简介
哈希表,也称散列表,是实现字典操作的一种有效的数据结构。尽管在最坏的情况下,散列表查找一个元素的时间复杂度与链表中查找的时间相同,达到了O(n),然而实际应用中,散列表查找的性能是极好的,在一些合理的假设下,在散列表中可以查找一个元素的平均时间是O(1)。
哈希表的精髓在于哈希二字上面,也就是数学里面常用到的映射关系,它是通过哈希函数将关键字映射到表中的某个位置上进行存放,以实现快速插入和查询的。
为什么需要哈希函数?简单来说,解决存储空间的考虑。试想,将100个关键字存入大小为100的数组里,此时肯定是不需要哈希函数的,一对一的放,肯定是可以实现的。但是当数据量增大,将1000个关键字,存入大小为100的数组里呢?此时一个一个的放,那剩下的怎么办呢,所以,我们需要某种计算方法,既能把这1000个关键字存进去,而且最主要是还能取出来。这就是哈希函数要做的事情,给每一个关键字找一个合适的位置,让你既能存进去,又能取出来。注意,哈希表里面一般存放的是字典数据类型,即(key,value)的数据,是根据key 去存取value。
解决冲突的方法
通过哈希函数去计算哈希值,难免会有冲突的时候,解决冲突的方法有如下几种:
-
开放定址法:依靠数组中的空位解决碰撞冲突
- 线性探测法:直接检测散列表的下一个位置(即索引值加1),如果仍冲突,继续;
- 二次探测法:即H + 1^2, H + 2^2, H + 3^2…
- 伪随机探测
-
再哈希法:使用多个哈希函数,第一个冲突时,使用第二个哈希函数,知道不冲突为止;
- 链地址法:将所有哈希地址相同的关键字,都链接到同一个链表中;
散列函数
在使用开链法解决冲突问题时,将哈希表内的元素称为桶(bucket),大约意义是,表格内的每个单元,涵盖的不只是个节点(元素),甚至可能是一“桶”节点。
假设哈希表中共有M个元素(桶),编号为0,1,..,M-1。 现在哈希函数要做的就是将关键字映射到这M个桶中,尽量保证均匀。
最常用的是除留余数法计算哈希值:用一个特定的质数来除所给定的关键字,所得余数即为该关键字的哈希值。
哈希表设计
在此,仿STL的hashtable实现一个简化版的哈希表,作为本文的结束。
采用开链法处理冲突,然后hashtable以vector作为底层数组,键值类型的话,直接用template;
哈希表节点
哈希表节点定义如下:
template<class Value>
struct hashtable_node{
hashtable_node *next;
Value val;
};桶里的链表也自己实现,不使用STL里面提供的list;
哈希表
首先理清哈希表需要的模板类型 Key, Value
只做最简单的(Key, Value), Key的类型考虑char, int, double, string
下面给出哈希表的定义,本文只考虑几个比较常用的操作,即插入,删除,查找,返回大小,最后再加上一个打印哈希表的函数,具体定义如下:
template<class Key, class Value>
class hashtable{
public:
//哈希表节点键值类型
typedef pair<Key, Value> T;
//表节点
typedef hashtable_node<T> node;
public:
//构造函数
hashtable();
hashtable(hashtable<Key, Value> &ht)
: buckets(ht.buckets), num_elements(ht.num_elements)
{}
//插入一个关键字
void insert(T kv);
//根据键值删除关键字
void erase(Key key);
//判断关键字是否在哈希表中
bool find(Key key);
//返回哈希表中关键字个数
int size(){
return num_elements;
}
void printHashTable();
private:
//根据传入大小判断是否需要重新分配哈希表
void resize(int num_elements);
//根据键值返回桶的编号
int buckets_index(Key key, int size){
return hash(key) % size;
}
//根据节点返回键值
Key get_key(T node){
return node.first;
}
private:
//使用STL list<T>作桶
vector<node*> buckets;
//哈希表中元素个数
size_t num_elements;
//哈希函数
hashFunc<Key> hash;
};哈希函数
哈希函数的设计,由于只考虑了char, int, double, string四种类型,在使用模板类的话,可以通过template的偏特化特性直接为这四种类型设计特化版本。相关代码如下
/*
* 哈希函数的设定,只考虑 4 种键值类型的哈希函数
* char, int , double , string
*/
template<class Key> struct hashFunc{};
template<> struct hashFunc < char > {
size_t operator()(char x) const { return x; }
};
template<> struct hashFunc < int > {
size_t operator()(int x) const { return x; }
};
template<> struct hashFunc < double > {
size_t operator()(const double & dValue) const
{
int e = 0;
double tmp = dValue;
if (dValue<0)
{
tmp = -dValue;
}
e = ceil(log(dValue));
return size_t((INT64_MAX + 1.0) * tmp * exp(-e));
}
};
template<> struct hashFunc < string > {
size_t operator()(const string & str) const
{
size_t h = 0; for (size_t i = 0; i<str.length(); ++i)
{
h = (h << 5) - h + str[i];
}
return h;
}
};哈希表的具体实现
