| http常考
|
https常考 Q: HTTPS 为什么安全? Q: HTTPS 的传输过程是怎样的? Q: 为什么需要证书? Q: 使用 HTTPS 会被抓包吗? |
一、HTTP
http请求由三部分组成,分别是:请求行、消息报头、请求正文
HTTP(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式,HTTP1.1版本中给出一种持续连接的机制,绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。
1、常用的HTTP方法有哪些?
GET、POST、PUT、HEAD、DELETE、OPTIONS
GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器。
POST:用于传输信息给服务器,主要功能与GET方法类似,但一般推荐使用POST方式。
PUT: 传输文件,报文主体中包含文件内容,保存到对应URI位置。
HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效。
DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件。
OPTIONS:查询相应URI支持的HTTP方法。
2、GET方法与POST方法的区别
1、get重点在从服务器上获取资源,post重点在向服务器发送数据;
2、get传输数据是通过URL请求,以field(字段)= value的形式,置于URL后,并用”?”连接,多个请求数据间用”&”连接,如http://127.0.0.1/Test/login.action?name=admin&password=admin,这个过程用户是可见的;post传输数据通过Http的post机制,将字段与对应值封存在请求实体中发送给服务器,这个过程对用户是不可见的;
3、Get传输的数据量小,因为受URL长度限制,但效率较高;Post可以传输大量数据,所以上传文件时只能用Post方式
4、get是不安全的,因为URL是可见的,可能会泄露私密信息,如密码等;post较get安全性较高
5、get方式只能支持ASCII字符,向服务器传的中文字符可能会乱码;post支持标准字符集,可以正确传递中文字符。
3、HTTP请求报文与响应报文格式
请求报文包含三部分:
a、请求行:包含请求方法、URI、HTTP版本信息
b、请求首部字段
c、请求内容实体
响应报文包含三部分:
a、状态行:包含HTTP版本、状态码、状态码的原因短语
b、响应首部字段
c、响应内容实体
4、常见的HTTP相应状态码
返回的状态
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
200:请求被正常处理
204:请求被受理但没有资源可以返回
206:客户端只是请求资源的一部分,服务器只对请求的部分资源执行GET方法,相应报文中通过Content-Range指定范围的资源。
301:永久性重定向
302:临时重定向
303:与302状态码有相似功能,只是它希望客户端在请求一个URI的时候,能通过GET方法重定向到另一个URI上
304:发送附带条件的请求时,条件不满足时返回,与重定向无关
307:临时重定向,与302类似,只是强制要求使用POST方法
400:请求报文语法有误,服务器无法识别
401:请求需要认证
