链表是最基本的数据结构,凡是学计算机的必须的掌握的,在面试的时候经常被问到,关于链表的实现,百度一下就知道了。在此可以讨论一下与链表相关的练习题。
1、在单链表上插入一个元素,要求时间复杂度为O(1)
解答:一般情况在链表中插入一元素是在末尾插入的,这样需要从头遍历一次链表,找到末尾,时间为O(n)。要在O(1)时间插入一个新节点,可以考虑每次在头节点后面插入,即每次插入的节点成为链表的第一个节点。
2、给定一个链表,判断是否有环。
解答:这个是一个经典的问题了,思路也很简单,我们首先设置两个指针p1,p2同时指向链表的头部,然后p1每次向后走1步,p2每次向后走2步。如果有环,那么有一步会出现p1=p2,如果p2已经到达了尾结点,则无环。复杂度:时间:O(n),空间:O(1)
扩展:给定一个链表,找出环的入口位置。思路也是一样,用p1,p2指针。只是需要多做一步,那就是当p1=p2的时候,将p1重新指向链表的头结点,然后p1和p2都每次向后走一步,下一次p1=p2的结点就是环的入口。复杂度:时间:O(n),空间:O(1)
3、遍历单链表一次,找出链表中间节点
解答:定义两个指针p和q,初始都指向链表头节点。然后开始向后遍历,p每次移动2步,q移动一步,当p到达末尾的时候,p正好到达了中间位置。
4、单链表逆置,不允许额外分配存储空间,不允许递归,可以使用临时变量,执行时间为O(n)
解答:这个题目在面试笔试中经常碰到,基本思想上将指针逆置。如下图所示:

实现:
Node* reverse_list(Node *head){
Node *cur=head;
Node *pre = NULL;
Node *post = cur->next;
// Node *reverse_head = cur;
while(post){
cur->next = pre;
pre = cur;
cur = post;
post = post->next;
}
cur->next = pre;
// reverse_head = cur;
return cur;
}
扩展:链表翻转。给出一个链表和一个数k,比如,链表为1→2→3→4→5→6,k=2,则翻转后2→1→6→5→4→3,若k=3,翻转后3→2→1→6→5→4,若k=4,翻转后4→3→2→1→6→5,用程序实现。
实质是也是逆置,只不过是两个链表逆置后再串联起来。实现如下:
bool rotate_list(Node *head,int k,Node* &newhead){
if(k < 0)
return false;
else if(0 == k)
return true;
int len = 0;
Node *node=head;
while(node){
++len;
node = node->next;
}
if(k > len)
return false;
Node *one_end,*two_start;
node = head;
Node *post = node->next;
int n=k;
if(1 == n){
}else{
while(n > 1){// rotate sublist one
node->next = post->next;
post->next = head;
head = post;
post = node->next;
--n;
}
}
if(len-k <= 1){ // rotate sublist two
}else{
one_end = node;
node = post;
post = post->next;
two_start = node;
n = len-k;
while(n>1){
one_end->next = post;
node->next = post->next;
post->next = two_start;
two_start = post;
post = node->next;
--n;
}
}
newhead = head;
return true;
}
5、用一个单链表L实现一个栈,要求push和pop的操作时间为O(1)
解答:根据栈中元素先进后出的特点,可以在链表的头部进行插入和删除操作
6、用一个单链表L实现一个队列,要求enqueue和dequeue的操作时间为O(1)
解答:队列中的元素是先进先出,在单链表结构中增加一个尾指针,数据从尾部入队,从头
部入队。
7、给定两个链表(无环),判断是否有相交。
解答:首先明确一点,如果两个链表相交,那么从第一个交点开始到尾结点结束,所有的结点都是公共结点。所以,两个有公共结点而部分重合的链表,拓扑形状看起来像一个Y,而不可能像X。
这也就是说,如果两个链表相交,那么这两个链表的尾结点肯定是公共结点,如果尾结点不是公共结点,那么这两个链表肯定不相交。
所以我们可以如下操作:依次遍历两个链表,最后判断尾结点是否相同,如果相同,则相交,如果不相同,则不相交。复杂度:时间:O(m+n),空间:O(1)
或者一个链表的头结点指向另一个链表的尾节点,判断是否有环。
8、给定两个链表(无环),找到第一个公共节点。
解答:我们最容易想到的是从尾结点开始挨个向前比较,最后一个相同的就是第一个公共结点。(从后往前遍历)
但是单链表只能从前往后进行遍历,如果想要从后往前的话则需要先从前向后遍历一次,同时用栈来记录每一个结点,最后出栈,然后挨个对比,这样的确可行,但是却要额外付出O(m+n)的空间,时间复杂度O(mn)。(单链表+栈)
仔细想想,我们可以先分别遍历两个单链表,记录长度m和n(无妨假设m>n),然后先让长度为m的链表向后走(m-n)步,接着两个链表同时向后遍历,第一个相同的结点就是要求的第一个公共结点。复杂度:O(m+n)m,n分别为两个链表的长度;空间:O(1)
PS:另外还有一种巧妙的方法是把在一个链表尾部插入另一个链表,然后判断合成的新链表是否有环。环入口即为第一个公共点。
可参考:http://blog.csdn.net/wcyoot/article/details/6426436
扩展:两个链表,找出他们的第一个交点,要求每个链表只能遍历一次,可以对链表进行任何操作,空间O(1).
题目告诉说可以对链表进行任何操作,这是一个没有用到的条件(大家一定要注意到题目中没有用到的条件,往往是解题的关键所在)。
1.遍历第一个链表List1,将每一个节点的next都置为NULL。
2.遍历第二个链表List2,List2的尾节点就是第一个交点。
9、 给定2个链表,求这2个链表的并集(链表)和交集(链表)。不要求并集(链表)和交集(链表)中的元素有序。输入:List1:10->15->4->20,List2:8->4->2->10输出:交集(链表):4->10;并集(链表):2->8->20->4->15->10
法一:简单直观的方法:
InterSection(list1,list2):初始化结果链表为空,遍历链表1,在链表2中查找它的每一元素,如果链表2中也有这个元素,则将该元素插入到结果链表中。
Union(list1,list2): 初始化结果链表为空,将链表1中的所有元素都插入到结果链表中。遍历链表2,如果结果链表中没有该元素,则插入,否则跳过该元素。
法二:可适应归并排序,not clear。
法三:Hash法
Union(list1,list2),首先用链表1初始化结果链表,创建一个空的hash表。遍历链表1,将链表中的元素插入到hash表。然后遍历list2,对于list2中的元素,如果hash表中不存在该元素,则同时将该元素插入到结果链表中,如果hash表中已经存在,则忽略该元素,继续遍历下一个元素。
InterSection(list1,list2),首先初始化结果链表为NULL,创建一个空的hash表。遍历list1,将list1中的每一个元素都插入到hash表中。然后遍历list2,对于list2中的元素,如果已经存在于hash表中,则将该元素插入到结果链表,如果不存在与hash表中,则忽略该元素,继续遍历下一个元素。
参考:http://blog.csdn.net/lalor/article/details/7430631
10、从单链表返回倒数第n个元素
普通,基本思路就是用栈,一一压栈,再弹栈,第n个元素就可出来。
进阶,看到栈,就应该想到递归,递归是天然的栈。用全局变量,实现如下:
Node* pn_elem = NULL;
int nn;
void recursive(Node* node){
if(!node) return ;
recursive(node->next);
if(1==nn) pn_elem = node;
--nn;
}
高级,维护两个指针,两个指针相差n个元素,当前面的指针到达链表末尾,后面指针所指的元素即是所求的元素。实现如下
Node* last_n_elem(Node*node,int n){
if(node! || n<1) returnNULL;
Node *p=node,*q=node;
while(n>0 && q){
q=q->next;
--n;
}
while(q){
q=q->next;
p=p->next;
}
return p;
}11、链表元素去重,从未排序的链表中移除重复的项。
思路:可使用额外的空间的话,可以用数组存数字,实现最好的方式就是哈希表啦。遍历一下即可。
实现:
std::map<Node*, bool>hash;
void duplicate_remove(Node *node){
if(!node) return ;
Node *post=node->next;
hash[node->data] = true;
while(post){
if(hash[post->data]){
Node *temp = post;
post = post->next;
node->next = post;
delete temp;
}else{
hash[post->data] = true;
node = post;
post = post->next;
}
}
}
如果不允许使用临时缓存,怎么解决?
思路:用两个指针。当某个指针指向某个元素时,另一个指针将后面的相同元素全部删除。复杂度O(n^2)。具体实现就不写了。
12、链表求和问题。
该问题基本上有两个类型:
a、1->2->5->4 , 2->5->3->4,得3->7->8->8.
思路:先加高位,再加低位。两个0~9的数相加,要么不进位,要么进位为1.用两个指针,p指向当前进位点,q指向当前操作点。当然第一个元素得特殊考虑,可能进位嘛。
自己实现:
Node* merge_list_add(Node *list1,Node *list2){
Node*q1=list1,*q2=list2,*ans=NULL,*pre=NULL,*p=NULL,*q=NULL;
int cvalue = q1->data+ q2->data;
bool flag = false;
ans = new Node();
// node 1
if(cvalue >9){ //进位
pre = new Node();
pre->data =cvalue%10;
ans->next = pre;
ans->data = 1;
p=pre;
}else if(9 == cvalue){//最高位为9
flag = true;
ans->data =cvalue;
pre= ans;
p=pre;
}else{
ans->data =cvalue;
p = pre= ans;
}
q1=q1->next;q2=q2->next;
while(q1 && q2){// the following node
q = new Node();
pre->next = q;
cvalue = q1->data+ q2->data;
q->data =cvalue%10;
if(cvalue > 9 ){
if(flag){
if(p != ans){
p->data += 1;
}else{//999...[],前面全是9
Node*temp = new Node();
temp->data= 1;
temp->next= ans;
flag =false;
ans =temp;
p = ans;
}
}else{
p->data +=1;
}
for(p=p->next;p!=q;p=p->next){
p->data =0;
}
}else if(cvalue <9){
p = q;
}
pre = q;
q1=q1->next;q2=q2->next;
}
return ans;
}参考:http://hawstein.com/posts/add-singly-linked-list.html,第二种实现不错
b、 元素个数不一定相同,高位在后,个位在链表头结点。1->2->3 , 4->5->3->4,得5->7->6->4.
思路:需要注意的是,链表为空,有进位,链表长度不一样。
#include <assert.h>
#include <iostream>
using namespace std;
struct Node{
int data;
Node *next;
};
Node* create_list(int arr[],int len){
assert(arr &&len>0);
Node *head = new Node();
head->data = arr[0];
Node *cur=NULL;
Node *pre=head;
for(int i=1;i<len;++i){
cur = new Node();
cur->data =arr[i];
pre->next = cur;
pre = cur;
}
cur->next = NULL;
return head;
}
Node* merge_list_add(Node *list1,Node *list2){
if(NULL == list1) returnlist2;
if(NULL == list2) returnlist1;
Node *ans=NULL,*pre=NULL;
int c=0;//进位
int value = 0;
while(list1 &&list2){
value =list1->data +list2->data + c;
Node* temp = newNode();
temp->data =value%10;
c = value/10;
if(pre){
pre->next =temp;
pre = temp;
}else
ans=pre=temp;
list2 = list2->next;
list1 =list1->next;
}
if(!list1 &&!list2 && c>0){//两个链表长度一样,但有进位
Node* temp = newNode();
temp->data = 1;
temp->next =NULL;//结束
pre->next = temp;
}
//有一个链表更长
while(list1){
value =list1->data + c;
Node* temp = newNode();
temp->data =value%10;
c = value/10;
pre->next = temp;
pre = temp;
list1 =list1->next;
}
while(list2){
value =list2->data + c;
Node* temp = newNode();
temp->data =value%10;
c = value/10;
pre->next = temp;
pre = temp;
list2 =list2->next;
}
pre->next = NULL;
return ans;
}
int main(){
int a[]={1,2,7};
int b[]={4,5,3,9,3};
//此处应该加个判断,保证数组元素均在[0,9]
Node* lista =create_list(a,3);
Node* listb =create_list(b,5);
Node* cur = lista;
cout<<"list a:";
while(cur != NULL){
cout<<cur->data<<"";
cur = cur->next;
}
cur = listb;
cout<<endl<<"listb: ";
while(cur != NULL){
cout<<cur->data<<"";
cur = cur->next;
}
cout<<endl;
Node *ans =merge_list_add(lista, listb);
for(; ans; ans=ans->next)
cout<<ans->data<<" ";
cout<<endl;
}
13、用算法实现删除链表的一个中间节点,所知的只有该节点的指针。如a-b-c-d-e中只知道c的指针,实现a-b-d-e。
思路:若直接删除的话,链表就断了,可是无法得到节点c的前驱b。故可转换思路利用c的后继d。将d的值赋给c, 然后将后继节点d删除,也就实现删除操作。
由于c的位置不定,得分情况讨论。一、c为普通的中间节点,用上述方式解决。二,c为头节点,用上述方式解决。三、c为尾节点,一般认为删除即可,但是会出现问题。删除之后,尾节点的前驱不为空,下次遍历就会出错,特别注意。四、c为空节点,直接返回。
实现:
bool remove_elem(Node* node){
if(!node || !node->next) returnfalse;
Node *post = node->next;
node->data = post->data;
node->next = post->next;
delete post;
return true;
}扩展:
a、Google题目,给定单向链表的头指针和一个结点指针,定义一个函数在O(1)时间删除该结点。
思路跟前面的一致,同样要注意尾节点。
b、只给定单链表中某个结点p(非空结点),在p前面插入一个结点。
思路:首先分配一个结点q,将q插入在p后,接下来将p中的数据copy入q中,
然后再将要插入的数据记录在p中。
14、环链表开始节点,1->2->5->4->2
思路:
1、 用快慢指针,满指针1,快指针2。
我们注意到第一次相遇时,指针走过的路程S1 = 非环部分长度 + 弧A长
快指针走过的路程S2 = 非环部分长度 + n * 环长 + 弧A长
S1 * 2 = S2,可得 非环部分长度 = n * 环长 – 弧A长
让指针1到起始点后,走过一个非环部分长度,指针2过了相等的长度。
就是n * 环长 – 弧A长,正好回到环的开头。
或者参考:http://blog.csdn.net/lalor/article/details/7628332
2、 更简单直观的方法就是利用哈希表。无环的话,每个地址就是不一样;有环的话,两个地址一样的就是环开始节点。下面用c++的map实现
std::map<Node*, bool>hash;
Node* loop_start(Node* node){
while(node){
if(hash(node))
return node;
else{
hash(node) = true;
node = node->next;
}
}
return NULL; //return head ; same
}
15、如何知道环的长度
一、在环上相遇后,记录第一次相遇点为pos,之后指针slow继续每次走1步,fast每次走2步。在下次相遇的时候fast比slow正好又多走了一圈,也就是多走的距离等于环长。
设从第一次相遇到第二次相遇,设slow走了len步,则fast走了2*len步,相遇时多走了一圈:环长=2*len-len。
二、利用哈希表,即两个碰撞元素间的个数
16、输入一个链表的头结点,从尾到头反过来打印出每个结点的值。
思路:用栈实现。
进阶:用递归。实现如下:
void PrintListReversingly(ListNode*pHead){
if(pHead != NULL){
if(pHead->m_pNext != NULL){
PrintListReversingly(pHead->m_pNext);
}
printf("%d\t",pHead->m_nValue);
}
}注意:但使用递归就意味着可能发生栈溢出的风险,尤其是链表非常长的时候。所以,基于循环实现的栈的鲁棒性要好一些。
