今天来说说缓存是怎么工作的。缓存这个词感觉在平时的工作中出现的频率那是相当的高啊,动不动这里缓存,哪里缓存,而且缓存与性能一般都是成对出现的。那么来看看缓存是如何工作的吧。
缓存的作用
当客户端发送一个请求的时候,如果经过一个缓存,发现缓存中正好有它请求的数据,那么就直接从缓存中返回这个数据,而不用向服务器索取数据。缓存有很多优点,它减少了冗余数据的传输,缓解了网络瓶颈问题,节省了带宽,降低了对原始服务器的需求,一部分请求不用发送到服务器,缓存直接就搞定了。缓存还能降低距离延迟,如果可以直接从在中国的缓存获取美国服务器上的数据,无疑降低了非常多的延迟。
如果许多客户端同时访问同一个服务器上的同一个资源,传统的方式服务器会向每个客户端你都发送该数据,这个时候网络上就发送着一大堆一样的数据,这十分浪费带宽!如果使用缓存,就可以保留第一条服务器响应的副本,后面的响应可以直接用这个副本解决了,提高了效率。
缓存还可解决带宽瓶颈。路径上最慢的网速是访问服务器的瓶颈。本地网络一般速度上都比较好,如果在在网速比较好的本地网络上有一个缓存,那么就可以直接使用非常快速的本地带宽进行传输。例如我想从美国的一个网页上下载一个图片,正常的下载整个链路要从中国到美国,中间肯定有比较低速的网络,而如果在我们附近有一个缓存,那么我们就可以高速的从这个缓存上下载所需要的图片了。
缓存还可以作为缓冲器解决瞬间拥塞问题。举个例子,有个一网站公布了一个劲爆的新闻,导致很多都想去访问这个网站,那么这个网站可能会在短时间内访问量暴增,超出它的承受范围。如果使用了缓存的话,当很多人想要去访问一个资源的时候,那么就可以在第一次访问之后直接从缓存上获取资源,从而分担了服务器的负载。
刚才提高的美国和中国缓存的问题。美国和中国是那么远,至于即使是光速也有些不能抹平,更加上网络上各种代理路由器,速度就更令人着急了,如果这个时候,有一个离客户端比较近的缓存,直接从缓存上获取资源,那么无疑会提高网络访问的速度。
缓存命中问题
当然缓存不肯能是万能的,它不可能包含世界上所有的资源,所以有些资源缓存里肯定是没有的。客户端可以直接从缓存中获取资源的情况被称为缓存命中。
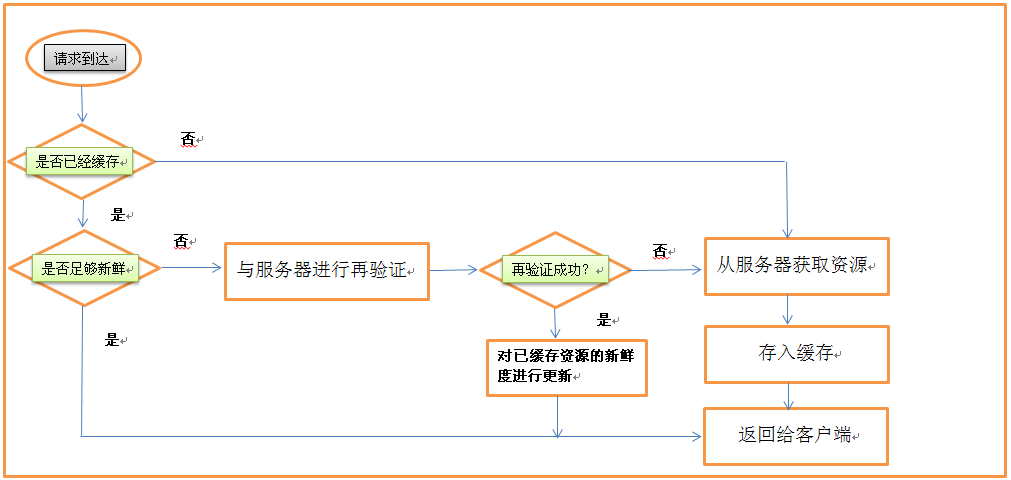
这里说一下再验证的问题。什么是再验证?当一个请求到达缓存的时候,缓存有这个资源的副本,但是他不知道这个副本过没过期,自己又不能进行决定,所以就向服务器发送验证请求,检测这个资源的内容是不是最新的。缓存可以在任意时刻,以任意频率对副本进行验证,但是为了节省带宽,基本上客户端发起请求的时候才会进行验证。在进行在验证的时候,缓存会向服务器发送一个再验证请求,如果内容没有变化,服务器则会返回一个304 NOT MODIFIED的响应,这就说明这个副本是暂时新鲜的,就可以返回给客户端了。这就就叫做再验证命中或者缓慢命中。如果副本过期,那么服务器就直接返回一个响应报文,报头为 200 ok,这个响应报文会发回给客户端。
速度上,再验证命中比未命中快一些,毕竟未命中还需要传输这个资源。如果服务器上已经删除了这个对象,那么服务器会返回一个404 NOT FOUND响应,缓存接收到这个响应,也会删这个资源的副本,同时将响应回送。