403:请求的对应资源禁止被访问
404:服务器无法找到对应资源
500:服务器内部错误
503:服务器正忙
5、HTTP1.1版本新特性
a、默认持久连接节省通信量,只要客户端服务端任意一端没有明确提出断开TCP连接,就一直保持连接,可以发送多次HTTP请求
b、管线化,客户端可以同时发出多个HTTP请求,而不用一个个等待响应
c、断点续传原理
6、常见HTTP首部字段
a、通用首部字段(请求报文与响应报文都会使用的首部字段)
Date:创建报文时间
Connection:连接的管理
Cache-Control:缓存的控制
Transfer-Encoding:报文主体的传输编码方式
b、请求首部字段(请求报文会使用的首部字段)
Host:请求资源所在服务器
Accept:可处理的媒体类型
Accept-Charset:可接收的字符集
Accept-Encoding:可接受的内容编码
Accept-Language:可接受的自然语言
c、响应首部字段(响应报文会使用的首部字段)
Accept-Ranges:可接受的字节范围
Location:令客户端重新定向到的URI
Server:HTTP服务器的安装信息
d、实体首部字段(请求报文与响应报文的的实体部分使用的首部字段)
Allow:资源可支持的HTTP方法
Content-Type:实体主类的类型
Content-Encoding:实体主体适用的编码方式
Content-Language:实体主体的自然语言
Content-Length:实体主体的的字节数
Content-Range:实体主体的位置范围,一般用于发出部分请求时使用
二、Https
1、HTTP的缺点与HTTPS
a、通信使用明文不加密,内容可能被窃听
b、不验证通信方身份,可能遭到伪装
c、无法验证报文完整性,可能被篡改
HTTPS就是HTTP加上SSL加密处理(一般是SSL安全通信线路)+认证+完整性保护
2、HTTPS的SSL过程
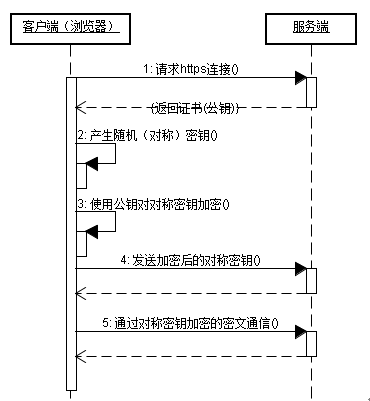
客户端浏览器在使用HTTPS方式与Web服务器通信时有以下几个步骤,如图所示。
 |
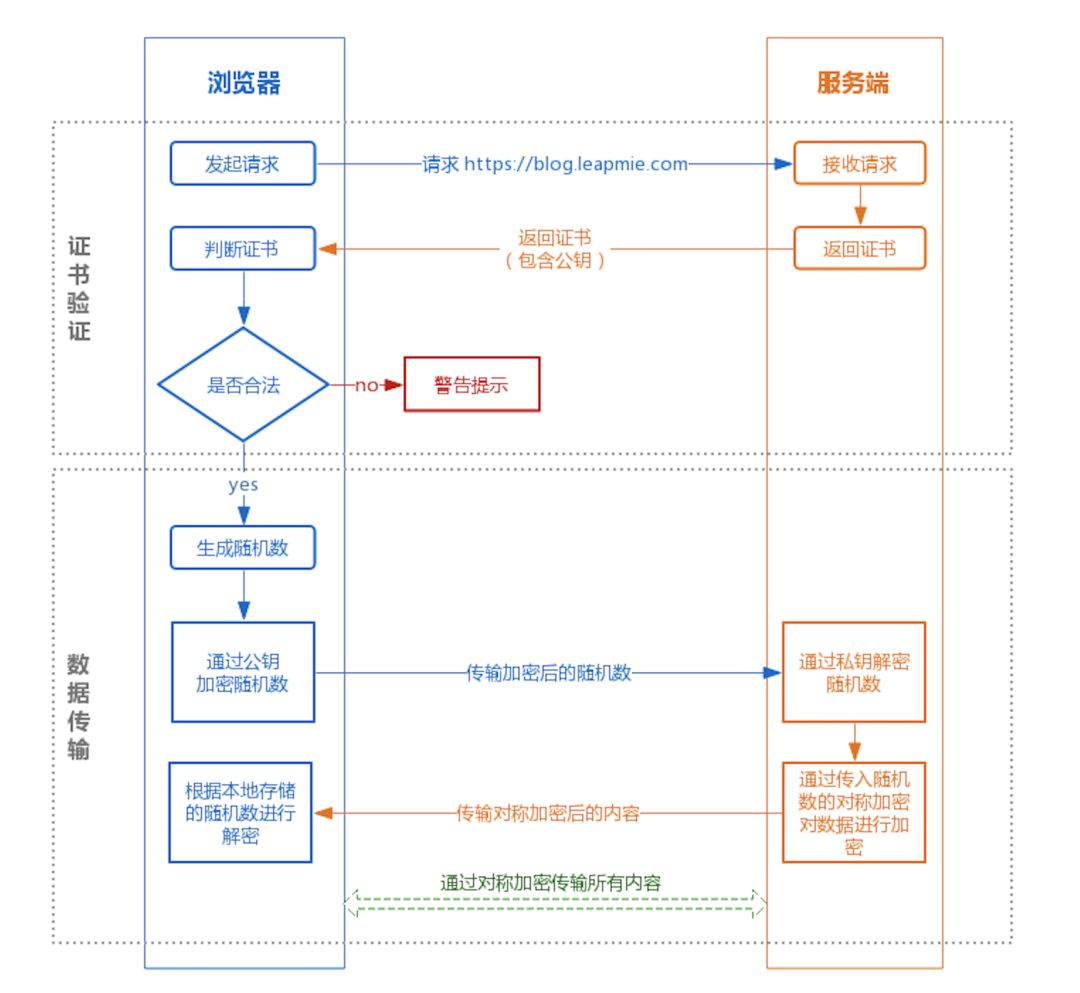 |
① 证书验证阶段 (1)浏览器发起HTTPS请求,要求与Web服务器建立SSL连接 (2)服务端返回HTTPS证书:Web服务器收到客户端请求后,会生成一对公钥和私钥,并把公钥放在证书中发给客户端浏览器 (3)客户端验证证书是否合法,如果不合法则提示告警 ② 数据传输阶段 |
3、为什么数据传输是用对称加密?
(1)首先,非对称加密的加解密效率是非常低的,而 http 的应用场景中通常端与端之间存在大量的交互,非对称加密的效率是无法接受的;
(2)另外,在 HTTPS 的场景中只有服务端保存了私钥,一对公私钥只能实现单向的加解密,所以 HTTPS 中内容传输加密采取的是对称加密,而不是非对称加密。
4、本地随机数被窃取怎么办?
证书验证是采用非对称加密实现,但是传输过程是采用对称加密,而其中对称加密算法中重要的随机数是由本地生成并且存储于本地的,HTTPS如何保证随机数不会被窃取?
答:其实HTTPS并不包含对随机数的安全保证,HTTPS保证的只是传输过程安全,而随机数存储于本地,本地的安全属于另一安全范畴,应对的措施有安装杀毒软件、反木马、浏览器升级修复漏洞等。
5、HTTPS抓包
(5.1)用了HTTPS会被抓包吗?
