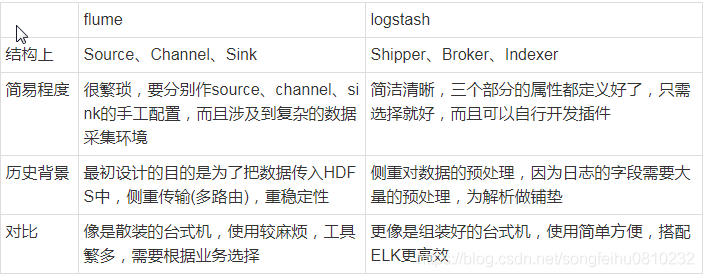
Logstash概念
Logstash是一款开源的数据收集引擎,具备实时管道处理能力。简单来说,logstash作为数据源与数据存储分析工具之间的桥梁,结合ElasticSearch以及Kibana,能够极大方便数据的处理与分析。通过200多个插件,logstash可以接受几乎各种各样的数据。包括日志、网络请求、关系型数据库、传感器或物联网等等。
Logstash工作过程
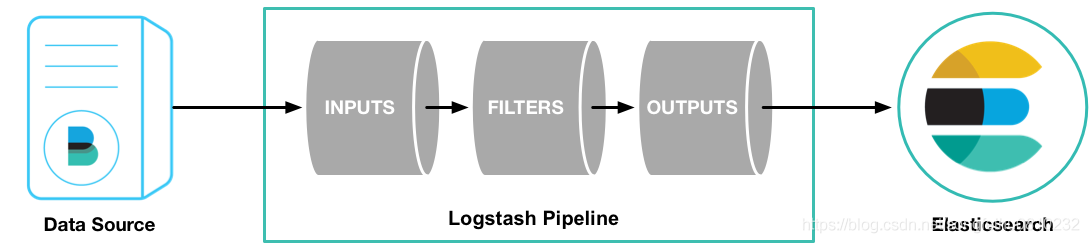
如上图,Logstash的数据处理过程主要包括:Inputs,Filters,Outputs 三部分,另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output,codec插件,以实现特定的数据采集,数据处理,数据输出等功能 。
- Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等
- Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等
- Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等
- Codecs:Codecs(编码插件)不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline。Logstash不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。
Logstash简单实践
我们使用Logstash输出一个 “hello world” 。在终端中,像下面这样运行命令来启动 Logstash 进程:
# bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
以上命令表示从控制台输入,然后通过Codec插件从控制台输出。然后终端在等待你的输入。敲入 Hello World,回车,查看结果:
{
"@version" => "1",
"host" => "sdn-253",
"message" => "Hello World",
"@timestamp" => 2019-07-01T12:28:07.207Z
}
Logstash 就像管道符一样!你输入(就像命令行的 cat )数据,然后处理过滤(就像 awk 或者 uniq之类)数据,最后输出(就像 tee )到其他地方。数据在线程之间以 事件 的形式流传。Logstash会给事件添加一些额外信息。最重要的就是 @timestamp,用来标记事件的发生时间。 大多数时候,还可以见到另外几个:
- host 标记事件发生在哪里。
- type 标记事件的唯一类型。
- tags 标记事件的某方面属性。这是一个数组,一个事件可以有多个标签。
你可以随意给事件添加字段或者从事件里删除字段。
小贴士:每个 logstash 过滤插件,都会有四个方法叫 add_tag, remove_tag, add_field 和remove_field。它们在插件过滤匹配成功时生效。
Logstash配置语法
数据类型
Logstash 支持少量的数据值类型:
bool
debug => true
string
host => "hostname"
number
port => 514
array
match => ["datetime", "UNIX", "ISO8601"]
hash
options => {
key1 => "value1",
key2 => "value2"
}
条件判断
表达式支持下面这些操作符:
相等: ==, !=, <, >, <=, >=
正则: =~(匹配正则), !~(不匹配正则)
包含: in(包含), not in(不包含)
布尔操作: and(与), or(或), nand(非与), xor(非或)
一元运算符:!(取反) ,()(复合表达式), !()(对复合表达式结果取反)
通常来说,你都会在表达式里用到字段引用。比如:
if "_grokparsefailure" not in [tags] {
...
