1.前言
写这个文章主要是因为学习了吴恩达老师的机器学习视频,在神经网络的反向传播算法(Back Propagation)的公式推导有些模糊,所以自己也查阅了很多资料,才基本搞明白其中的原理。所以希望通过写一下文章来进行梳理一下。
因为本文的公式推导是基于吴恩达老师的课程,课程里的神经网络部分主要讲述的是神经网络在分类的应用,因此激活函数采用的是sigmoid函数,下面的公式推导也基于这个进行推导。
最后,因为自己是刚开始学习机器学习,所以可能理解上存在一些小的偏差。如果文章中有错误,欢迎大家指正。
2.前向传播
要理解反向传播,那么就必须先理解前向传播,下图以一个三层神经网络为例。。
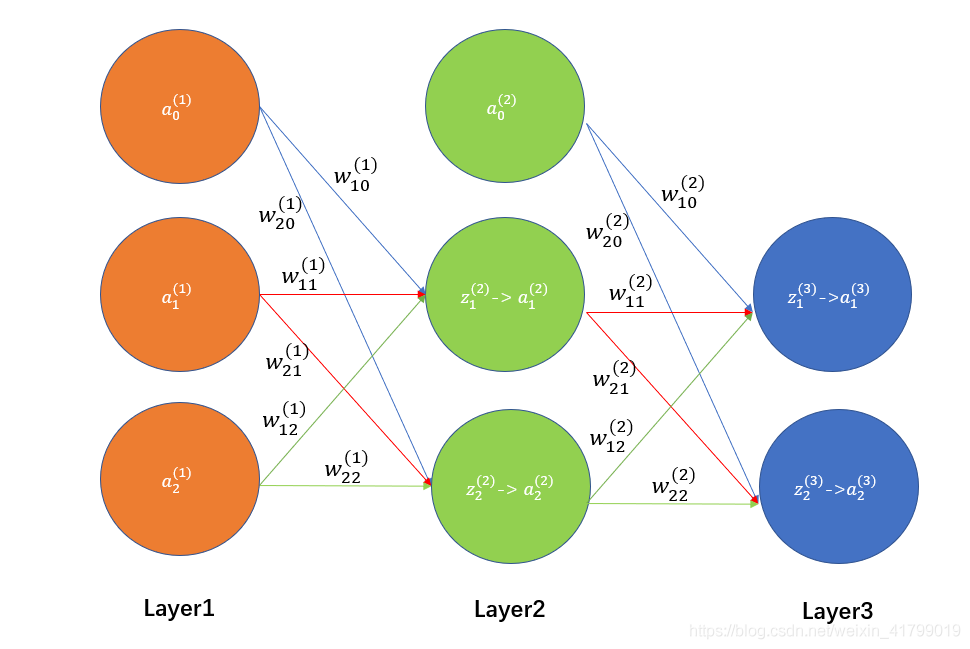
根据上图,我给大家罗列一下正向传播的步骤,前向传播还是比较好理解的。通过输入层(Layer1)将数据输入(注意要加上偏执单元a0(l)=1),然后经过隐藏层(Layer2)加工处理,最后通过输出层(Layer3)进行输出结果。
1、输入层输入训练集
输入层其实就是对应上图中的Layer1。
我们会有训练集**(x,y)**,训练集中会包含许多的 (x(i),y(i))样本,每一个x(i)中又会包含许多的特征 xj(i),如x1(i)、x2(i)等等。
然后我们将x(i)中的xj(i)输入到神经网络中,就成为了输入层中的 aj(0),其中x1(i)=a1(1)、x2(i)=a2(1)。
最后,为了计算方便,我们需要加上 偏置单元a0(1)=1
2、隐藏层计算zj(2)
第二步就是通过权重矩阵计算出zj(2),具体的计算方法如下图所示:
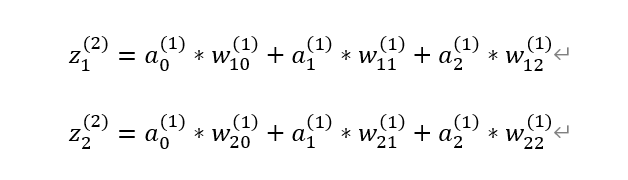
因为权重w和参数θ代表的是一个意思,因此对于上图可以进行向量化表示,具体如下图所示(@代表矩阵的方式相乘):
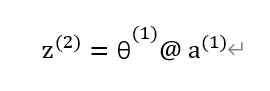
3、通过激活函数计算出aj(2)
通过上一步计算的zj(2),经过激活函数sigmoid,计算出aj(2),具体如下图所示
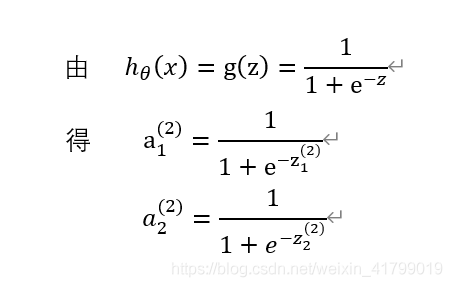
4、计算输出层的aj(3)
原理和上面计算隐藏层的类似,这里就不再重复了,相类比就可以计算出aj(3)。
3.反向传播
还是老规矩,我们先上图,再一步一步进行解释。

