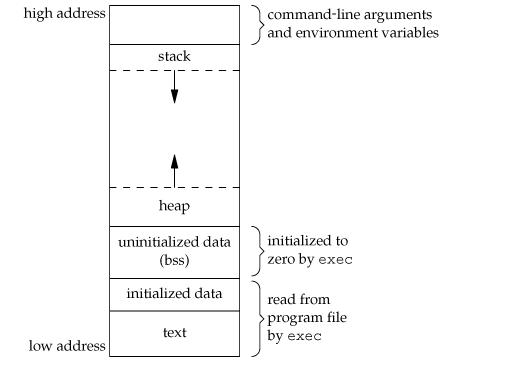
2.1 栈内存
栈内存是线程预留的固定大小的内存空间,只需要移动栈顶指针就可以完成申请和释放内存,因此速度很快,但大小受限。
2.2 堆内存
堆内存是程序运行时动态申请的,所以需要考虑竞争、碎片等问题,所以申请和释放的速度慢一些,但是更灵活。本文主要讲述使用堆内存的场景。
三、malloc
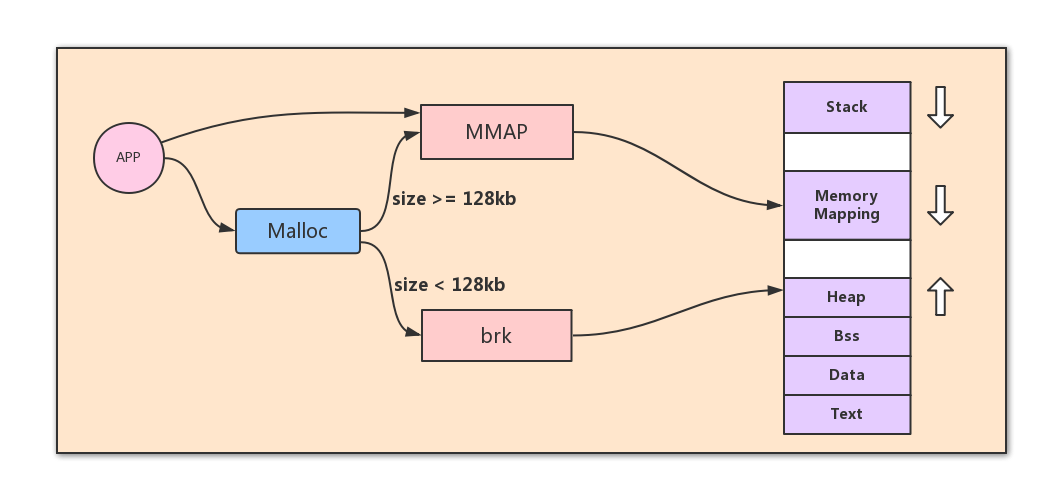
在c语言中,堆内存一般是用malloc函数申请的。malloc负责向系统申请内存和维护缓存(bins)。malloc通过brk/sbrk或mmap向系统申请内存,区别在于前者是通过增长堆地址空间扩大内存区域,而后者开辟新的内存区域,如下图。不过在内核看来它们并没有本质的区别。大块内存的申请和释放都是由mmap/munmap来完成的,所以“释放大块内存时的阻塞问题”也是由munmap造成的。测试发现munmap一块20GB的内存,会阻塞其他线程的malloc(brk/sbrk/mmap)1秒左右。
四、Linux 内存管理
为了弄清楚munmap阻塞的原因,先要了解一些Linux的内存管理机制。
4.1 页表(Page Table)
CPU 看到的内存地址是虚拟地址,页表中存储着虚拟地址到物理地址的映射关系,每次访问内存时由 MMU 完成虚拟地址到物理的转换。为了给这个转换过程加速又引入了 TLB,TLB 可以理解为虚拟地址到物理地址映射的 cache,它速度很快但容量较小。这里关键的一点是:如果操作系统更改了页表内容,它必须相应的刷新TLB以使CPU不误用过时的表项。
4.2 虚拟地址空间(vm_area)
前面讲到 mmap 可以申请一段新的虚拟内存区间,也就是说进程的虚拟地址空间不一定是连续的。所以内核使用链表来表示整个进程的地址空间,地址空间相接的两个节点可以合并,一个节点也可以因为状态变化而分割成多个。
4.3 缺页中断(Page Fault)
使用malloc(brk/sbrk/mmap)申请内存时,系统只分配了虚拟地址空间,并未分别物理地址,也就是说没有对应的页表项。当第一次访问该区域时,因为没有对应的页表,所以MMU会产生一个缺页中断给CPU,CPU再根据虚拟地址空间的描述申请物理内存,补充页表,然后再重新执行访问该内存区域的指令。
4.4 页框回收算法(PFRA)
内核会将不活跃的内存收回给其他进程使用。PFRA算法比较复杂,大致的思路是遍历内存,找到可以回收且近期未使用(LRU)的内存进行回收。
