1. 始于“混沌”
1.1 混沌的生态环境
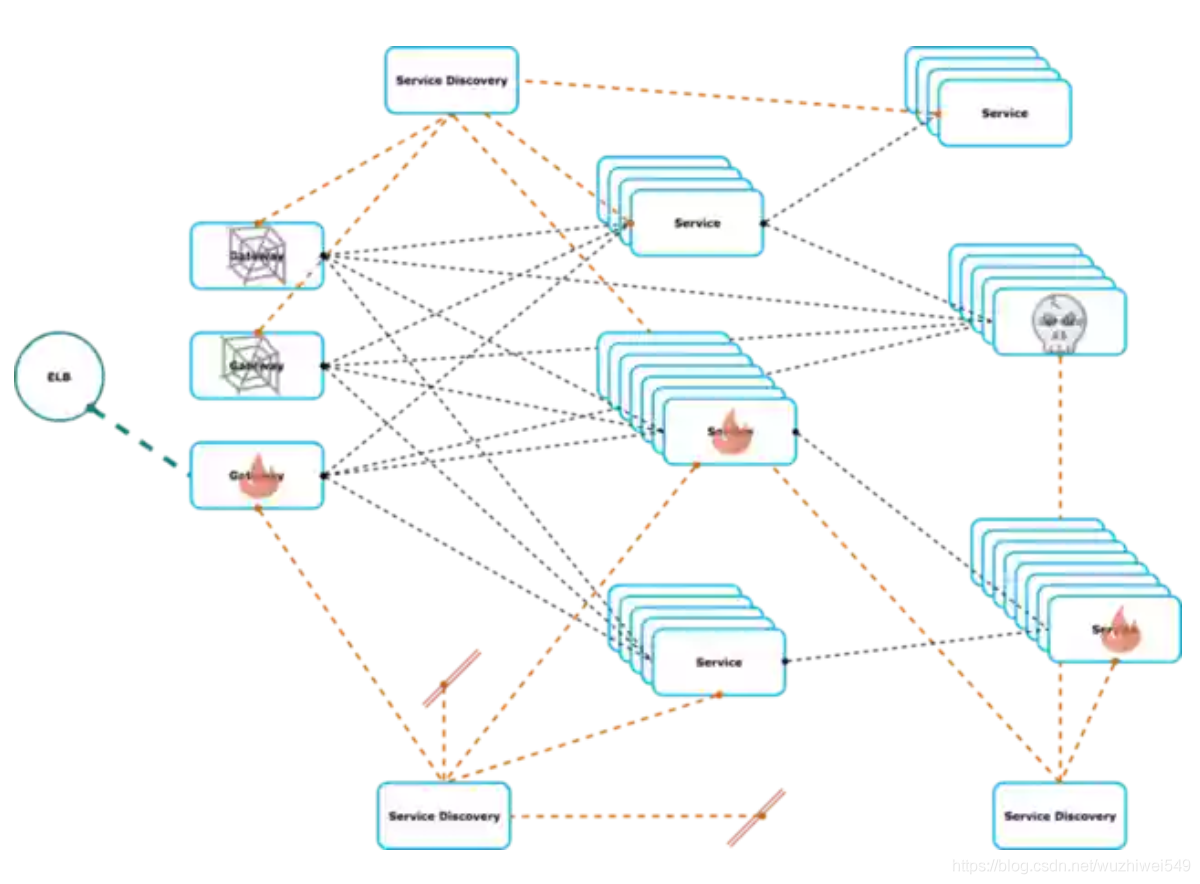
随着Agile、ServiceMesh、DevOps 的持续推进,快速响应业务的需求变化,提高持续交付能力。无独有偶,伴随着大量服务拆分,服务之间依赖复杂化,即便是分布式系统中每个独立的服务都正常工作,服务之间的相互调用也仍然可能造成不可预期的结果。这些结果在现实中可能很少发生,但是一旦发生就会影响整个生产环境,使得整个分布式系统变得混乱不堪,甚至出现服务雪崩、系统全面宕机。
1.2 故障是新常态
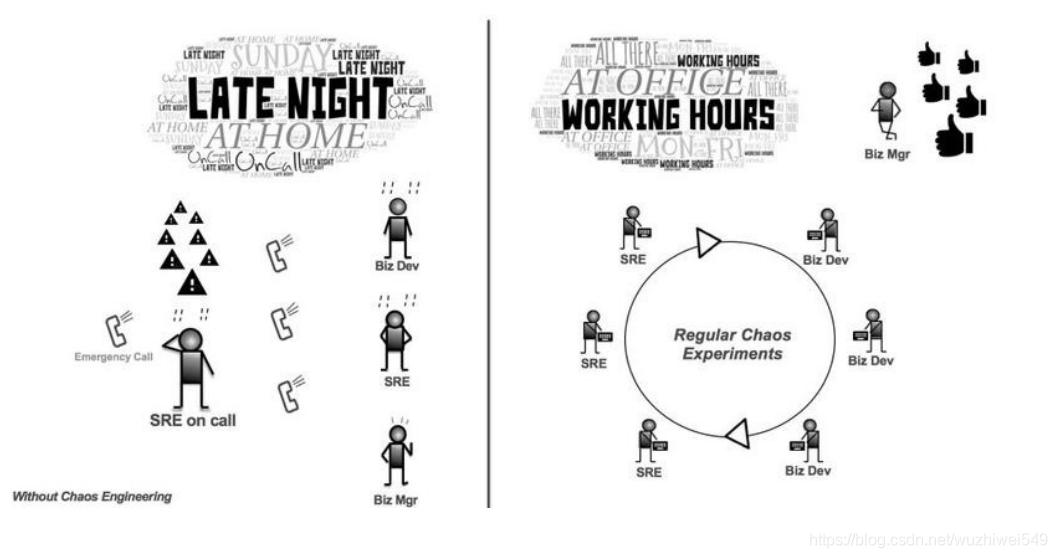
“故障是注定的,随着时间的流逝,一切终将归于失败”。我们必须接受故障发生是新常态的想法,处在部分故障的系统正常运行是完全可行的。当我们处理多达几十个服务实例的小型系统时,100%的健康运行通常是正常状态,故障则是一种特殊情况。然而,在处理大规模系统时,即100%的健康运行几乎是不可能实现的。
2. 拥抱“混沌”
混沌工程不是制造问题,而是揭示问题。
—Nora Jones,Netflix 高级混沌工程师
2.1 探索性测试
在敏捷测试(Agile testing)中,探索性测试(Exploratory Testing)是作为一个重要组成部分而出现的。由Cem Caner首次提出,80年代就一直存在的测试方法,2011年James Whittaker出版《探索式软件测试》后,在业内引起广泛关注。