} else if [status] !~ /^2\d\d/ and [url] == "/noc.gif" {
...
} else {
...
}
Logstash插件
logstash插件功能很强大,下面会根据每个模块的情况,对常用插件进行分析。
Input模块
标准输入
我们已经使用 stdin 输入Hello World了。这也应该是 logstash 里最简单和基础的插件了。 input { stdin { } }表示从控制台输入
File插件
从文件读取数据,如常见的日志文件。文件读取通常要解决几个问题:

logstash-input-file配置:
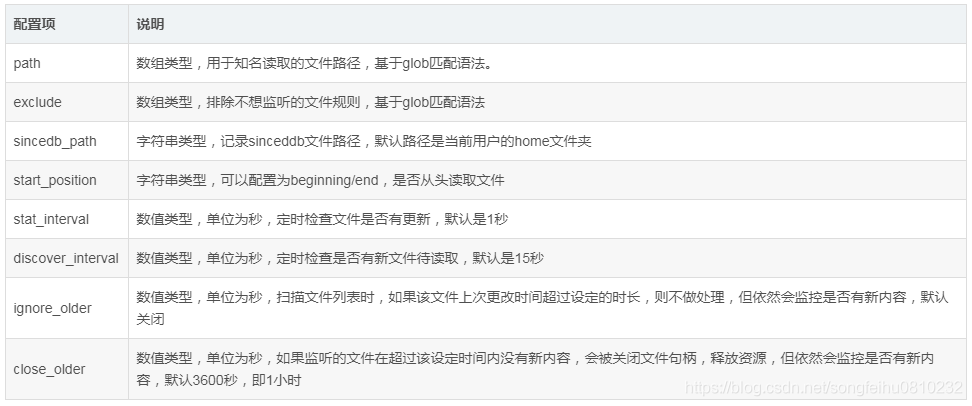
其中path匹配规则如下,路径必须使用绝对路径,不支持相对路径:
/var/log/.log:匹配/var/log目录下以.log结尾的所有文件
/var/log/**/.log:匹配/var/log所有子目录下以.log结尾的文件
/var/log/{app1,app2,app3}/*.log:匹配/var/log目录下app1,app2,app3子目录中以.log结尾的文件
file插件作为input例子如下:
input {
# file为常用文件插件,插件内选项很多,可根据需求自行判断
file {
# 要导入的文件的位置,可以使用*,例如/var/log/nginx/*.log
path => "/var/lib/mysql/slow.log"
# 要排除的文件
exclude =>”*.gz”
# 从文件开始的位置开始读,end表示从结尾开始读
start_position => "beginning"
# 多久之内没修改过的文件不读取,0为无限制,单位为秒
ignore_older => 0
# 记录文件上次读取位置,输出到null表示每次都从文件首行开始解析
sincedb_path => "/dev/null"
# type字段,可表明导入的日志类型
type => "mysql-slow"
}
}
Http插件
input {
http { port => 端口号 }
}
Redis插件
input {
# redis插件为常用插件,插件内选项很多,可根据需求自行判断
redis {
# EVAL命令返回的事件数目,设置为5表示一次请求返回5条日志信息
batch_count => 1
# logstash redis插件工作方式
data_type => "list"
# 监听的键值
key => "logstash-test-list"
# redis地址
host => "127.0.0.1"
# redis端口号
port => 6379
# 如果有安全认证,此项为认证密码
password => "123qwe"
# 如果应用使用了不同的数据库,此为redis数据库的编号,默认为0。
db => 0
# 启用线程数量
threads => 1
}
}
Filter模块
Filter是Logstash功能强大的主要原因,它可以对Logstash Event进行丰富的处理,比如解析数据、删除字段、类型转换等等,常见的有如下几个:
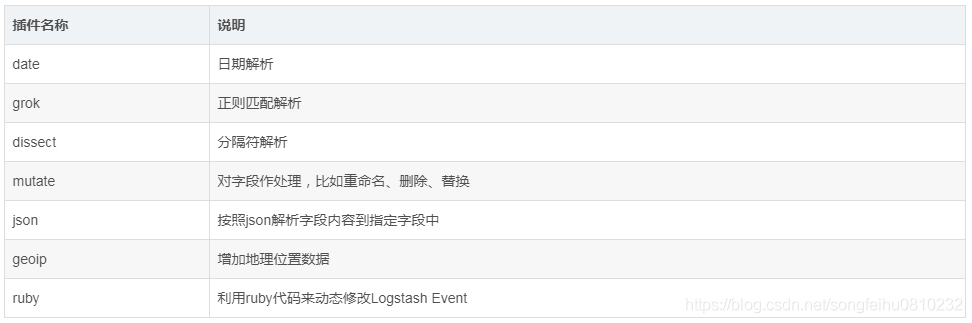
Date插件
date插件可以将日期字符串解析为日期类型,然后替换@timestamp字段或者指定其他字段:
filter{
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
# 记录@timestamp时间,可以设置日志中自定的时间字段,如果日志中没有时间字段,也可以自己生成
target=>“@timestamp”
# 将匹配的timestamp字段放在指定的字段 默认是@timestamp
}
}
Grok插件
grok是filter最重要的插件,grok使用正则表达式来生成grok语法,grok支持许多默认的正则表达式规则,grok中常用patterns的配置路径:
[logstash安装路径]\vendor\bundle\jruby\x.x\gems\logstash-patterns-core-x.x.x\patterns\grok-patterns
grok语法
%{SYNTAX:SEMANTIC}
