Perf 是用来进行软件性能分析的工具,可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计,用来分析内核和应用程序的性能。
perf可以完成如下的性能分析
- 计算每个时钟周期内的指令数 进行函数级别的采样
- 了解性能瓶颈 替代strace
- 添加动态内核 probe 点
- 做 benchmark 衡量调度器的好坏
perf性能分析需要了解如下背景知识
- cache 流水线
- 超标量体系结构
- 乱序执行
- 分支预测
- PMU计数
- tracepoint
perf的基本使用方法
以下面的实例,说明perf的基本用法
//t1.c
void longa()
{
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
longa();
}
void foo1()
{
int i;
for(i = 0; i< 100; i++)
longa();
}
int main(void)
{
foo1();
foo2();
}
/*t2.c*/
int main(void)
{
while (1);
}
perf list
列出所有能够触发 perf 采样点的事件,主要区分为如下三类事件:
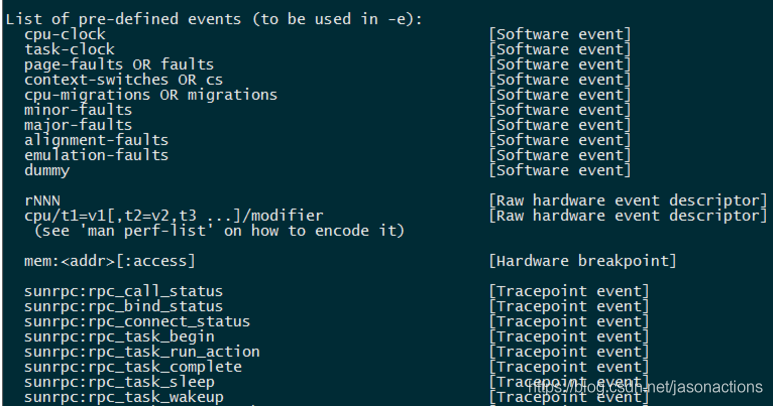
Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中
Software Event 是内核软件产生的事件,比如进程切换,tick 数等
Tracepoint event 是内核中的静态 tracepoint 所触发的事件
perf stat
通过概括精简的方式提供被调试程序运行的整体情况和汇总数据
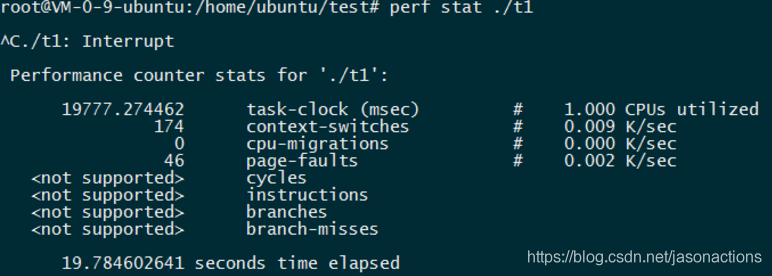
Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
Cache-misses:程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好
CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
Cycles:处理器时钟,一条机器指令可能需要多个 cycles,
Instructions: 机器指令数目。
IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。
Cache-references: cache 命中的次数
Cache-misses: cache 失效的次数。
注:通过指定 -e 选项,您可以改变 perf stat 的缺省事件
perf top
用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程
root@VM-0-9-ubuntu:/home/ubuntu/test# perf top

可以看到主要的性能耗费在t2进程的main函数
perf record/perf report
perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果
root@VM-0-9-ubuntu:/home/ubuntu/test# perf record -e cpu-clock ./t1
root@VM-0-9-ubuntu:/home/ubuntu/test# perf report

可以查看到热点为main函数
使用-g选项可以查看到具体某个函数所花费的时间以及函数的调用路径:
root@VM-0-9-ubuntu:/home/ubuntu/test# perf record -e cpu-clock -g ./t1
root@VM-0-9-ubuntu:/home/ubuntu/test# perf report -g
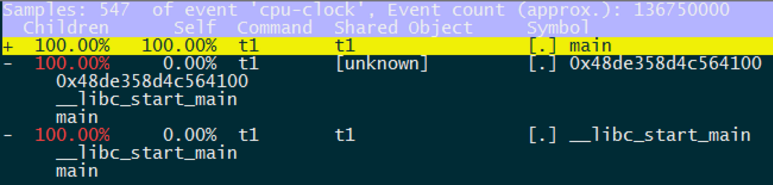
注:这里很奇怪我的环境执行perf没有详细列出函数调用栈的执行时间
perf -e
如果想关心perf的具体某个事件,希望按某个事件来进行统计则可以通过-e来指定某个事件
使用 tracepoint 的基本需求是对内核的运行时行为的关心
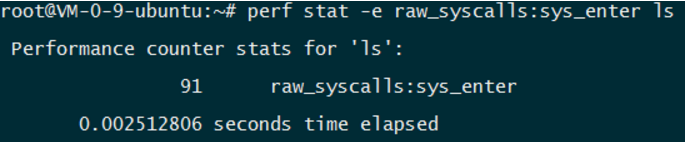
perf stat -e raw_syscalls:sys_enter ls
列出系统调用的次数
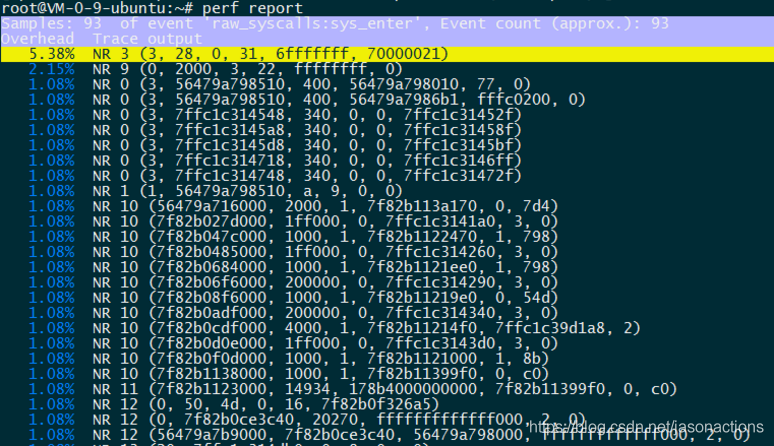
root@VM-0-9-ubuntu:~# perf record -e raw_syscalls:sys_enter ls
root@VM-0-9-ubuntu:~# perf report
查看系统调用主要发生在哪里
perf probe
能够动态地在想查看的地方插入动态监测点
root@VM-0-9-ubuntu:~#perf probe schedule:12 cpu
上例利用 probe 命令在内核函数 schedule() 的第 12 行处加入了一个动态 probe 点,和 tracepoint 的功能一样,内核一旦运行到该 probe 点时,便会通知 perf。可以理解为动态增加了一个新的 tracepoint
perf sched
perf sched提供了许多工具来分析内核CPU调度器的行为。你可以用它来识别和量化调度器延迟的问题。
root@VM-0-9-ubuntu:/home/ubuntu/test# perf sched record sleep 10
root@VM-0-9-ubuntu:/home/ubuntu/test# perf sched latency --sort max
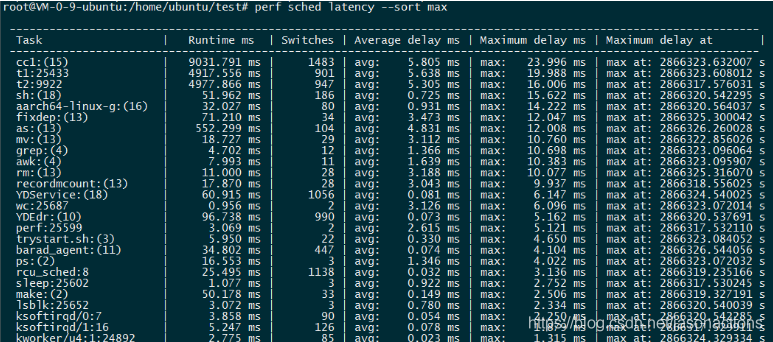
Task: 进程的名字和 pid
Runtime: 实际运行时间
Switches: 进程切换的次数
Average delay: 平均的调度延迟
Maximum delay: 最大延迟
这里最值得人们关注的是 Maximum delay,一般从这里可以看到对交互性影响最大的特性:调度延迟,如果调度延迟比较大,那么用户就会感受到视频或者音频断断续续的。