HTTPS 的数据是加密的,常规下抓包工具代理请求后抓到的包内容是加密状态,无法直接查看。但是,正如前文所说,浏览器只会提示安全风险,如果用户授权仍然可以继续访问网站,完成请求。因此,只要客户端是我们自己的终端,我们授权的情况下,便可以组建中间人网络,而抓包工具便是作为中间人的代理。通常HTTPS抓包工具的使用方法是会生成一个证书,用户需要手动把证书安装到客户端中,然后终端发起的所有请求通过该证书完成与抓包工具的交互,然后抓包工具再转发请求到服务器,最后把服务器返回的结果在控制台输出后再返回给终端,从而完成整个请求的闭环。
(5.2)既然HTTPS不能防抓包,那HTTPS有什么意义?
HTTPS可以防止用户在不知情的情况下通信链路被监听,对于主动授信的抓包操作是不提供防护的,因为这个场景用户是已经对风险知情。要防止被抓包,需要采用应用级的安全防护,例如采用私有的对称加密,同时做好移动端的防反编译加固,防止本地算法被破解。
6、CA证书
(6.1)为什么需要CA认证机构颁发证书?
HTTP协议被认为不安全是因为传输过程容易被监听者勾线监听、伪造服务器,而HTTPS协议主要解决的便是网络传输的安全性问题。首先我们假设不存在认证机构,任何人都可以制作证书,这带来的安全风险便是经典的 “中间人攻击” 问题。
(6.2)中间人攻击的过程和原理
“中间人攻击”的具体过程如下:
WX20191126-212406@2x.png
WX20191126-212406@2x.png
过程原理:
1.本地请求被劫持(如DNS劫持等),所有请求均发送到中间人的服务器
2.中间人服务器返回中间人自己的证书
3.客户端创建随机数,通过中间人证书的公钥对随机数加密后传送给中间人,然后凭随机数构造对称加密对传输内容进行加密传输
4.中间人因为拥有客户端的随机数,可以通过对称加密算法进行内容解密
5.中间人以客户端的请求内容再向正规网站发起请求
6.因为中间人与服务器的通信过程是合法的,正规网站通过建立的安全通道返回加密后的数据
7.中间人凭借与正规网站建立的对称加密算法对内容进行解密
8.中间人通过与客户端建立的对称加密算法对正规内容返回的数据进行加密传输
9.客户端通过与中间人建立的对称加密算法对返回结果数据进行解密
由于缺少对证书的验证,所以客户端虽然发起的是HTTPS请求,但客户端完全不知道自己的网络已被拦截,传输内容被中间人全部窃取。
(6.3)浏览器是如何确保CA证书的合法性?
(6.3.1)证书包含什么信息?颁发机构信息+公钥+公司信息+域名+有效期+指纹
(6.3.2)证书的合法性依据是什么?
首先,权威机构是要有认证的,不是随便一个机构都有资格颁发证书,不然也不叫做权威机构。
另外,证书的可信性基于信任制,权威机构需要对其颁发的证书进行信用背书,只要是权威机构生成的证书,我们就认为是合法的。所以权威机构会对申请者的信息进行审核,不同等级的权威机构对审核的要求也不一样,于是证书也分为免费的、便宜的和贵的。
(6.3.3)浏览器如何验证证书的合法性?验证域名和有效期等信息是否正确+判断证书来源是否合法+判断证书是否被篡改+判断证书是否已吊销
浏览器发起 HTTPS 请求时,服务器会返回网站的 SSL 证书,浏览器需要对证书做以下验证:
1.验证域名、有效期等信息是否正确。证书上都有包含这些信息,比较容易完成验证;
2.判断证书来源是否合法。每份签发证书都可以根据验证链查找到对应的根证书,操作系统、浏览器会在本地存储权威机构的根证书,利用本地根证书可以对对应机构签发证书完成来源验证;
WX20191127-084216@2x.png
WX20191127-084216@2x.png
3.判断证书是否被篡改。需要与 CA 服务器进行校验;
4.判断证书是否已吊销。通过CRL(Certificate Revocation List 证书注销列表)和 OCSP(Online Certificate Status Protocol 在线证书状态协议)实现,其中 OCSP 可用于第3步中以减少与 CA 服务器的交互,提高验证效率
以上所有步骤都满足的情况下浏览器才认为证书是合法的。
(6.3.4)证书是公开的,如何避免这种证书冒用的情况?
既然证书是公开的,如果要发起中间人攻击,我在官网上下载一份证书作为我的服务器证书,那客户端肯定会认同这个证书是合法的,如何避免这种证书冒用的情况?
答:其实这就是非加密对称中公私钥的用处,虽然中间人可以得到证书,但私钥是无法获取的,一份公钥是不可能推算出其对应的私钥,中间人即使拿到证书也无法伪装成合法服务端,因为无法对客户端传入的加密数据进行解密。
(6.3.5)只有认证机构可以生成证书吗?
如果需要浏览器不提示安全风险,那只能使用认证机构签发的证书。但浏览器通常只是提示安全风险,并不限制网站不能访问,所以从技术上谁都可以生成证书,只要有证书就可以完成网站的HTTPS 传输。例如早期的 12306 采用的便是手动安装私有证书的形式实现 HTTPS 访问。
7、HTTP优化
利用负载均衡优化和加速HTTP应用
利用HTTP Cache来优化网站