既然有命中和未命中的问题,那么就一定存在命中率的问题咯。缓存的命中率分为字节命中率和文档命中率。字节命中率表示缓存中所提供的字节在所有传输字节的中的比率,文档命中率是缓存提供的文件的个数在所有传输的文件中所占的比例。出现这两种度量标准是由于有的文件访问量不大,但是个头很大,从带宽上算来,其实这种文件是占据很大比例的,所以这里使用文件命中率就不太科学了。
客户端如何判断一个资源是否从缓存中来的呢?基本上有两种方法,一种是有的缓存在返回资源时候,会在回送响应中添加VIA首部,表示这是从缓存中返回的。第二种方法使查看返回响应报文的DATE首部,如果这个首部比起现在的时间早很多,那么很有可能这个资源就是由缓存中返回的。(DATE首部记录的是该响应于服务器产生的时间。)
缓存的拓补结构
缓存可以分为公有缓存和私有缓存。大部分的缓存都是公有缓存,由于缓存的工作机制,公有缓存能更有效地提高网络性能。私有缓存往往会存在于我们经常使用的浏览器中,这个用的比较少。
公有缓存是特殊的共享代理服务器,被称为缓存代理服务器。它汇聚用户的请求,在具有副本的时候应答客户端的请求。只要一个用户请求过一次,缓存中存在这个资源的副本,那么之后发送到这个缓存上的这个资源的请求,在这个副本没有过期的时候,就可以直接返回这个副本了。所以公有的缓存可以有效地降低网络流量。
代理缓存的层次结构
网络中经常出现种种层次结构,同样缓存也存在层次结构。例如一个二级缓存,靠近客户端的地方使用小型廉价缓存,更高层次,则逐渐使用更强大的缓存来装载更多的资源。目标是希望大部分用户都能在附近的第一级缓存中命中,如果没有命中,向上寻找较大父级缓存的帮助,如果仍未命中则向原始服务器发出请求。当然如果缓存结构比较深的话,每一个缓存都会有一些性能损耗,多个缓存叠加在一起性能损耗就比较明显了。
除了层次缓存结构之外,也存在网状缓存。这些缓存之间的结构比较复杂,当请求到来的时候,缓存会做出动态的判断,决定于其他哪个缓存进行通信。网状缓存需要完成这些功能:
- 根据URL在父缓存或者原始服务器中进行动态选择
- 根据URL动态的选择一个特定的父服务器
- 前往父缓存之前,在本地缓存中搜索已缓存的副本
- 允许其他缓存对其缓存的部分内容进行访问,但不允许因特网流量通过他们的缓存
缓存之间这些更加复杂的关系允许不同的组织互为对等实体,将它们的缓存连接起来以实现共赢。
缓存的处理步骤
对一条HTTP GET报文的基本缓存处理过程包括七个步骤:
- 接收:从网络中接收请求报文
- 解析:缓存对报文进行解析,提取出URL和各种首部
- 查询:缓存查看是否有本地副本可以用,如果没有就获取一份副本,并将它保存在本地。
- 新鲜度检测:缓存查看已缓存副本是否足够新鲜,如果不是,就向服务器询问是否有任何更新
- 创建响应:缓存会用新的首部和已缓存的主体来构建一条响应报文。
- 发送:缓存通过网络将响应发送给客户端
- 日志:缓存可选的创建一个日志文件条目来描述这个事务。
tips:
- 已缓存对象包含了服务器的响应主体和原始服务器的响应首部,在缓存命中的时候正确返回响应报文,其中有一些元数据如记录响应报文真实产生时间等。
- 缓存服务器中的资源有保质期,在这个时间范围内都认为该资源时新鲜的,不用进行判断。如果过了保质期,那么就需要向服务器进行再验证。
- 缓存会将原来缓存的服务器的响应作为基础,对其进行改造并生成返回给客户端的响应。例如可能会向响应中插入新鲜度信息,或者VIA等代理信息等。
缓存处理GET请求的流程图: