布隆过滤器
定义
它实际上是一个很长的二进制数组+一系列随机hash算法映射函数,主要用于快速的判断一个元素是否在集合中.
他的判断结果并不是百分之百准确的
特性
- 高效的插入和查询,占用空间少,返回的结果是不确定性的
- 一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在
- 布隆过滤器可以添加元素,但是不能删除元素.因为删除元素会导致误判率增加
- 误判只会发生在过滤器没有添加过的元素,对于已经添加过的元素不会发生误判.
因为可能发生hash冲突
使用场景
解决缓存穿透的问题
把已经存在数据的key存放到布隆过滤器中,相当于在redis前面再加一层拦截过滤.
当有新的请求时,先到布隆过滤器中查询是否存在,如果布隆过滤器不存在该条数据则直接返回,如果布隆过滤器中已存在,才去查询redis缓存,如果redis没有再去查询mysql
黑白名单校验
直接判断值在不在布隆过滤器里面
底层原理
哈希冲突案例
public static void main(String[] args) {
System.out.println("Aa".hashCode());
System.out.println("BB".hashCode());
}
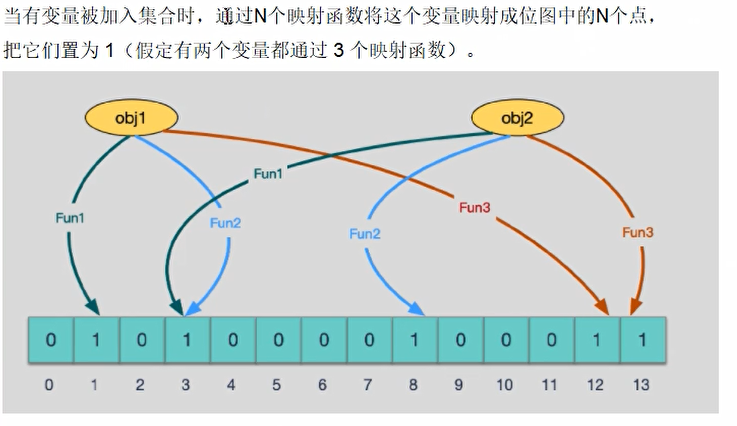
添加key
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置为1就完成了add操作
添加key的图示

查询key
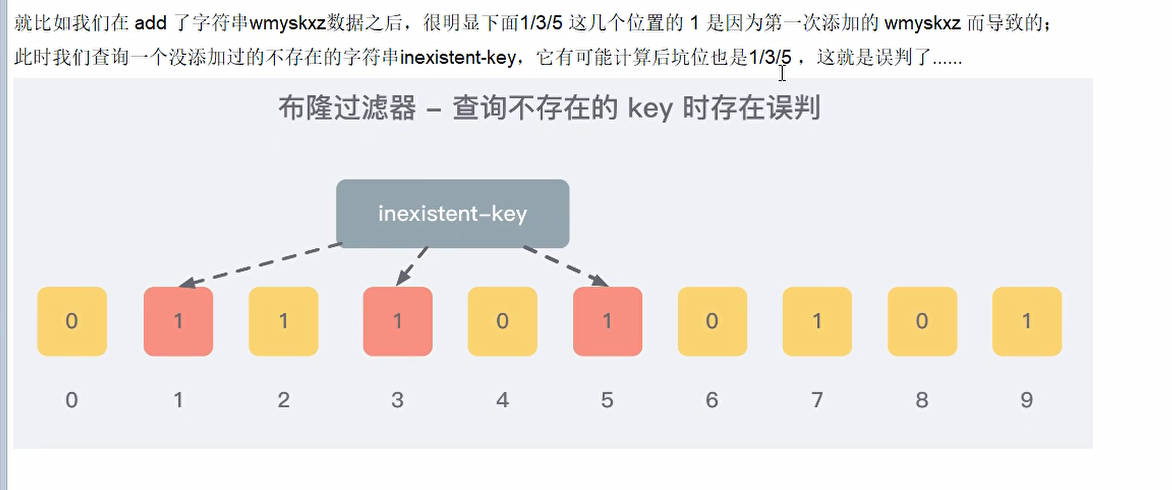
只要有其中一位是0就表示这个key不存在,如果都是1(都是布隆过滤器就返回存在),但是不一定就代表存在这对应的key.