下面贴出哈希表的具体实现代码吧,关于各个函数的实现,都给出了相关注释,应该算是简单易懂的。
//将表格的大小设为质数,然后直接使用除留余数法求哈希值
//按照SGI STL中的原则,首先保存28个质数(逐渐呈现大约两倍的关系),
//同时提供一个函数,用来查询在这28个质数中,最接近某数并大于某数的质数
static const int num_primes = 28;
static const unsigned long prime_list[num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
//找出最接近但大于的质数
inline unsigned long next_prime(unsigned long n){
const unsigned long *first = prime_list;
const unsigned long *last = prime_list + num_primes;
const unsigned long *pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
//构造函数,初始化哈希表
template<class Key, class Value>
hashtable<Key, Value>::hashtable(){
const int n_buckets = next_prime(1);
buckets.reserve(n_buckets);
buckets.insert(buckets.end(), n_buckets, (node*)0);
num_elements = 0;
}
//插入一个关键字
template<class Key, class Value>
void hashtable<Key, Value>::insert(T kv){
//在插入之前,调用resize函数,判断是否需要重建哈希表
resize(num_elements + 1);
//计算出插入位置
int pos = buckets_index(kv.first, buckets.size());
node *head = buckets[pos];
//判断键值是否已经存在,若存在,则直接返回,不插入
for (node *cur = head; cur; cur = cur->next){
if (cur->val.first == kv.first)
return;
}
//分配节点,插入
node *tmp = new node(kv);
tmp->next = head;
buckets[pos] = tmp;
num_elements++; //记录个数
}
//根据键值删除关键字
template < class Key, class Value>
void hashtable<Key, Value>::erase(Key key){
//找出桶的位置
int pos = buckets_index(key, buckets.size());
node *head = buckets[pos];
node *pre = NULL;
while (head){
//查找到对应键,并删除
if (head->val.first == key){
if (pre == NULL){
buckets[pos] = head->next;
delete head;
num_elements--;
return;
}
else{
pre->next = head->next;
delete head;
num_elements--;
return;
}
}
pre = head;
head = head->next;
}
}
//根据键值,判断是否在哈希表中
template<class Key, class Value>
bool hashtable<Key, Value>::find(Key key){
int pos = buckets_index(key, buckets.size());
node *head = buckets[pos];
while (head){
if (head->val.first == key)
return true;
head = head->next;
}
return false;
}
template<class Key, class Value>
void hashtable<Key, Value>::resize(int num_elements){
//当元素个数大于桶的个数时,重新分配哈希表
const int size = buckets.size();
if (num_elements <= size) return;
//找出下一个质数
const int next_size = next_prime(num_elements);
//初始化新的哈希表
vector<node*> tmp(next_size, (node*)0);
for (int i = 0; i < size; ++i){
node *head = buckets[i];
while (head){
int new_pos = buckets_index(head->val.first, next_size);
buckets[i] = head->next;
head->next = tmp[new_pos];
tmp[new_pos] = head;
head = buckets[i];
}
}
//交换新旧哈希表
buckets.swap(tmp);
}
template<class Key, class Value>
void hashtable<Key, Value>::printHashTable(){
cout << "哈希表内容如下 :" << endl;
for (int i = 0; i < buckets.size(); ++i){
node *head = buckets[i];
while (head){
cout << head->val.first << " " << head->val.second << endl;
head = head->next;
}
}
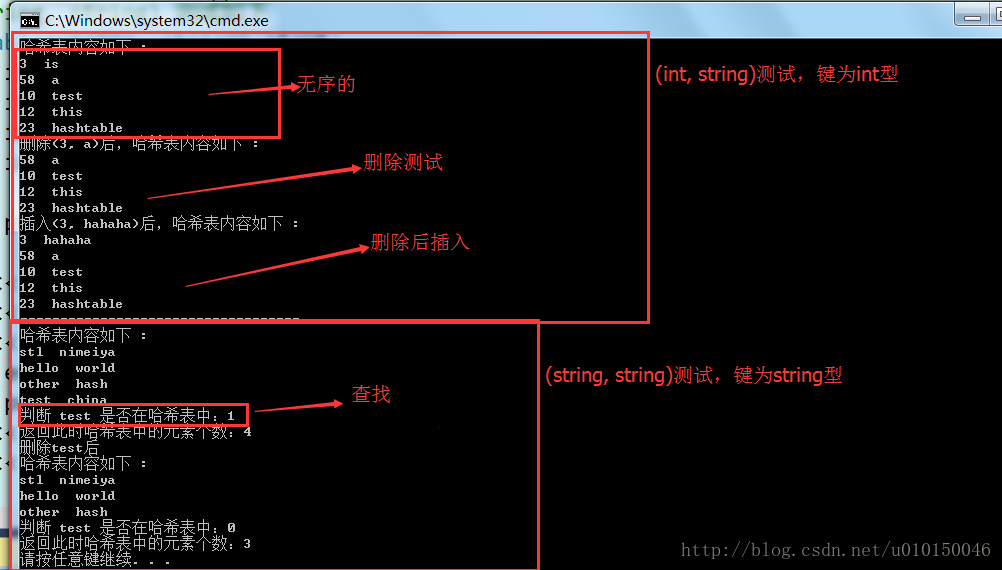
}测试结果(测试代码如下)
代码整理
hashfunc.h
#ifndef _HASHFUNC_H_
#define _HASHFUNC_H_
#include<math.h>
#include<stdint.h>
#include<iostream>
#include<algorithm>
#include<string>
using namespace std;
/*
哈希函数的设定,只考虑四种键值类型的哈希函数
*/
template<class Key> struct hashFunc{};
template<> struct hashFunc <char>{
size_t operator()(char x) const{
return x;
}
};
template<> struct hashFunc <int> {
size_t operator()(int x) const{ return x; }
};
template<> struct hashFunc <double> {
size_t operator()(const double & dValue) const{
int e = 0;
double tmp = dValue;
if (dValue < 0){
tmp = -dValue;
}
e = ceil(log(dValue));
return size_t((INT64_MAX + 1.0) * tmp * exp(-e));
}
};
template<> struct hashFunc <string> {
size_t operator()(const string& str) const{
size_t h = 0;
for (size_t i = 0; i < str.length(); i++){
h = (h << 5) - h + str[i];
}
return h;
}
};
//将表格的大小设置为质数,然后直接使用保留余数法求哈希值
//按照SGI STL中的原则,首先保存28个质数(逐渐呈现大约2倍的关系)
//同时提供一个函数,用来查询在这28个质数中,最接近某数并大于某数的质数
static const int num_primes = 28;
static const unsigned long prime_list[num_primes] = {
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
//找出最接近但大于目的数字的质数
inline unsigned long next_prime(unsigned long n){
const unsigned long* first = prime_list;
const unsigned long* last = prime_list + num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
#endifhashtable.h
#ifndef _HASHTABLE_H_
#define _HASHTABLE_H_
#include<vector>
#include<list>
#include<iostream>
#include<algorithm>
#include"hashfunc.h"
using namespace std;
//哈希节点,包括键值和指针
template<class T>
struct hashtable_node{
hashtable_node* next;
T val;
hashtable_node(T val) :val(val), next(NULL){}
};
template<class Key, class Value>
class hashtable{
public:
//哈希表节点键值类型
typedef pair<Key, Value> T;
//表节点
typedef hashtable_node<T> node;
private:
vector<node *> buckets;
//哈希表中元素的个数
size_t num_elements;
//哈希函数
hashFunc<Key> hash;
public:
//构造函数
hashtable();
hashtable(hashtable<Key, Value>& ht) :buckets(ht.buckets), num_elements(ht.num_elements){}
//插入一个关键字
void insert(T kv);
//根据键值删除关键字
void erase(Key key);
//判断关键字是否在哈希表中
bool find(Key key);
//返回哈希表中关键字的个数
int size(){
return num_elements;
}
void printHashTable();
private:
//根据传入大小判断是否需要重新分配哈希表
void resize(int num_elements);
//根据键值返回桶的编号
int buckets_index(Key key, int size){
return hash(key) % size;
}
//根据节点返回键值
Key get_key(T node){
return node.first;
}
};
//构造函数
template<class Key, class Value>
hashtable<Key, Value>::hashtable(){
const int n_buckets = next_prime(1);
buckets.reserve(n_buckets);
buckets.insert(buckets.end(), n_buckets, (node*)0);
num_elements = 0;
}
template<class Key, class Value>
void hashtable<Key, Value>::insert(T kv){
//在插入前,调用resize函数,判断是否需要重建哈希表
resize(num_elements + 1);
//计算出插入位置
int pos = buckets_index(kv.first, buckets.size());
node *head = buckets[pos];
//判断键值是否已经存在,若存在,则直接返回,不插入
for (node *cur = head; cur; cur = cur->next){
if (cur->val.first == kv.first) return;