SYNTAX为grok pattern的名称,SEMANTIC为赋值字段名称。%{NUMBER:duration}可以匹配数值类型,但是grok匹配出的内容都是字符串类型,可以通过在最后指定为int或者float来强转类型:%{NUMBER:duration:int}
自定义正则表达式
例如,如下定义一个关键字为version的参数,内容为两位的数字。
(?<version>[0-9]{2})
自定义grok pattern
我们通过pattern_definitions参数,以键值对的方式定义pattern名称和内容。也可以通过pattern_dir参数,以文件的形式读取pattern。
filter {
grok {
match => {
"message" => "%{SERVICE:service}"
}
pattern_definitions => {
"SERVICE" => "[a-z0-9]{10,11}"
}
}
}
Dissect插件
基于分隔符原理解析数据,解决grok解析时消耗过多cpu资源的问题。dissect语法简单,能处理的场景比较有限。它只能处理格式相似,且有分隔符的字符串。它的语法如下:
1、%{}里面是字段
2、两个%{}之间是分隔符。
例如,有以下日志:
Apr 26 12:20:02 localhost systemd[1]: Starting system activity accounting tool
我想要把前面的日期和时间解析到同一个字段中,那么就可以这样来做:
filter {
dissect {
mapping => {
"message" => "%{ts} %{+ts} %{+ts} %{src} %{prog}[%{pid}]: %{msg}"
}
}
}
Mutate插件
mutate是使用最频繁的插件,可以对字段进行各种操作,比如重命名、删除、替换、更新等,主要操作如下:
1、convert类型转换
2、gsub字符串替换
3、split、join、merge字符串切割、数组合并为字符串、数组合并为数组
4、rename字段重命名
5、update、replace字段内容更新或替换。它们都可以更新字段的内容,区别在于update只在字段存在时生效,而replace在字段不存在时会执行新增字段的操作
6、remove_field删除字段
Json插件
将字段内容为json格式的数据解析出来,如果不指定target的话,那么filter会把解析出来的json数据直接放到根级别。配置实例如下:
filter {
json {
source => "message"
target => "msg_json"
}
}
运行结果:
{
"@version": "1",
"@timestamp": "2014-11-18T08:11:33.000Z",
"host": "web121.mweibo.tc.sinanode.com",
"message": "{\"uid\":3081609001,\"type\":\"signal\"}",
"jsoncontent": {
"uid": 3081609001,
"type": "signal"
}
}
Geoip插件
GeoIP 库可以根据 IP 地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化地图和区域统计非常有用。语法如下:
filter {
geoip {
source => "message"
}
}
运行结果:
{
"message" => "183.60.92.253",
"@version" => "1",
"@timestamp" => "2014-08-07T10:32:55.610Z",
"host" => "raochenlindeMacBook-Air.local",
"geoip" => {
"ip" => "183.60.92.253",
"country_code2" => "CN",
"country_code3" => "CHN",
"country_name" => "China",
"continent_code" => "AS",
"region_name" => "30",
"city_name" => "Guangzhou",
"latitude" => 23.11670000000001,
"longitude" => 113.25,
"timezone" => "Asia/Chongqing",
"real_region_name" => "Guangdong",