perf sched map
root@VM-0-9-ubuntu:/home/ubuntu/test#perf sched record sleep 10
root@VM-0-9-ubuntu:/home/ubuntu/test# perf sched map
显示了所有的CPU和上下文切换事件

每个CPU一列,星号表示调度事件正在发生的CPU
Map 的好处在于提供了一个的总的视图,将成百上千的调度事件进行总结,显示了系统任务在 CPU 之间的分布,假如有不好的调度迁移,比如一个任务没有被及时迁移到 idle 的 CPU 却被迁移到其他忙碌的 CPU,类似这种调度器的问题可以从 map 的报告中一眼看出来。
perf sched script
显示调度相关的事件
root@VM-0-9-ubuntu:/home/ubuntu/test#perf sched record sleep 10
root@VM-0-9-ubuntu:/home/ubuntu/test# perf sched script

可以查看schedule的trace
perf sched replay
这个工具更是专门为调度器开发人员所设计,它试图重放 perf.data 文件中所记录的调度场景
perf sched replay采集记录的调度器事件,通过生成具有类似运行时间和上下文切换的线程来模拟工作负载。
root@VM-0-9-ubuntu:/home/ubuntu/test# perf sched replay -r 1
perf lock
锁是内核同步的方法,一旦加了锁,其他准备加锁的内核执行路径就必须等待,降低了并行。因此对于锁进行专门分析应该是调优的一项重要工作
perf lock record dd if=/dev/testb_a of=/dev/null
perf lock report
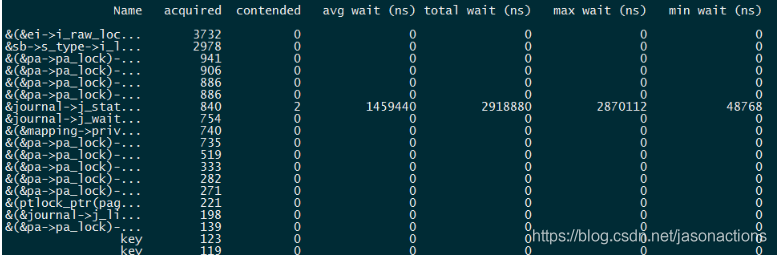
“Name”: 锁的名字,比如 md->map_lock,即定义在 dm.c 结构 mapped_device 中的读写锁。
“acquired”: 该锁被直接获得的次数,即没有其他内核路径拥有该锁的情况下得到该锁的次数。
“contended”冲突的次数,即在准备获得该锁的时候已经被其他人所拥有的情况的出现次数。
“total wait”:为了获得该锁,总共的等待时间。
“max wait”:为了获得该锁,最大的等待时间。
“min wait”:为了获得该锁,最小的等待时间。
perf kmem
Perf Kmem 专门收集内核 slab 分配器的相关事件。比如内存分配,释放等。可以用来研究程序在哪里分配了大量内存,或者在什么地方产生碎片之类的和内存管理相关的问题。

该报告有三个部分:
1.根据 Callsite 显示的部分
Callsite: 即内核代码中调用 kmalloc 和 kfree 的地方。比如上图中的函数 __sigqueue_alloc
Hit:表示调用kmalloc的次数,为 1表示该函数在 record 期间一共调用了 kmalloc 一次