17、输入两个递增链表,合并为一个递增链表。
思路:遍历两个链表,依次比较,形成新的队列
进阶:递归,每次递归返回合并后新链表的头结点
list_node*List::recursive_merge(list_node * a,list_node * b){
if(a == NULL)return b;
if(b == NULL)return a;
if(a->value <= b->value){
a->next=recursive_merge(a->next,b);
return a;
}
if(a->value > b->value){
b->next=recursive_merge(a,b->next);
return b;
}
}
18、用链表实现约瑟夫环
这里就不实现了。
19、判断一条单向链表是不是“回文”,1-2-4-2-1
思路:对于单链表结构,可以用两个指针从两端或者中间遍历并判断对应字符是否相等。但这里的关键就是如何朝两个方向遍历。
由于单链表是单向的,所以要向两 个方向遍历的话,可以采取经典的快慢指针的方法,即定位到链表的中间位置,再将链表的后半逆置,最后用两个指针同时从链表头部和中间开始同时遍历并比较即可。
实现:(注意链表元素的奇偶性,稍微不同)
bool is_list_plalindrome(Node*head){
if(!head)
return false;
Node *one=head,*two=head,*pre=NULL;
while(two!=NULL && two->next!=NULL){
pre=one;
one = one->next;
two = two->next->next;
}
//if length of list is odd, mid
Node *subhead=NULL,*node=NULL,*post=NULL;
if(!two){ //even,two==NULL
subhead = one;
}else{ //odd
subhead=one->next;
}
node=subhead;
post=node->next;
while(node->next){// rotate sublist (旋转的这种写法,很容易理解)
node->next = post->next;
post->next = subhead;
subhead = post;
post = node->next;
}
for(Node*p=head,*q=subhead;p!=pre->next;p=p->next,q=q->next){
if(p->data!=q->data)
return false;
}
return true;
}
20、从尾到头输出链表。
题目:输入一个链表的头结点,从尾到头反过来输出每个结点的值。
思路:跟输出倒数第n个元素的方法类似。
方法一、先把链表反向,然后再从头到尾遍历一遍。但该方法需要额外的操作
方法二、设一个栈,从头到尾遍历一次,把结点值压力栈中,再出栈打印。
方法三、递归。
实现:
void list_out_reverse(Node*head){
if(!head)
return;
else
list_out_reverse(head->next);
cout<<head->data<<" ";
}扩展:该题还有两个常见的变体:
1. 从尾到头输出一个字符串;
2. 定义一个函数求字符串的长度,要求该函数体内不能声明任何变量。
两个的分别实现:
void reverseString(conststring& s,unsigned int begin){
if(!s.size())
return;
if(begin>=s.size())
return;
reverseString(s,begin+1);
cout<<s[begin]<<" ";
}
int getLength(const char *s){
if(*s=='/0')
return 0;
return getLength(s+1) + 1;
}
21、链表和数组的区别?
分析:主要在基本概念上的理解。但是最好能考虑的全面一点,现在公司招人的竞争可能就在细节上产生,谁比较仔细,谁获胜的机会就大。
数组无需初始化,因为数组的元素在内存的栈区,系统自动申请空间。而链表的结点元素在内存的堆区,每个元素须手动申请空间,如malloc。也就是说数组是静态分配内存,而链表是动态分配内存。链表如此麻烦为何还要用链表呢?数组不能完全代替链表吗?回到这个问题只需想想我们当初是怎么完成学生信息管理系统的。为何那时候要用链表?因为学生管理系统中的插入,删除等操作都很灵活,而数组则大小固定,也无法灵活高效的插入,删除。
数组是线性结构,静态分配内存,在内存中连续,数组元素在栈区。可以直接索引,时间复杂度O(1)。数组插入或删除元素比较困难,时间复杂度O(n)。
链表也是线性结构,动态分配内存,在内存中不连续,链表元素在堆区。元素的定位均需遍历,时间复杂度O(n)。链表插入或删除元素操作灵活性强,时间复杂度O(1)。
22、编写实现链表排序的一种算法。说明为什么你会选择用这样的方法?