"location" => [
[0] 113.25,
[1] 23.11670000000001
]
}
}
Output模块
标准输出
标准输出多用于调试,配置示例:
output {
stdout {
codec => rubydebug
}
}
redis插件
output {
redis{ # 输出到redis的插件,下面选项根据需求使用
batch => true
# 设为false,一次rpush,发一条数据,true为发送一批
batch_events => 50
# 一次rpush发送多少数据
batch_timeout => 5
# 一次rpush消耗多少时间
codec => plain
# 对输出数据进行codec,避免使用logstash的separate filter
congestion_interval => 1
# 多长时间进项一次拥塞检查
congestion_threshold => 5
# 限制一个list中可以存在多少个item,当数量足够时,就会阻塞直到有其他消费者消费list中的数据
data_type => list
# 使用list还是publish
db => 0
# 使用redis的那个数据库,默认为0号
host => ["127.0.0.1:6379"]
# redis 的地址和端口,会覆盖全局端口
key => xxx
# list或channel的名字
password => xxx
# redis的密码,默认不使用
port => 6379
# 全局端口,默认6379,如果host已指定,本条失效
reconnect_interval => 1
# 失败重连的间隔,默认为1s
timeout => 5
# 连接超时的时间
workers => 1
# 工作进程
}
}
elasticsearch插件
output {
# stdout { codec => "rubydebug" }
# 筛选过滤后的内容输出到终端显示
elasticsearch { # 导出到es,最常用的插件
codec => "json"
# 导出格式为json
hosts => ["127.0.0.1:9200"]
# ES地址+端口
index => "logstash-slow-%{+YYYY.MM.dd}"
# 导出到index内,可以使用时间变量
user => "admin"
password => "xxxxxx"
# ES如果有安全认证就使用账号密码验证,无安全认证就不需要
flush_size => 500
# 默认500,logstash一次性攒够500条的数据在向es发送
idle_flush_time => 1
# 默认1s,如果1s内没攒够500,还是会一次性把数据发给ES
}
}
Logstash配置实例
logstash配置的时候,input和output都可以配置多个不同的入参。filter可以针对input里面的每个数据源做不一样的过滤,通过各自定义的type来匹配。配置示例如下:
input{
kafka{
bootstrap_servers => ["192.168.110.31:9092,192.168.110.31:9093,192.168.110.31:9094"]
client_id => "test"
group_id => "test"
auto_offset_reset => "latest" //从最新的偏移量开始消费
consumer_threads => 5
decorate_events => true //此属性会将当前topic、offset、group、partition等信息也带到message中
topics => ["logq","loge"] //数组类型,可配置多个topic
type => "bhy" //所有插件通用属性,尤其在input里面配置多个数据源时很有用
}
file {
# 要导入的文件的位置,可以使用*,例如/var/log/nginx/*.log
path => "/var/lib/mysql/slow.log"
# 记录文件上次读取位置,输出到null表示每次都从文件首行开始解析
sincedb_path => "/dev/null"
# type字段,可表明导入的日志类型
type => "mysql-slow"
}
}
filter{
if[type] == "bhy"{
grok{
........