探索性测试可以说是一种测试思维技术,主要由经验丰富的测试人员实施。该方法能够基于已有的知识、启发式的理念和风险领域在有限的时间内,把“对系统的探索”和“对系统进行测试”结合在一起,达成“敏捷”的目标。
2.2 Netflix提出了混沌工程
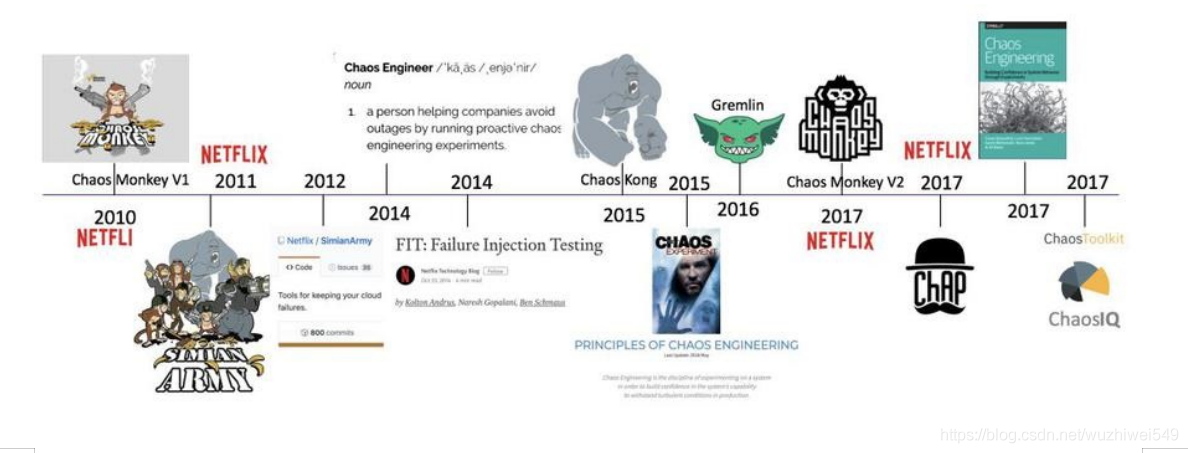
2008年8月, Netflix 主要数据库的故障导致了三天的停机, DVD 租赁业务中断,多个国家的大量用户受此影响。之后 Netflix 工程师着手寻找替代架构,并在2011年起,逐步将系统迁移到 AWS 上,运行基于微服务的新型分布式架构。这种架构消除了单点故障,但也引入了新的复杂性类型,需要更加可靠和容错的系统。为此,Netflix工程师,巧妙地将探索性测试方法,以生产验证的形式,创建了Chaos Monkey(捣乱的猴子),随机注入故障。正如GitHub上的工具维护者所说,“Chaos Monkey会随机终止在生产环境中运行的虚拟机实例和容器。”
随着Chaos Monkey的出现,一门新学科诞生了:混沌工程,被描述为“在分布式系统上进行实验的学科,目的是建立对系统承受生产环境中湍流条件能力的信心。”。
3. 初窥“混沌”
3.1 和传统测试的区别
混沌工程和传统测试(故障注入FIT、故障测试)在关注点和工具集上都有很大的重叠。譬如,在Netflix的很多混沌工程实验研究的对象都是基于故障注入来引入的。混沌工程和这些传统测试方法的主要区别在于:混沌工程是发现新信息的实践过程,而故障注入则是对一个特定的条件、变量的验证方法。