4.4.1 哪些内存可以回收
| 页类型 | 说明 | 回收操作 |
|---|---|---|
| 不可回收页 | 1. 空闲页(包含子伙伴系统列表中) 2. 保留页(PG_reserved标志置位) 3. 内核动态分配页4. 进程内核态堆栈页 5. 临时锁定页(PG_locked标志置位) 6. 内存锁定页(在先行区中且VM_LOCKED标志置位) |
不允许也无需回收 |
| 可回收页 | 1. 用户太地址空间的匿名页 2. tmpfs文件系统的映射页(如IPC共享内存的页) |
将页的内容保存在交换区 |
| 可同步页 | 1. 用户态地址空间的映射页 2. 存有磁盘文件数据且在页高速缓存中的页 3. 块设备缓冲区页 4. 某些磁盘高速缓存的页(如索引节点高速缓存) |
必要时,与磁盘镜像同步这些页 |
| 可丢弃页 | 1. 内存高速缓存中的未使用页(如slab分配器高速缓存) 2. 目录想高速缓存的未使用页 |
无需操作 |
简单的说就是大部分内核占用的内存不可以回收,大部分用户进程占用的内存都可以回收,被mlock标记的内存不可以回收。
4.4.2 LRU
为了能快速的找到不活跃的内存,Linux 使用了 LRU 链表。这里有个巧妙的设计。硬件只能标记哪些内存被访问过,只有一个标记位,没有访问时间的标记。所以Linux用3类(5个)FIFO的链表存储内存页,分别是活跃的内存链表、不活跃的内存链表、不可回收的内存链表。内核负责在这个三个链表间调度。
4.4.3 mlock
上面提到,被mlock(系统调用)标记的内存不可以被回收。那mlock是如何工作的呢?mlock在进程的虚拟地址空间(vm_area)做标记,前面提到vm_area是一个链表,所以mlock可能需要拆分或者合并vm_area节点。这个操作并不复杂,麻烦的是需要把被锁定的内存页移动到不可回收的内存链表(LRU),这个时间复杂度是线性的,也就是说操作的内存越多时间越长。
4.4.4 madvise
除了内核回收内存,用户也是可以主动回收指定内存的,通过madvise(MADV_DONTNEED)实现。和free不同的是,madvise(MADV_DONTNEED)只释放了页表,并没有释放虚拟地址空间(vm_area),也就是说被madvise(MADV_DONTNEED)回收的内存还可以再访问,只不过要重新出发缺页中断来分配物理内存。
五、阻塞的原因(Lock)