Total_alloc/Per :显示为 160/160,第一个值 160表示函数 __sigqueue_alloc总共分配的内存大小,Per 表示平均值。
Frag :内部碎片的比例。虽然相对于 Buddy System,Slab 正是要解决内部碎片问题,但 slab 依然存在内部碎片,比如一个 cache 的大小为 1024,但需要分配的数据结构大小为 1022,那么有 2 个字节成为碎片。Frag 即碎片的比例。
Ping-pong :是一种现象,在多 CPU 系统中,多个 CPU 共享的内存会出现”乒乓现象”。一个 CPU 分配内存,其他 CPU 可能访问该内存对象,也可能最终由另外一个 CPU 释放该内存对象。而在多 CPU 系统中,L1 cache 是 per CPU 的,CPU2 修改了内存,那么其他的 CPU 的 cache 都必须更新,这对于性能是一个损失。Perf kmem 在 kfree 事件中判断 CPU 号,如果和 kmalloc 时的不同,则视为一次 ping-pong,理想的情况下 ping-pone 越小越好。Ibm developerworks 上有一篇讲述 oprofile 的文章,其中关于 cache 的调优可以作为很好的参考资料。
2.根据被调用地点显示部分
3.汇总数据
显示总的分配的内存和碎片情况,Cross CPU allocation 即 ping-pong 的汇总
注:Perf kmem 和 perf lock 实际上都是 perf tracepoint 的特例,您也完全可以用 Perf record > – e kmem:* 或者 perf record – e lock:*> 来完成同样的功能。但重要的是,这些工具在内部对原始数据进行了汇总和分析,因而能够产生信息更加明确更加有用的统计报表。
perf timechart
perf timechart 的灵感来源于 bootchart。采用“简单”的图形“一目了然”地揭示问题所在。
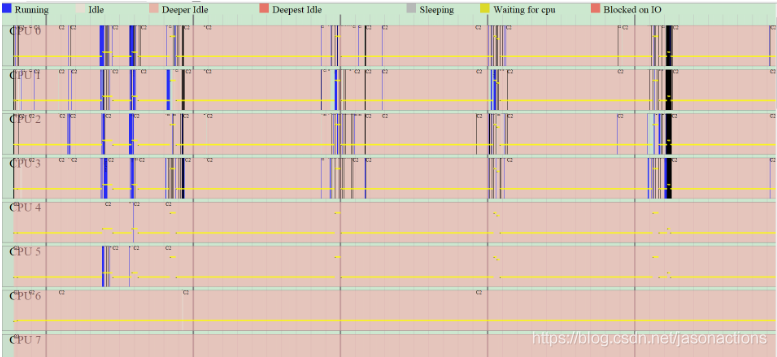
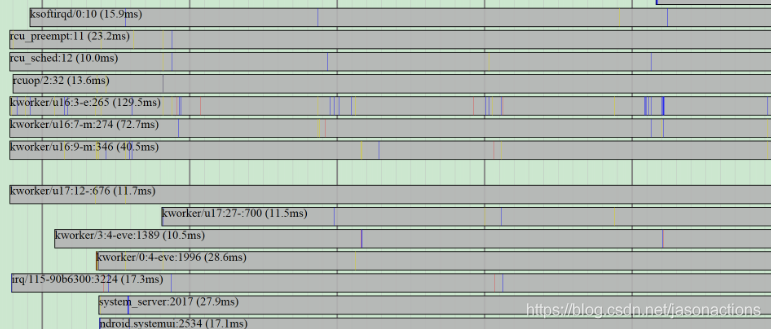
上图的最上面一行是图例,蓝色表示忙碌,红色表示 idle,灰色表示等待,等等。接下来是 per-cpu 信息,再下面是 per-process 信息.Timechart 可以显示更详细的信息,上图实际上是一个矢量图形 SVG 格式,用 SVG viewer 的放大功能,我们可以将该图的细节部分放大,timechart 的设计理念叫做”infinitely zoomable”。放大之后便可以看到一些更详细的信息,类似网上的 google 地图,找到国家之后,可以放大,看城市的分布,再放大,可以看到某个城市的街道分布,还可以放大以便得到更加详细的信息。
perf script
Tom Zanussi 将 perl 和 python 解析器嵌入到 perf 程序中,从而使得 perf 能够自动执行 perl 或者 python 脚本进一步进行处理,从而为 perf 提供了强大的扩展能力。因为任何人都可以编写新的脚本,对 perf 的原始输出数据进行所需要的进一步处理。这个特性所带来的好处很类似于 plug-in 之于 eclipse