}
}
if[type] == "mysql-slow"{
mutate{
........
}
}
}
output {
if[type] == "bhy"{
elasticsearch{
hosts => ["192.168.110.31:9200"]
index => "school"
timeout => 300
user => "elastic"
password => "changeme"
}
}
if[type] == "mysql-slow"{
........
}
}
1、针对如下类型的log:
Apr 26 12:20:02 localhost systemd[1]: Starting system activity accounting tool
logstash的配置如下:
input {
file {
path => "/home/songfeihu/logstash-6.2.3/config/test.log"
# 要导入的文件的位置,可以使用*,例如/var/log/nginx/*.log
start_position => "beginning"
# 从文件开始的位置开始读,end表示从结尾开始读
ignore_older => 0
# 多久之内没修改过的文件不读取,0为无限制,单位为秒
sincedb_path => "/dev/null"
# 记录文件上次读取位置,输出到null表示每次都从文件首行开始解析
}
}
filter {
dissect {
mapping => {
"message" => "%{ts} %{+ts} %{+ts} %{src} %{prog}[%{pid}]: %{msg}"
}
}
if "Starting" in [msg]{
grok{
match => {"msg" => "(?<test1>[a-zA-Z0-9]+).*"}
}
}
mutate {
remove_field => ["message"]
}
}
output {
stdout{codec=>rubydebug}
}
output返回值:
{
"host" => "sdn-253",
"@version" => "1",
"@timestamp" => 2019-06-28T08:08:58.062Z,
"msg" => "Starting system activity accounting tool",
"test1" => "Starting",
"ts" => "Apr 26 12:20:02",
"path" => "/home/songfeihu/logstash-6.2.3/config/test.log",
"src" => "localhost",
"prog" => "systemd",
"pid" => "1",
"message" => "Apr 26 12:20:02 localhost systemd[1]: Starting system activity accounting tool"
}
2、针对如下log:
<188>Mar 29 2019 16:57:30 BJQ-219-A1-ITCloud-FW-E8000E-1 %%01SEC/4/POLICYPERMIT(l)[1976979]:VSYS=public;
logstash配置如下:
input {
stdin { }
}
filter {
grok {
match => {
"message" => "\<(?<id>[0-9]+)\>(?<timestamp>([a-zA-Z]+)\s[0-9]{1,2}\s[0-9]{1,4}\s[0-9]{1,2}:[0-9]{1,2}:[0-9]{1,2})\s%{HOSTNAME:hostname} \%\%(?<version>[0-9]{2})(?<model>[a-zA-Z0-9]+)\/(?<severity>[0-9])\/(?<brief>[a-zA-Z0-9]+)\S+:(?<description>.*)"
}
}
}
output {
stdout{codec=>rubydebug}
}
output输出如下:
{
"host" => "sdn-253",
"id" => "188",
"timestamp" => "Mar 29 2019 16:57:30",
"hostname" => "BJQ-219-A1-ITCloud-FW-E8000E-1",
"brief" => "POLICYPERMIT",
"@timestamp" => 2019-06-28T09:54:01.987Z,
"severity" => "4",
"@version" => "1",
"version" => "01",
"model" => "SEC",