因为只要是hash函数就存在hash冲突,哪怕是采用了多个hash函数也有可能会跟其他的多个key值hash出来的值冲突,所以不能确定一定存在
查询误判示意图:
总结
- 有是有可能有,无就是一定无
- 使用时最好不要让实际元素数量远大于初始化数量
- 当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个size更大的过滤器,再将所有的历史元素批量add进去
- 优点
- 高效的插入和查询
- 占用空间很少
- 缺点
- 不能删除元素(因为删除元素会导致误判率的增加,因为hash冲突同一个槽位对应多个对象的信息,你删除一个元素很可能把其他的也删除了)
- 存在误判率(hash冲突,不同的数据对象可能会出来相同的hash值)
四个缓存问题
缓存雪崩
定义
redis主机挂了,redis全盘崩溃(或者缓存中有大量数据同时过期)
解决方案
- redis缓存集群实现高可用
- 主从+哨兵
- Redis Cluster
- ehcache本地缓存 + Hystrix或者阿里sentinel限流降级
- 开启redis持久化机制aof/rdb,尽快恢复缓存集群
缓存穿透
定义
一般情况下,先查询缓存redis是否有该条数据,缓存未命中时,在查询数据库.当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透.它带来的问题就是当有大量的请求查询数据库本身就不存在的数据时,就会给数据库带来压力,甚至是直接拖垮数据库
解决方案
- 方案1:空对象缓存或者缺省值
- 方案2:google布隆过滤器guava解决缓存穿透
- 方案3:redis布隆过滤器解决缓存穿透
方案一
就是缓存一个空值或者业务上定义的缺省值在redis里面缓存返回(每次换id就不好用了 而且会导致大量的无用key堆积)
方案二(guava实现)
代码案例
public static final int _1w = 10000;
public static final int size = 100 * _1w;
public static double fpp = 0.03;
/**
* 入门demo
*/
public void bloomFilter() {
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 100);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
}
/**
* 误判率演示和源码分析
*/
public void bloomFilter2() {
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), size);
for (int i = 0; i < size; i++) {
filter.put(i);
}
ArrayList<Object> list = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
if (filter.mightContain(i)) {
list.add(i);
}
}
System.out.println("存在的数量" + list.size());
ArrayList<Object> arrayList = new ArrayList<>(10 * _1w);
for (int i = size + 1; i < size + 100000; i++) {
if (filter.mightContain(i)) {
System.out.println(i + "被误判了");
arrayList.add(i);
}
}
System.out.println("误判的数量" + arrayList.size());
}
public static void main(String[] args) {
new GuavaBBloomFilterDemo().bloomFilter2();