反向传播的提出其实是为了解决偏导数计算量大的问题,利用反向传播算法可以快速计算任意一个偏导数。反向传播算法的思想和前向传播是一样的,只是一个反向的过程,推导过程中注意链式法则,一层扣一环即可求得结果。
大家在看下面的推导的时候,一定记得高数中的链式法则,逐步推导就可以了,其实是一个很简单的过程。
1、定义损失函数
首先,我们先定义这个神经网络的损失函数,如下图所示
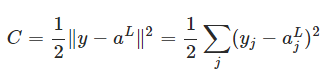
2、定义误差δ
吴恩达老师在视频中将δ翻译为误差,其实这是一种广义上的误差。因为除了输出层之外,我们是无法直接得到每一层的误差的。
广义上定义这个误差是这样的,如下图所示:
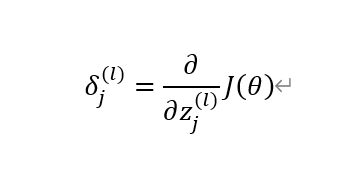
因为偏导数其实就是表明了自变量对因变量产生了多大的影响。因此对于上面这个图中关于δ的定义,我们也就可以理解为zj(l)这个数对最终输出层的计算的误差J(θ)产生了多大的影响,也就是这个数对于这个误差做出了多大贡献。最理想的状态是δ=0,也就是偏导数等于0,没有对误差最终的误差产生影响。然后我们就将把这个“贡献”称为误差。
后面的公式计算每一层的δj(l)其实都是基于这个定义进行推导的。至于为什么在输出层没有使用这个定义去求误差,而是直接使用δj(L)=aj(L)-y得到输出层的误差,大家可以看完全文后回头去看一下这篇文章:反向传播输出层误差 δ。这篇文章清晰地进行了证明,这是因为逻辑回归的损失函数凑巧的一个性质造成的,如果是其他的损失函数则需要按照定义去
3、第L层δ(输出层)的具体推导
首先,我们先定义误差δ的一般形式,如下图所示:
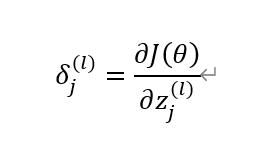
对于输出层的误差推导如下图所示:
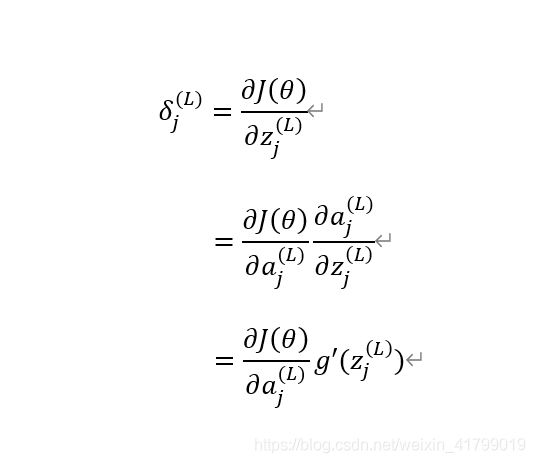
4、第l层误差δ的具体推导
下面我们对上一步进行推广,得到普遍的l层的误差误差δ

对上图结果向量化可得:
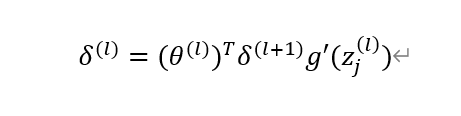
上面的推导看似很复杂,其实就是遵循一个链式法则,我已经基本没有省略步骤了,应该是很详细了。推导的时候需要记得前向传播中a(l)是如何通过权重矩阵编程z(l+1)的,然后z(l+1)通过激活函数又会变成a(l+1),只要遵循这个就可以一步一步推导得出结果。
5、计算得出θij(l)的偏导数
反向传播算法的最终目的就是为了方便计算偏导数,到这一步就可以计算偏导数了。下面先重新放上吴恩达老师的视频截图,如下图所示

从上图中我们可以看到,吴恩达老师还把g’(a)展开成了g(a)*(1-g(a))的形式,这个其实是因为sigmoid函数的性质造成的,具体推导如下:

关于偏导数的推导如下图所示:
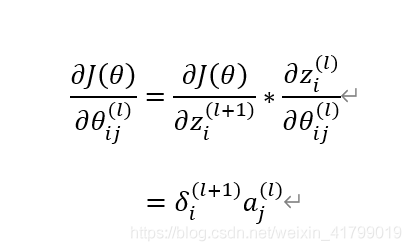
通过上面的推导,就可以完全解释吴恩达老师所有公式的原理了。