在传统测试中,我们可以写一个断言(assertion),即我们给定一个特定的条件,产生一个特定的输出。测试一般来说只会产生二元的结果,验证一个结果是真还是假,从而判定测试是否通过。严格意义上来说,这个过程并不能让我们发掘出对于系统未知的、尚不明确的认知,它仅仅是对我们已知的系统属性可能的取值进行测验。而实验可以产生新的认知,而且通常还能开辟出一个更广袤的对复杂系统的认知空间。
混沌工程是一种帮助我们获得更多的关于系统的新认知的实验方法。它和已有的功能测试、集成测试等以测试已知属性的方法有本质上的区别。
3.2 混沌工程目标
在处理大规模系统时,即100%的健康运行几乎是不可能实现的。因此,运维的新常态便是接受部分故障。处在部分故障中的系统要求仍能正常运行对外提供服务,这就需要架构本身具备 Resilient 能力,这里的Resilient即为韧性(具备恢复能力)。
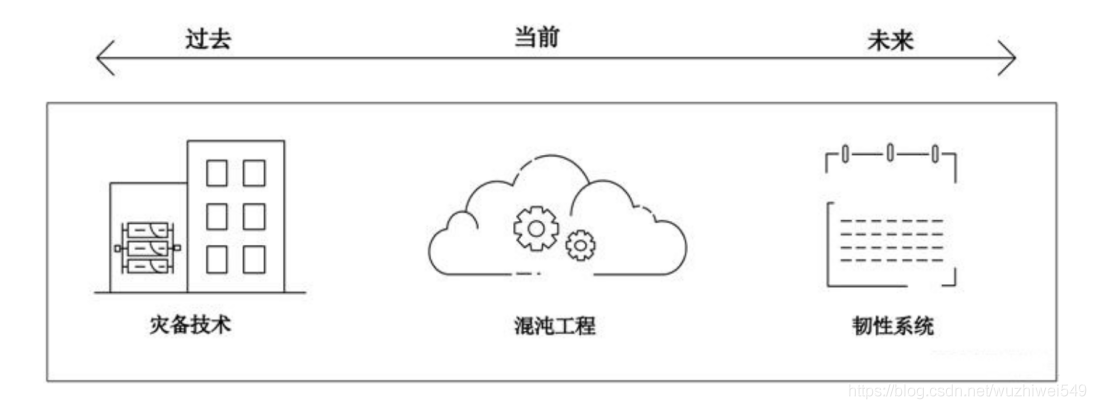
混沌工程就是利用实验提前探知系统风险,通过架构优化和运维模式的改进来解决系统风险,真正实现上述韧性架构,降低企业损失,提高故障免疫力。
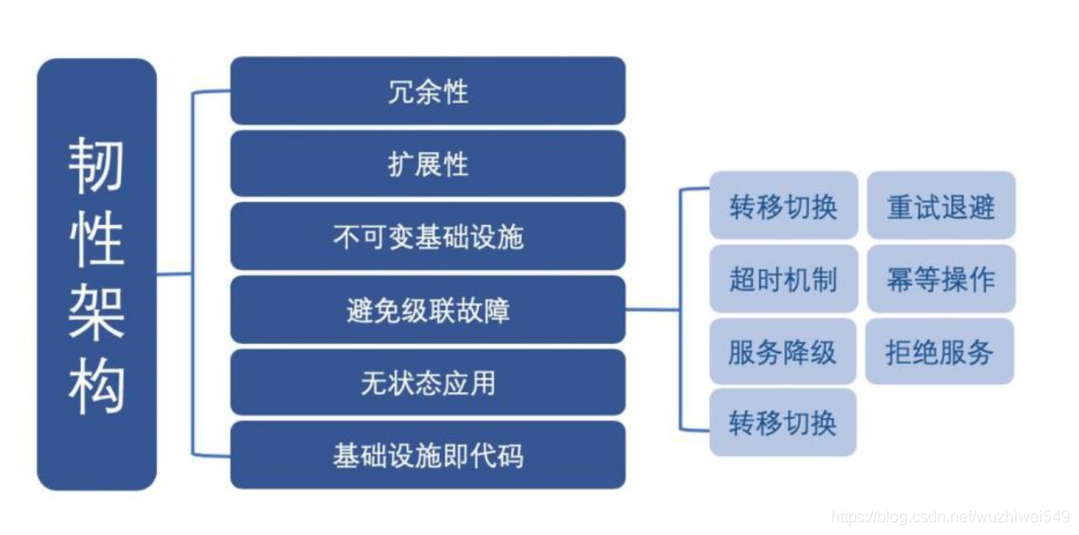
3.3 引入的先决条件
在引入混沌工程之前先要确定你的系统是否已经具备一些弹性来应对真实环境中的一些异常事件,像某个服务异常、网络闪断、瞬间延迟提高等;