}
源码分析
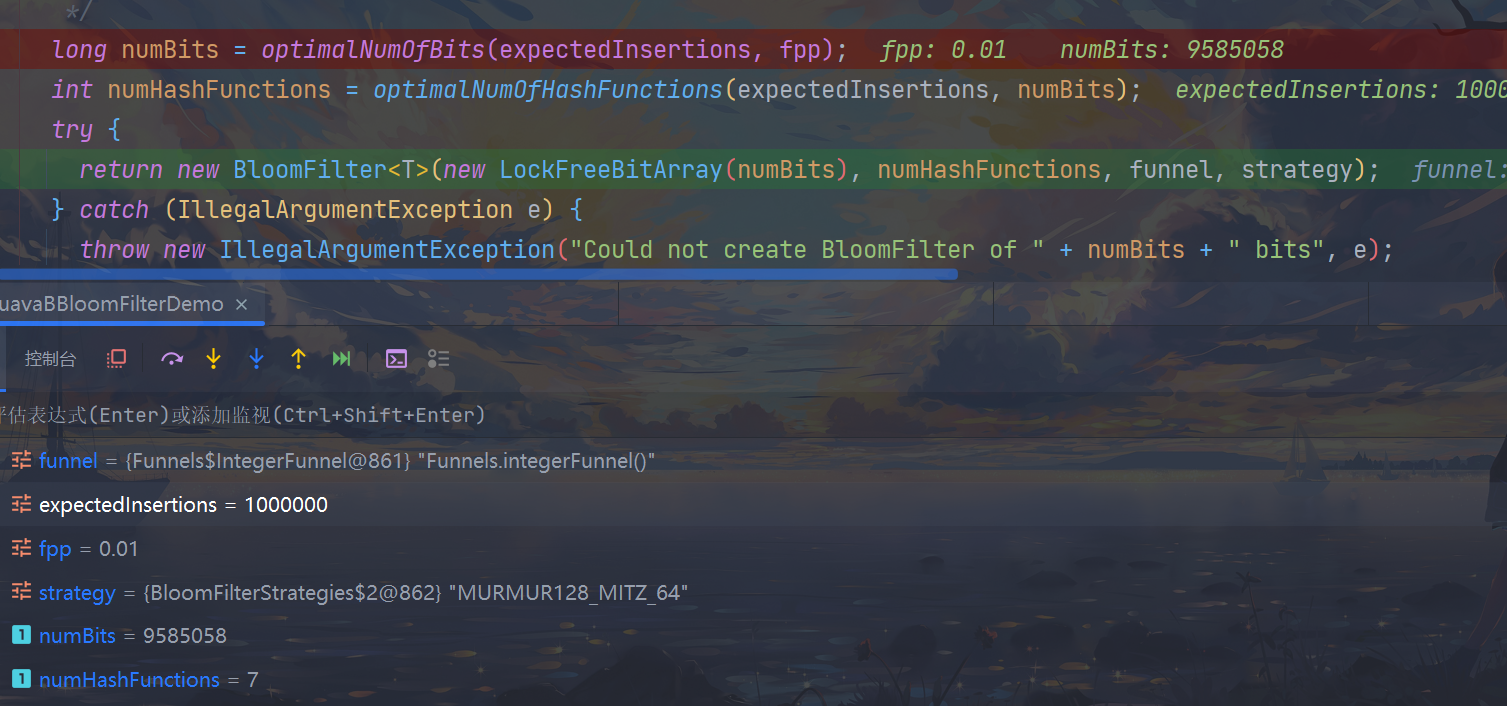
当你的误判率fpp越低,需要占用的bit数组就越长,对值进行hash计算的hash函数就越多,这样的话能更加避免hash冲突的情况发生,用空间和时间来换取准确率,guava默认设置是0.03,个人用的话最低也就建议到0.01,再低的话导致程序变慢就得不偿失了.
方案三(RedisSon实现)
代码实现
public static final int _1w = 10000;
public static final int size = 100 * _1w;
public static double fpp = 0.01;
static RedissonClient redissonClient;
static RBloomFilter rBloomFilter;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://8.131.64.231:16678").setDatabase(0)
.setPassword("liang#0601");
redissonClient = Redisson.create(config);
rBloomFilter = redissonClient.getBloomFilter("phoneList", new StringCodec());
rBloomFilter.tryInit(size, fpp);
rBloomFilter.add("10086");
redissonClient.getBucket("10086", new StringCodec()).set("chinamobile10086");
}
public static String getPhone(String id) {
String result;
if (rBloomFilter.contains(id)) {
RBucket<String> rBucket = redissonClient.getBucket(id, new StringCodec());
result = rBucket.get();
if (result != null) {
return "result form redis:" + result;
} else {
result = getByMysql(id);
if (result == null) {
return null;
}
redissonClient.getBucket(id, new StringCodec()).set(result);
}
return "result form mysql:" + result;
}
return null;
}
public static String getByMysql(String id) {
return "10086mysql";
}
public static void main(String[] args) {
String phone = getPhone("10086");
System.out.println(phone);
redissonClient.shutdown();
}
方案四(直接安装redis插件,应用层解决方案)
编译安装Rebloom插件


docker安装

默认的误判率是0.01 默认的bit数组是100
缓存击穿
定义
热点key突然失效了,导致大量的请求直接打到了MySQL上面
解决方案
- 互斥更新(在第一个线程进来拿数据的时候,如果发现redis里面没有就用互斥锁锁住,更新进入redis之后在放开锁)
- 随机退避
- 双缓存结构解决
- 开启两块缓存,主A从B,先更新B再去更新A,严格按照这个顺序
- 先查询主缓存A,A没有再去查询从缓存B
- 注意更新和查询的顺序要倒过来,这样就能避免有时间差
两个主从缓存差异化失效时间,在你删除缓存的时候就不会缓存击穿
