一、什么是Java内存模型
Java内存模型(Java Memory Model,简称JMM)。在了解Java内存模型之前我们要先知道计算机的内存机制,现在大多数计算机都是多核CPU,每个CPU上都可以执行线程,而线程使用的数据都是储存在内存中,所以我们就需要从内存中去读取数据,但是这个过程对计算机来说是一个很慢很慢的的过程,而CPU处理指令的速度却是很快的,所以为了解决这两者之间速度的问题,就引入了高速缓存的概念,高速缓存分为L1、L2、L3多级,详细的看下图。
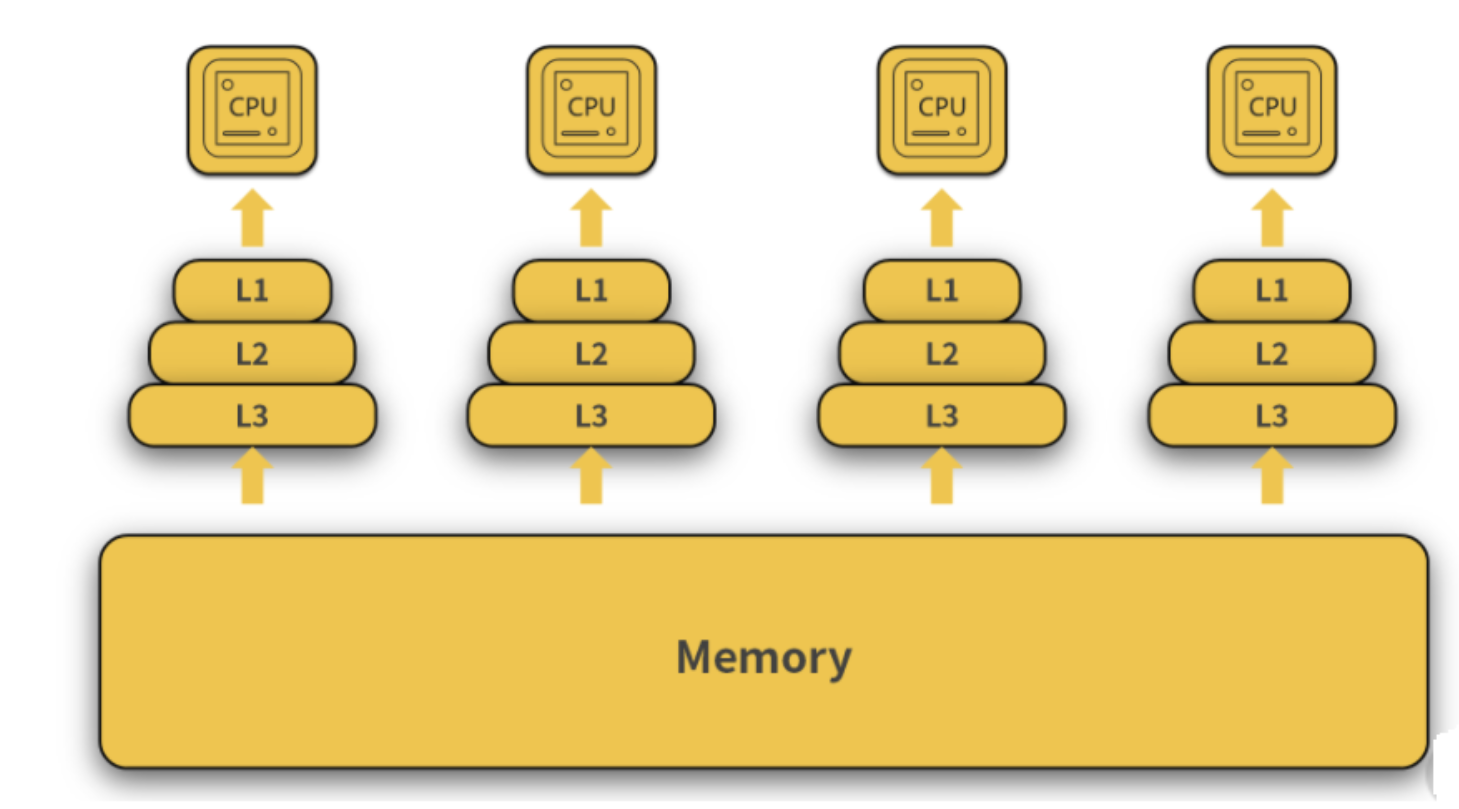
其中越靠近CPU的结构读取速度就越快,但是,储存能力也越弱。所以正常CPU在使用数据时,会先从内存中读取数据副本放到缓存中,然后CPU执行完毕后再把数据放回到内存中。而Java的内存模型和计算的设计有异曲同工之妙,我们看下图:
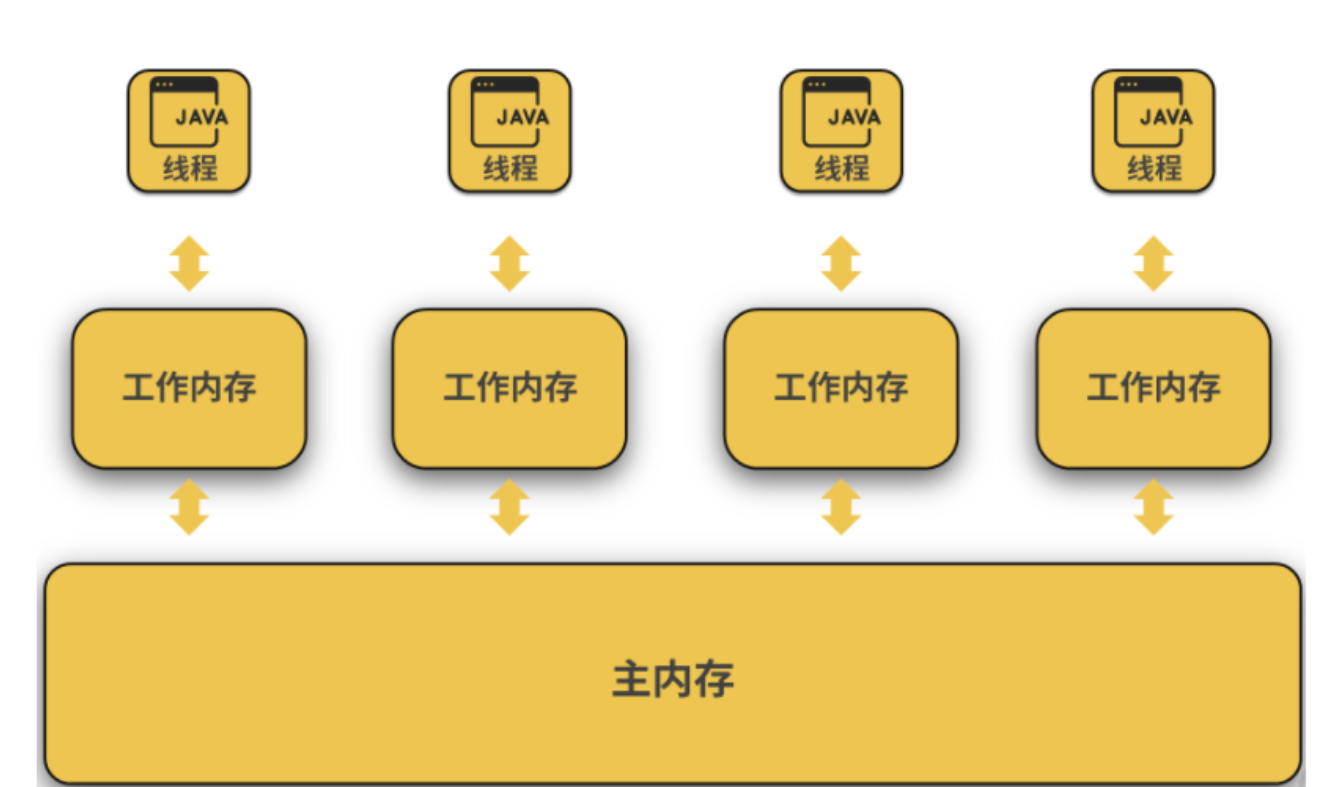
我们对比两张图就可以看出,Java内存模型的工作内存是每个线程独有的,大概相当于物理机中的多级缓存,其中储存的是对应线程使用的共享数据副本,而主内存是所有线程共享的,用来储存线程共同使用的共享数据。
整个 Java 内存模型的架构只是 Java 中的一个模型概念,无法与计算机中的物理硬件直接对应,工作内存也是是一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化,但是可以粗略类比:
从物理机的角度看,可以将工作内存对标到 CPU 的高速缓存,将主内存对标到我们的计算机内存条
从 JVM 的角度看,可以将工作内存对标到 JVM 栈,将主内存对标到 JVM 中的堆
Java内存模型带来的问题
Java 内存模型引入了主内存的概念,这虽然解决了多 CPU 共享数据的问题,但也带来了“工作内存与主内存数据一致性”的问题。
原子性
因为引入主内存的原因,我们代码执行不是原子性的问题就暴露出来了。我们的一段代码在计算机执行时会换成一条一条的指令,指令的执行不是原子的,意思就是在执行一个指令和另一个指令的中间,可能会扦插执行其他的指令,这样导致的后果就是代码执行的结果可能与我们预期的结果不一样。我们以下面的例子来说明:

线程1和线程2读取到数据后,都对数据进行了加1操作,但是由于加1操作不是原子性的,所以线程2也可以进行加1操作,最终结果count = 1与我们预期的就会有区别。一般为了解决这个问题我们可以使用synchronized的关键字,对代码上锁,来保证操作的原子性。
内存可见性
可见性是是站在工作内存的角度来说的,因为每个线程都有一个专属的工作内存,互相之间不影响,只能从主内存中读取数据,这就会导致可见性问题。比如线程1对数据进行了修改,但是在修改之后没有立刻把数据更新到主内存中,这时其他线程就获取不到数据的最新值,从而也会导致代码执行结果与预期出现差异。为了保证内存可见性我们可以使用Volatile关键字或者是Synchronized关键字。
指令重排序
我们写的代码在经过编译器时,会被翻译成一条条指令让计算机执行,这时计算机可能会对指令执行的顺序做出修改。再后续CPU 执行命令的过程中以及读写缓冲区的过程中,也都有可能出现重排序的问题,这也被称为“编译重排序”“指令重排序”和“内存重排序”。
但是无论怎样进行重排序优化,系统都会保证 as-if-serial 的语义,其具体含义是程序在单线程运行环境下得到的结果是正确的,言外之意也就是说在多线程中不能保证运行结果肯定是正确的。为了实现 as-if-serial 语义,在各个阶段的重排序优化中,不能对有数据依赖的操作进行重排序,因为有数据依赖的指令重排序之后,就会导致错误的运行结果。为了不让指令重排序我们可以使用Volatile关键字或者是Synchronized关键字。
二、Volatile关键字
前面我们反复提到了Volatile和Synchronized两个词,一般我们认为Synchronized更常用一些,因为它的功能更强大,但是使用代价也更大。而Volatile使用会更少一些,但是却更轻量。所以正确合理地使用volatile 关键字,会比 synchronized 等加锁实现方式的成本更低,这主要是因为 volatile 不会引起线程上下文的切换。
Volatile的作用
可以保证被Volatile修饰的变量的读操作具有原子性:我们这里的原子性是指的单一操作,不能保证复杂操作的原子性,像i++这样的操作就设计一次读和一次写操作,在有些机器上,由于硬件设计原因,读取一个64位的变量时,会分两步来读取,先读低32位,再读高32位,这就可能在线程1读取低32位时,其他线程修改了高32位的数据,从而导致一个不合法的数据出现,所以这时就可以用Volatile关键字来修饰这个变量。