另一个先决条件是完善的监控平台,你需要用它来判断系统当前的各项状态。如果你没有对系统行为的可见能力,那么也就无法从实验中得出有效的结论。
3.4 实践五大原则

为了具体地解决分布式系统在规模上的不确定性,可以把混沌工程看作是为了揭示系统缺陷而进行的实验。破坏稳态的难度越大,我们对系统行为的信心就越强。如果发现了一个缺陷,那么我们就有了一个改进目标。避免在系统规模化之后问题被放大。在开发混沌工程实验时,可遵循以下五大原则,将有助于实验设计:
建立稳定状态的假设:
“稳定状态”是可以通过一些指标来定义,当系统指标在测试完成后,无法快速恢复稳态要求,可以认为这个系统是不稳定的。
- 关注可测量输出,而不是系统内部属性;
- 短时间内的度量结果,代表了额系统的稳定状态;
- 验证系统是否工作,而不是如何工作;
多样化现实世界事件:
混沌变量反应了现实世界中的实践,通过潜在的影响或预估频率排定事件的优先级,任何能够破坏稳态的实践都是混沌实验中的一个潜在变量。
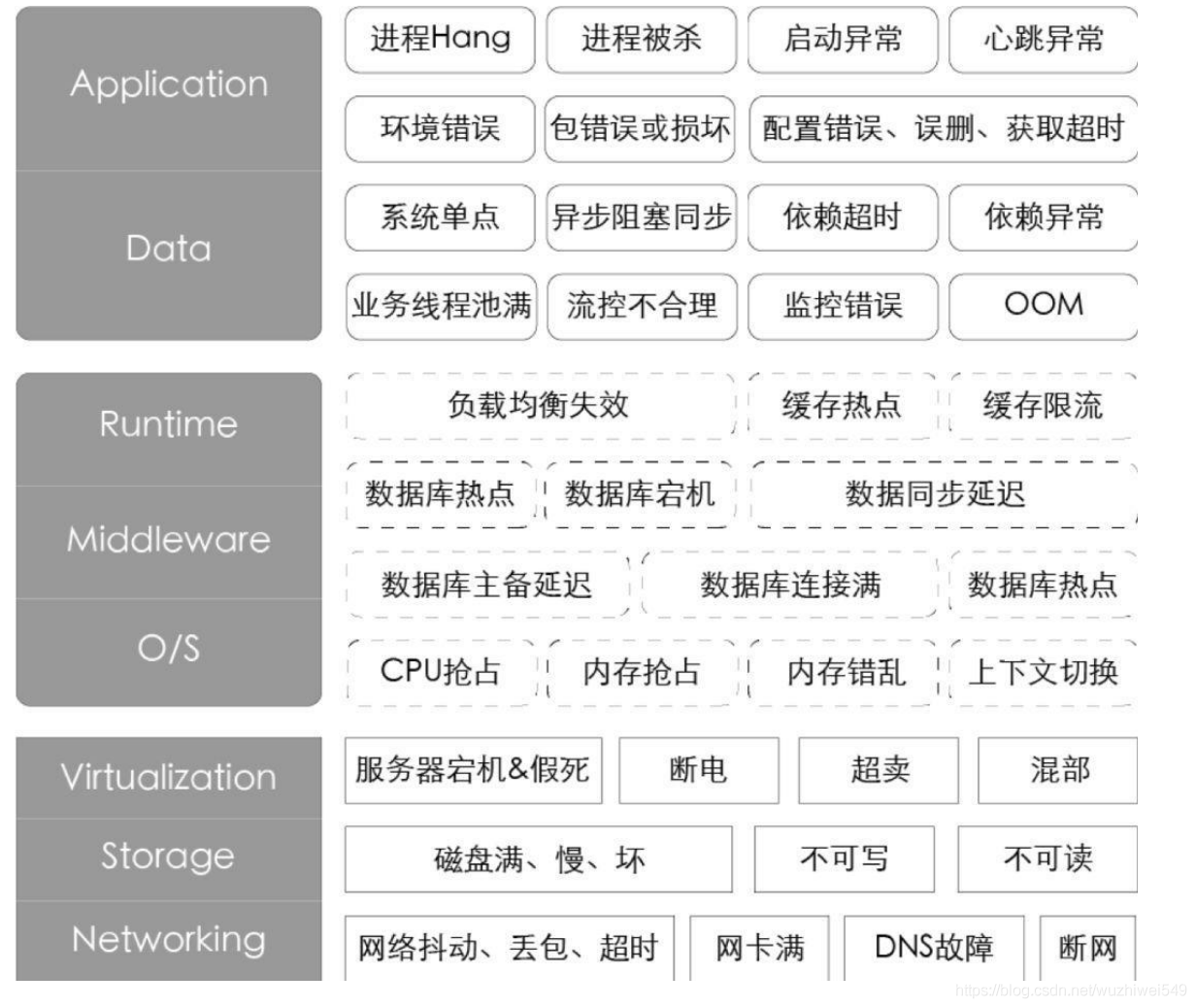
为了能够更体感、有效率地描述故障,我们优先分析了P1和P2的故障(P是阿里对故障等级的描述),提出一些通用的故障场景并按照IaaS层、PaaS层、SaaS层的角度绘制了故障画像。
在生产环境运行实验:
根据环境与流量模式的不同,系统运行效果亦将受到影响。由于运行效果可能随时改变,因此我们应将对实际流量进行采样作为获取可靠请求路径的惟一方法。为了保证系统运行方式的真实性以及同现有部署系统间的关联性,混沌工程原则强烈建议您直接面向生产流量进行实验。