思路:如果只是数据内容之间的相互交换,那么这种排序方法也比较适合链表的排序,插入、冒泡、希尔和选择排序。快速排序、合并排序、堆排序都涉及到了中间值的选取问题,所以不大适合链表排序。
选择排序的实现:
Node* insert_sort(Node *head){
if(!head ||!head->next)
return head;
Node *p,*q,*pre,*temp;
p=head->next;
head->next=NULL;
// p is the head of unsorted list
// head is the head of sorted list
while(p){
q=head;
while(q &&(q->data < p->data)){
pre=q;
q=q->next;
}
temp = p->next;
if(q==head){
p->next = q;
head = p;
}else{
pre->next=p;
p->next = q;
}
p=temp;
}
return head;
}
其他排序参考:http://blog.csdn.net/hackbuteer1/article/details/6666475
http://wenku.baidu.com/link?url=CxhR7E5PGrEwRU5eKu_3xX5EvZ6MP-7GhRLhAfoQFThh5HxlQ5SgIxdfRPVXRO-oeCkwFYFqLJJezeswxdOmRE4W_QJBY3iS4Xpot23XCPi
23、复杂链表的复制(默认无环)
Q:有一个复杂链表,其结点除了有一个m_pNext指针指向下一个结点外,还有一个m_pSibling指向链表中的任一结点或者NULL。请完成函数ComplexNode* Clone(ComplexNode* pHead),以复制一个复杂链表。
一开始想这道题毫无思路,如果蛮来,首先创建好正常的链表,然后考虑sibling这个分量,则需要O(n^2)的时间复杂度。
思路一: 一般复制一个简单链表就这么遍历一遍就好了,这个复杂链表,比简单链表多的地方就在于多了一个sibling的指针,也就是说在建立完简单链表之后,如何在新的链表中找到sibling对应的地址。我们已知的是旧的节点的地址,所以只需要用一个map,保存每一个节点旧的节点对应的新的节点的地址即可。(即将原链表中的结点N和相应复制结点N’建立哈希映射<N,N’>)
第一次遍历,建立简单节点,第二次遍历,对于旧链表中的每一个节点的sibling指针地址,从map中找到新链表中对应节点的地址,连接上就好了。
实现:(不错的实现,学习)
ComplexNode* Clone(ComplexNode*pHead){
if(pHead == NULL) return NULL;
map<ComplexNode*, ComplexNode*>pointMap;
ComplexNode* newHead,*tail; // newHead指向复制的新链表的开头,tail始终指向结尾
// 开辟一个头结点
newHead = new ComplexNode;
newHead->value = pHead->value;
newHead->pNext = NULL;
newHead->pSibling = NULL;
pointMap[pHead] = newHead; // 将头结点放入map中
tail = newHead;
ComplexNode *p = pHead->pNext;
while(p != NULL){ // 第一遍先将简单链表复制一下
ComplexNode* newNode = new ComplexNode;
newNode->value = p->value;
newNode->pNext = NULL;
newNode->pSibling = NULL;
tail->pNext = newNode;
tail = newNode;
pointMap[p] = newNode;
p = p->pNext;
}
// 根据map中保存的数据,找到对应的节点
p = pHead;
tail = newHead;
while(p!=NULL){
if(p->pSibling!=NULL){
tail->pSibling =pointMap.find(p->pSibling)->second;//Key,找N对应的N’
}
p = p->pNext;
tail = tail->pNext;
}
return newHead;
}
思路二:(精妙)一个技巧便可以巧妙的解答此题。看图便知。
首先是原始的链表
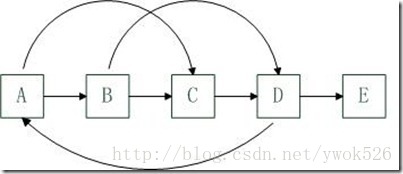
然后我们还是首先复制每一个结点N为N*,不同的是我们将N*让在对应的N后面,即为
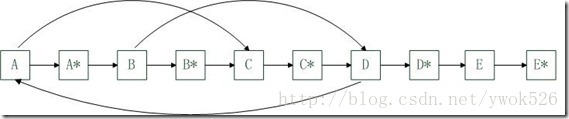
然后我们要确定每一个N*的sibling分量,非常明显,N的sibling分量的next就是N*的sibling分量。
最后,将整个链表拆分成原始链表和拷贝出的链表。
这样,我们就解决了一个看似非常混乱和复杂的问题。
实现:
struct Node{
int val;
Node* next;
Node*sibling;
};
void Clone(Node* head){
Node*current=head;
while(current){
Node*temp=new Node;
temp->val=current->val;
temp->next=current->next;
temp->sibling=NULL;
current->next=temp;
current=temp->next;
}
}
void ConstructSibling(Node*head){
Node*origin=head;
Node*clone;
while(origin){
clone=origin->next;
if(origin->sibling)
clone->sibling=origin->sibling->next;
origin=clone->next;
}
}
Node* Split(Node* head){
Node*CloneHead,*clone,*origin;
origin=head;
if(origin){
CloneHead=origin->next;
origin->next=CloneHead->next;
origin=CloneHead->next;
clone=CloneHead;
}
while(origin){
Node*temp=origin->next;
origin->next=temp->next;
origin=origin->next;
clone->next=temp;
clone=temp;
}
return CloneHead;
}
//the whole thing
Clone(head);
ConstructSibling(head);
Split(head);