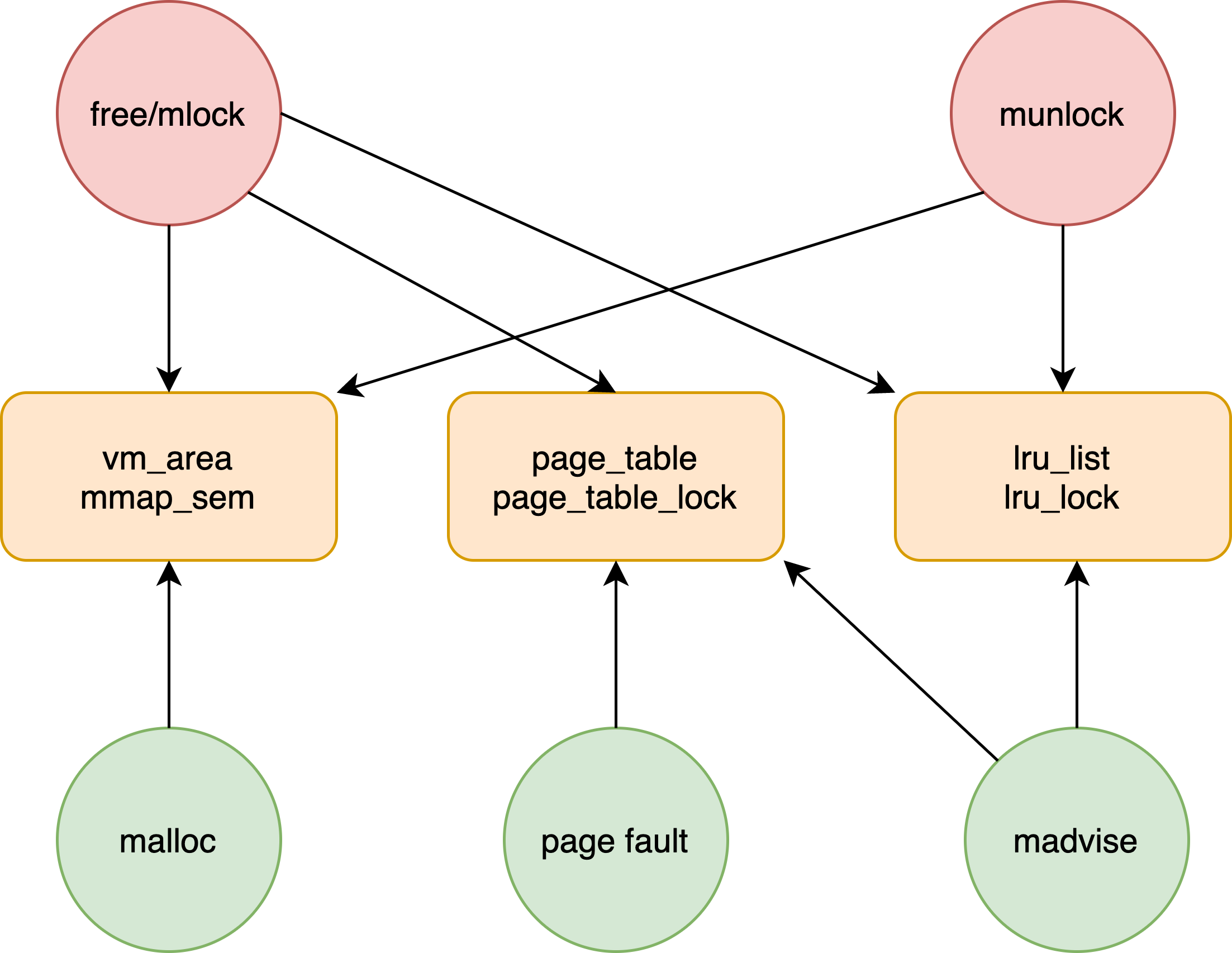
页表、虚拟地址空间、LRU各有一把锁,malloc(brk/sbrk/mmap)、free(munmap)、madvise、mlock和缺页中断都有可能获取其中的一个或多个锁。在操作大块内存时,由于内存页较多,处理的时间较长,就会出现阻塞其他线程的现象。
5.1 malloc(brk/mmap)
申请内存时只需要修改虚拟地址空间,在链表中做插入、合并等操作,所以相对轻量一些。
5.2 缺页中断
第一次访问内存时触发缺页中断,只要不是集中的触发,一般不会出现明显的阻塞。
5.3 mlock
- 修改虚拟地址空间的状态,可能会触发节点的分割、合并等操作
- 修改LRU链表
- 填充页表
mlock的处理时间和内存页的个数是线性关系,所以操作大块内存时会发生明显的阻塞。
5.4 madvise
madvise可以清除页表项,处理的内存页越多时间越长。
5.5 free(munmap)
释放内存比申请内存麻烦的多,需要释放虚拟地址空间、清除页表项、修改LRU链表。所以释放大块内存时会出现明显的阻塞现象。
六、缓解阻塞的方法
6.1 分批操作
- free/munmap 前用madivse分批的释放页表
- mlock/munlock 也要分批执行
- malloc/mmap 后可以分批的touch每个page,避免集中出发缺页中断
6.2 大页(Huge Page)
Linux默认使用的页是4k,大页内存可以使用2M甚至更大的页,能有效减少页的数量,从提供大块内存使用的效率。
七、测试数据
多次测试结果有一定差异,但基本不会超过一个数量级。
| 序号 | 内存大小 | 方法 | 最大阻塞时长 | 备注 |
|---|---|---|---|---|
| 1 | 20GB | free | 1476 ms | 未加特殊处理 |
| 2 | 20GB | munmap | 704 ms | 内存映射 |
| 3 | 20GB | madvise + munmap | 0.3 ms | 先用madvise分批释放页表项,再用munmap卸载内存 |
| 4 | 20GB | mlock + munmap | 4667 ms | 没有做分批处理 |
| 5 | 20GB | mlock + madvise + munmap | 3.5 ms | 分段的mlock、munlock、madvise,可以明显的缓解阻塞的问题 |