"message" => "<188>Mar 29 2019 16:57:30 BJQ-219-A1-ITCloud-FW-E8000E-1 %%01SEC/4/POLICYPERMIT(l)[1976979]:VSYS=public;",
"description" => "VSYS=public;"
}
Flume
Apache Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume有两个版本,分别是Flume OG和Flume NG,目前用的都是FlumeNG。
Flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
Flume的外部结构
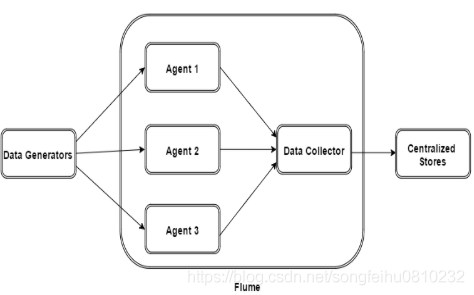
如上图所示,数据发生器(如:facebook,twitter)产生的数据被服务器上的agent所收集,之后数据收容器从各个agent上汇集数据并将采集到的数据存入到HDFS或者HBase中。
Flume事件
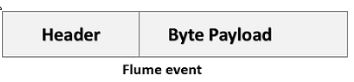
事件作为Flume内部数据传输的最基本单元.它是由一个转载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器,也就是HDFS/HBase)和一个可选头部构成。
典型的Flume 事件如下面结构所示:
Flume agent
对于每一个Agent来说,它就是一共独立的守护进程(JVM),它从客户端哪儿接收收集,或者从其他的Agent哪儿接收,然后迅速的将获取的数据传给下一个目的节点sink,或者agent. 如下图所示flume的基本模型:
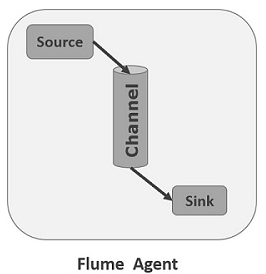
Source
从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal,Flume提供多种数据接收的方式,比如Avro,Thrift,twitter1%等。
Channel
channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性.并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel ,Memort channel等.
Sink
sink将数据存储到集中存储器比如Hbase和HDFS,它从channals消费数据(events)并将其传递给目标地.目标地可能是另一个sink,也可能HDFS,HBase。当Sink写出event成功后,就会向Channel提交事务。Sink事务提交成功,处理完成的event将会被Channel删除。否则Channel会等待Sink重新消费处理失败的event。
Interceptor
拦截器是简单的插件式组件,设置在source和channel之间。source接收到的事件event,在写入channel之前,拦截器都可以进行转换或者删除这些事件。每个拦截器只处理同一个source接收到的事件。可以自定义拦截器。预定义的拦截器包含时间戳拦截器TimestampInterceptor、主机拦截器HostInterceptor、静态拦截器StaticInterceptor、正则过滤拦截器RegexExtractorInterceptor,通过使用不同的拦截器,实现不同的功能。
但是以上的这些拦截器,不能改变原有日志数据的内容或者对日志信息添加一定的处理逻辑,当一条日志信息有几十个甚至上百个字段的时候,在传统的Flume处理下,收集到的日志还是会有对应这么多的字段,也不能对你想要的字段进行对应的处理。根据实际业务的需求,为了更好的满足数据在应用层的处理,通过自定义Flume拦截器,过滤掉不需要的字段,并对指定字段加密处理,将源数据进行预处理。减少了数据的传输量,降低了存储的开销。
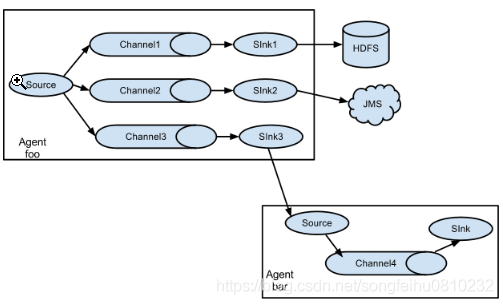
Logstash和Flume对比
1、Logstash比较偏重于字段的预处理,在异常情况下可能会出现数据丢失,只是在运维日志场景下,一般认为这个可能不重要;而Flume偏重数据的传输,几乎没有数据的预处理,仅仅是数据的产生,封装成event然后传输;传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中,数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
2、Logstash有几十个插件,配置比较灵活,flume强调用户自定义开发;
3、Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化
4、Logstash性能以及资源消耗比较严重,且不支持缓存;