可以保证内存可见性:被Volatile关键字修饰的变量,读操作会从内存中读取到最新的值,写操作会立刻写入内存中。
可以保证不发生指令重排序:被Volatile关键字修饰的变量在读写操作时不会发生重排序。
Volatile怎么实现的
可见性
首先,在写入 volatile 变量的时候,JVM 会向 CPU 发送 Lock 指令,Lock 指令有两个效果:
将当前工作内存中的数据写回到主内存中
写回操作涉及的数据会引起其他 CPU 核中缓存了该内存地址的数据无效(这主要是依靠 CPU 的嗅探功能实现的)
正是由于所有 CPU 核对 volatile 变量的缓存失效,后续对 volatile 变量的读取全部都会从主内存中读取最新版本的值
重排序
在 JVM 编译代码的时候,会对 volatile 变量做如下处理:
在每个 volatile 变量的写操作之前,插入一个 StoreStore 内存屏障:禁止 StoreStore 之前的普通读/写操作与 StoreStore 之后的 volatile 写进行重排序。
在每个 volatile 变量的写操作之后,插入一个 StoreLoad 内存屏障:禁止 StoreLoad 之前的 volatile 写操作与 StoreLoad 之后可能出现的 volatile 读/写操作进行重排序
在每个 volatile 变量的读操作之后,插入一个 LoadLoad 内存屏障:禁止 LoadLoad 之前的 volatile 读操作与 LoadLoad 之后的普通读操作进行重排序
在每个 volatile 变量的读操作之后,插入一个 LoadStore 内存屏障:禁止 LoadStore 之前的 volatile 读操作与 LoadStore 之后的普通写操作进行重排序
总结
Java内存模型引入了主内存和工作内存的概念,模拟了物理机的内存机制,有效的提高了代码的执行效率,但是也因此引入的原子性、内存可见性和指令重排序的一些问题。在后续解决问题的时,Volatile只能解决可见性和重排序问题,并不能解决复杂操作的原子性问题。