持续自动化运行实验:
当今的系统越来越复杂,这意味着我们无法通过劳动密集型的手动且持续运行。因此我们要在系统中构建自动化持续集成运行。
最小化“爆炸半径”:
混沌实验通过很多方法来探寻故障会造成的未知的、不可预见的影响,关键在于如何让这些薄弱环节曝光出来而不会意外造成更大规模的故障。我们称之为最小化“爆炸半径”。
在生产中进行实验可能会造成不必要的客户投诉,但混沌工程师的责任和义务是确保这些后续影响最小化,且被考虑到。
3.4 实践案例
|
公司 |
开源项目 |
传送门 |
|
Netflix |
Chaos Monkey |
https://github.com/Netflix/chaosmonkey |
|
阿里 |
ChaosBlade |
https://github.com/chaosblade-io/chaosblade |
|
PingCAP |
Chaos Mesh |
https://github.com/pingcap/chaos-mesh |
4. 总结
随着 ServiceMesh,Serverless 等理念的兴起,我们的系统真的趋向于越来越分布式, Netflix 的实践也证明了混沌工程在稳定性领域所带来的巨大意义。相信随着互联网逐渐转变成一项基础设施服务,其稳定性将被不断强调。而我们要做的只是直面故障,不惧故障,避免黑天鹅事件的发生。
不是由你来选择那一刻,而是那一刻来选择你! 你只能选择为之做好准备。