1. 前言
金庸老爷子在《神雕侠侣》中说独孤求败的玄铁重剑时,说道“重剑无锋,大巧不工”。他说的是如果个人修养达到一定的阶段,“花石草木皆可为剑”,而不需要更多技巧。在Linux内核中从来不缺少简洁、优美、高效的实现代码,缺少的是发现这些美的眼睛和毅力。在Linux内核中,代码的简洁高效并不意味采用了失传很久的武林绝技,恰恰相反,它们往往通过最基本的知识和数据结构来实现完美的代码,而kfifo可以说就是其中的一个典范。
这里用“大巧不工”来形容Linux中的无锁环形队列显然不合适,原因在于:无锁环形队列属于精雕细琢,大道至简、匠心独运,简洁而不简单。它使用最基本的技术知识实现了重要的功能。下面我们便一睹其芳容。
2. Kfifo简介
| 本文分析的原代码版本 | 2.6.12 |
|---|---|
| kfifo的头文件 | linux-2.6.12\include\linux\kfifo.h |
| kfifo的源文件 | linux-2.6.12\kernel\kfifo.c |
kfifo是一种”First In First Out “数据结构,它采用了前面提到的环形缓冲区来实现,提供一个无边界的字节流服务。采用环形缓冲区的好处为,当一个数据元素被用掉后,其余数据元素不需要移动其存储位置,从而减少拷贝提高效率。更重要的是,kfifo采用了并行无锁技术,kfifo实现的单生产/单消费模式的共享队列是不需要加锁同步的。
并行无锁技术的由来:
当前高性能的服务器软件(例如HTTP加速器)大多都运行在多核服务器上,当前的硬件可以支持32、 64甚至更多的CPU,在这种高并发的环境下,
锁竞争机制有时候比数据拷贝、上下文切换等更伤害系统的性能,因此在多核环境下,需要把重要的数据结构从锁的保护下移到无锁环境中,以此来提高软件的性能。
所以,现在无锁机制越来越流行,在不同的环境中使用不同的无锁队列可以节省开销,提高程序效率。
[1] 摘自《深入浅出DPDK》第四章同步互斥机制:4.4.1 Linux内核无锁环形缓冲
下面我们说一下kfifo的结构
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};kfifo结构中个字段的含义:
| buffer | 用于存放数据的缓存 |
|---|---|
| size | 缓冲区空间的大小,要求为2的幂次方 |
| in | 指向buffer中队头 |
| out | 指向buffer中的队尾 |
| lock | 用来同步多个生产者、多个消费者的情形 |
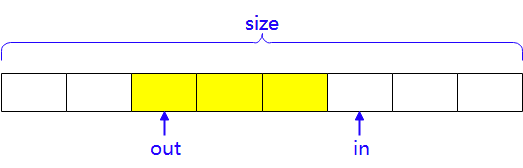
Kfifo无锁队列的应用注意事项:
- 单生产者/单消费者无需使用锁进行同步
- 未使用kfifo_reset()
- 只有在消费者端使用了kfifo_reset_out()
以上三种条件都满足的情况下可以使用kfifo无锁队列。相反,如果存在多个生产者或者多个消费者,则可以通过锁来进行同步:
- 多个生产者一个消费者模式,生产者端加锁同步
- 单个生产者多个消费者模式。消费者端加锁同步
Kfifo作为一个基本FIFO结构,包括入队函数___kfifo_put、出队函数__kfifo_get()等基本操作。下面来一一说明。
3. Kfifo初始化
Kfifo的初始化是指为kfifo分配空间、初始化kfifo中的各项参数等操作。
/**
* kfifo_alloc - allocates a new FIFO and its internal buffer
* @size: the size of the internal buffer to be allocated.
* @gfp_mask: get_free_pages mask, passed to kmalloc()
* @lock: the lock to be used to protect the fifo buffer
*
* The size will be rounded-up to a power of 2.
*/
struct kfifo *kfifo_alloc(unsigned int size, unsigned int __nocast gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
/*
* round up to the next power of 2, since our 'let the indices
* wrap' tachnique works only in this case.
*/
if (size & (size - 1)) {/*如果不是2的幂次方,则向上取到2的幂次方*/
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}3.1 判断一个数是否为2的幂次方
在这个kfifo_alloc()函数中,要求size需要为2的幂次方,如何实现高效的判断呢?
在二进制中,2的幂次方很容易表示:一个数只有一个bit上是1,其余全为0,例如:
| 十进制数表示 | 二进制表示 | 是否为2的幂次方 |
|---|---|---|
| 8 | 0000 1000 | 是 |
| 30 | 0001 1110 | 否 |
| 666 | 001010011010 | 否 |
| 1024 | 0100 0000 0000 | 是 |
| 2000 | 0111 1101 0000 | 否 |
| 4096 | 0001 0000 0000 0000 | 是 |
也就是说,如果我们可以判断:一个数的二进制上只有一个bit位为1,那么这个数肯定为2的幂次方。问题发生了等价转换,那么我们如何判断 一个数的二进制中包含几个1呢???。【这是面试中的一个常见问题和技巧】。方法就是:x & (x -1)==0, 则这个数二进制中只有一个1,否则包含多个1。通常使用这个方法来计算一个数中包含几个1。
[2] 《剑指offer》面试题15:二进制中1的个数
/*求一个数的二进制中1的个数*/
int numberof1(int n)
{
int count = 0;
while(n){
count++;
n = n & (n-1);
}
return count;
}简单的说:x & (n -1)会将x二进制中最低位上的1置为0(最后一个1置为0)。因此如果n&(n-1)==0,那个说明这个数二进制中只有一个bit位为1,因此肯定是2的幂次方。
3.2 求不小于某个数2的整数次幂
我看还是直接看内核实现吧:
static __inline__ int generic_fls(int x)
{
int r = 32;
if (!x)
return 0;
if (!(x & 0xffff0000u)) {
x <<= 16;
r -= 16;
}
if (!(x & 0xff000000u)) {
x <<= 8;
r -= 8;
}
if (!(x & 0xf0000000u)) {
x <<= 4;
r -= 4;
}
if (!(x & 0xc0000000u)) {
x <<= 2;
r -= 2;
}
if (!(x & 0x80000000u)) {
x <<= 1;
r -= 1;1
}
return r;
}
static inline unsigned long __attribute_const__ roundup_pow_of_two(unsigned long x)
{
return (1UL << generic_fls(x - 1));
}这个效率嘛? 由于全是位运算,肯定为求模、取余等四则运算效率要高, 不能放过任何一点可以优化的地方。至于这样做的原理,自己品品吧,也是相当经典的存在。
root@ubantu:/home/toney# ./a.out
12 --- output=4
16 --- output=5
24 --- output=5
32 --- output=6
128 --- output=8
1024 --- output=11
1400 --- output=11
2040 --- output=113.3 为什么要求2的幂次方呢?
为了使用位运算,快, 快,不择手段的快
4. Kfifo入队和出队
__kfifo_put是Kfifo的入队函数,源码实现如下:
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
fifo->in += len;
return len;
}需要说明的是Linux 2.6.12版本的内核实现中并没有使用内存屏障,而在后续版本中添加了内存屏障,它是实现无锁队列的核心和关键。这里我们就按照Linux2.6.12版本实现来说明简单原理,关于内存屏障,可以参考我的另一篇博文
《什么是内存屏障? Why Memory Barriers ?》
_kfifo_put( )是Kfifo的出队函数,源码实现如下:
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
fifo->out += len;
return len;
}连个if都不想用,真是太抠门了,哎。你多少if-else判断下in,out,len的关系,能让我舒服点呀!!!
4.1 Kfifo右侧入队
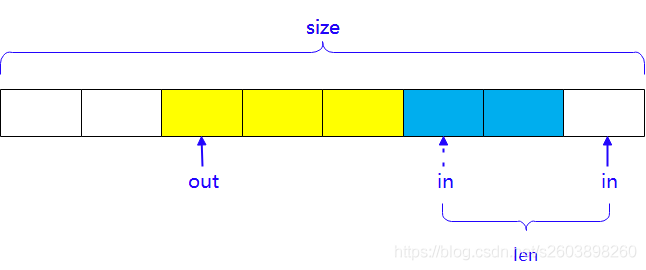
当fifo右侧剩余的空间充足时,即size - in%size > len时,直接将数据填充到右侧即可,位置为[in, in+len]。
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);in % size如何高效表示呢? 对,就是in & (size - 1)。这里有一个前提:那就是需要size是2的幂次方。Why ?
首先, in % size的范围为[0, size-1]; in & (size -1)的范围为[0, size-1]。
其次,它的原理是:size为2的幂次方,size -1则表示【0,size-1】每一个bit位都是1,可以得到该范围的所有值,这也是要求size为2的幂次方的原因。
最后,两者在本质上是等价的,但是in & (size -1)只进行位操作,效率高很多。
4.2 Kfifo右侧+左侧入队
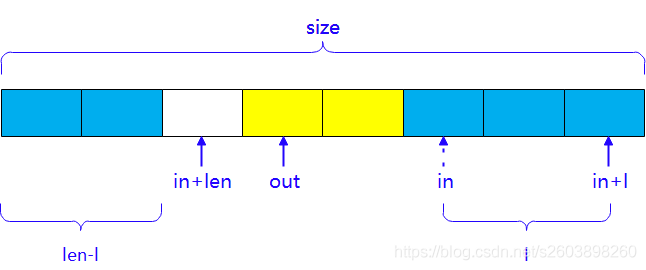
当右侧长度不够入队长度时,需要在kfifo左侧入队,此时kfifo左右的范围为【0,len-l】,左侧的范围为【in,in+l】。
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);4.3 无符号整数溢出回绕
首先看一个例子:
void main()
{
unsigned int a = 0xfffffffa;
unsigned int b = a + 10;
unsigned int c = 4;
printf("a = %u\n",a);
printf("b = %u\n",b);
printf("b - a =%d\n",b-a);
printf("c - a =%d\n",c-a);
}结果如下:
root@ubantu:/home/toney# gcc kfifo.c
root@ubantu:/home/toney# ./a.out
a = 4294967290
b = 4
b - a =10
c - a =10
root@ubantu:/home/toney# 解释如下:
a = 4294967290;
b = 4; //a + 10溢出4,--> 0x1 00 00 00 04
但是unsigned int为4字节共计32位,因此最高位无法获取,b只能获取后32bit,即0x00 00 00 04
b - a = -4294967285;即 0x1 FF FF FF F6
6 : 0110 --> 反码 1001 = 9
-4294967285在内存中的存储方式为:补码=反码+1,即0x1 00 00 00 09 +1 = 0x1 00 00 00 0a
因此b - a = 10;
因此,无论何时,即使发生整数回绕,kfifo中的变量都有如下关系:
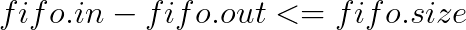
妙不可言呀!
可惜我体会还是没有那么深刻。
4. 体会
看完kfifo的实现,最大的感觉就是? 不不,文明人说文明话,妙,是真的妙不可言。如果说这代码是我或者同事写的,我会觉得里面会不会有很多bug,但是如果为内核大佬写的,我觉得没有,就是没有,真的没有呀!!!