}
//分配节点,插入
node* tmp = new node(kv);
tmp->next = head;
buckets[pos] = tmp;
num_elements++;
}
//根据键值删除关键字
template<class Key,class Value>
void hashtable<Key, Value>::erase(Key key){
//找出桶的位置
int pos = buckets_index(key, buckets.size());
node* head = buckets[pos];
node* pre = NULL;
while (head){
//查找对应键,并删除
if (head->val.first == key){
if (pre == NULL){
buckets[pos] = head->next;
delete head;
num_elements--;
return;
}
else{
pre->next = head->next;
delete head;
num_elements--;
return;
}
}
pre = head;
head = head->next;
}
}
//根据键值,判断是否在哈希表中
template<class Key, class Value>
bool hashtable<Key, Value>::find(Key key){
int pos = buckets_index(key, buckets.size());
node* head = buckets[pos];
while (head){
if (head->val.first == key)return true;
head = head->next;
}
return false;
}
template<class Key, class Value>
void hashtable<Key, Value>::resize(int num_elements){
//当元素个数大于桶的个数时,重新分配哈希表
const int size = buckets.size();
if (num_elements <= size)return;
//找出下一个质数
const int next_size = next_prime(num_elements);
//初始化新的哈希表
vector<node *> tmp(next_size, (node *)0);
for (int i = 0; i < size; i++){
node *head = buckets[i];
while (head){
int new_pos = buckets_index(head->val.first, next_size);
buckets[i] = head->next;
head->next = tmp[new_pos];
tmp[new_pos] = head;
head = buckets[i];
}
}
buckets.swap(tmp);
}
template<class Key, class Value>
void hashtable<Key, Value>::printHashTable(){
cout << "哈希表内容如下: " << endl;
for (int i = 0; i < buckets.size(); i++){
node *head = buckets[i];
if (!head)continue;
cout << "buckets[" << i << "]->";
while (head){
cout <<"("<< head->val.first << " , " << head->val.second <<")->";
head = head->next;
}
cout << endl;
}
}
#endifmain.cpp
#include"hashtable.h"
int main()
{
//(int, string) 测试如下:
hashtable<int, string> ht;
ht.insert(pair<int, string>(12, "this"));
ht.insert(pair<int, string>(3, "is"));
ht.insert(pair<int, string>(58, "a"));
ht.insert(pair<int, string>(10, "test"));
ht.insert(pair<int, string>(23, "hashtable"));
ht.printHashTable();
cout << "删除(3, a)后,";
ht.erase(3);
ht.printHashTable();
cout << "插入(3, hahaha)后,";
ht.insert(pair<int, string>(3, "hahaha"));
ht.printHashTable();
cout << "===================================" << endl;
//(string, string) 测试如下
hashtable<string, string> strHt;
strHt.insert(pair<string, string>("hello", "world"));
strHt.insert(pair<string, string>("other", "hash"));
strHt.insert(pair<string, string>("test", "china"));
strHt.insert(pair<string, string>("stl", "nimeiya"));
strHt.printHashTable();
cout << "判断 test 是否在哈希表中:" << strHt.find("test") << endl;
cout << "返回此时哈希表中的元素个数:" << strHt.size() << endl;
cout << "删除test后" << endl;
strHt.erase("test");
strHt.printHashTable();
cout << "判断 test 是否在哈希表中:" << strHt.find("test") << endl;
cout << "返回此时哈希表中的元素个数:" << strHt.size() << endl;
}