Transformer
Transformer,这是一种仅依赖于注意力机制而不使用循环或卷积的简单模型,它简单而有效,并且在性能方面表现出色。
在时序模型中,2017年最常用的模型是循环神经网络(RNN),RNN是一种序列模型,通过将之前的信息存储在隐藏状态中,使得它能够有效地处理时序信息。然而,由于RNN是按照时间步骤逐个计算的,因此它不易并行化,导致它在计算性能上存在缺陷。
Transformer模型完全基于注意力机制,而不再使用循环神经网络。由于注意力机制可以并行化,因此Transformer具有更好的并行性能和更好的实验结果。
模型结构
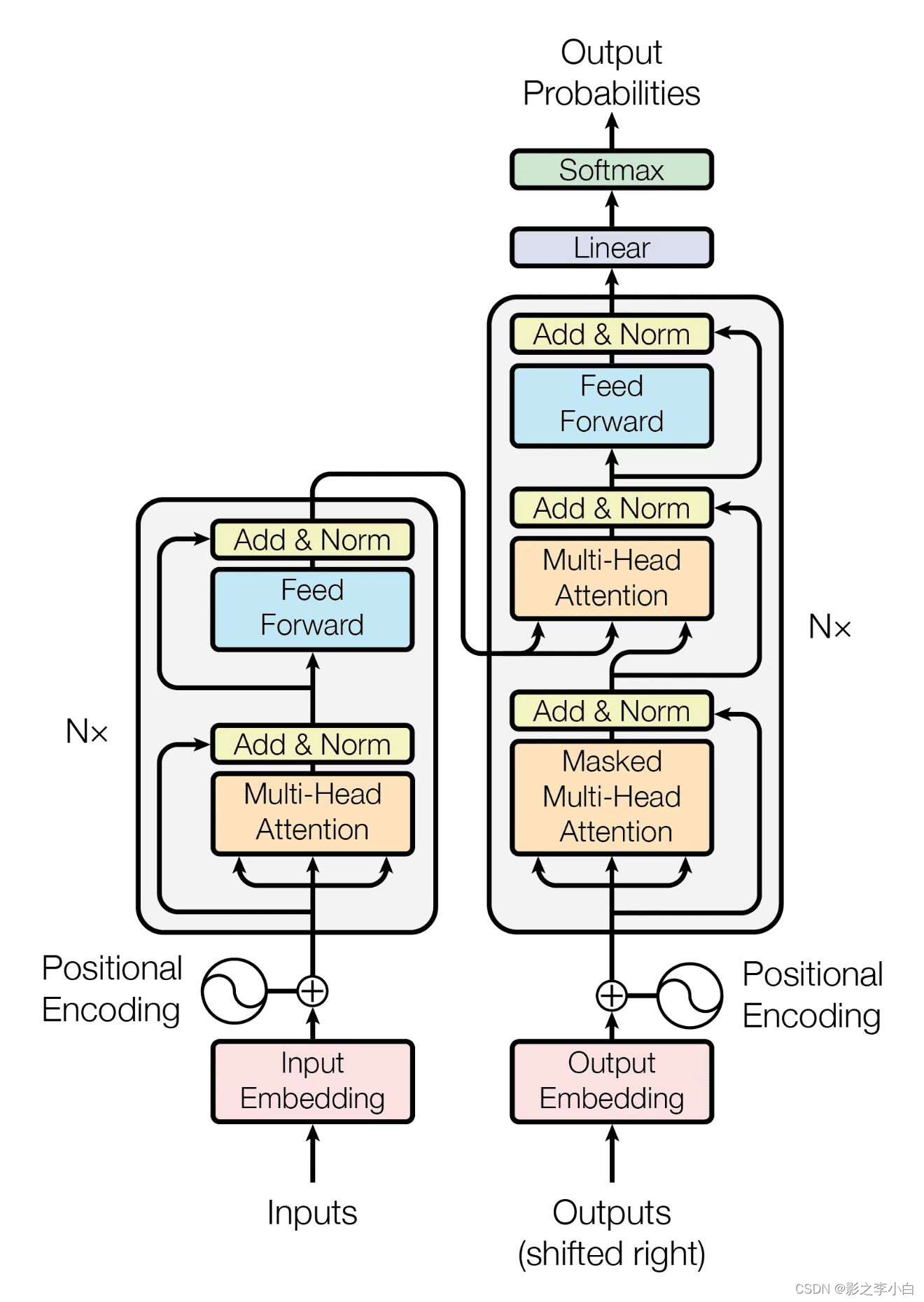
构成组件
- 编码器和解码器:图中左侧为编码器,右侧为解码器。
- 注意力机制:注意力函数是将一个query和一系列key-value映射成一个output的函数,这里的query、key、value、output都是一些向量。权重是由value对应的key和query的compatibility function(相似度)计算得来的,Transformer里面用的注意力算法是“Scaled Dot-Product Attention”。
- 多头注意力(Multi-Head Attention):把query、key、value投影到一个低维,投影h次,然后再做h次的注意力函数,将每个函数的输出并在一起,再投影回来,得到最终的输出。
- 带掩码自注意力层(Masked Multi-Head Attention): 因为在解码器中,算第n个query对应的输出的时候,是不能看到后面内容的值的,所以后面所有内容的权重要通过这种方式设置成0。
- 前馈网络(fully connected feed-forward network):可以理解为一个MLP(多层感知器),会利用它来进行语义空间的转换;Attention层用于抓取整个序列的信息并进行汇聚。
- Embeddings:输入是一个个的词,或者叫词源(token),需要把它映射成一个个向量。Embeddings就是给定任何一个词,用长为d的一个向量来表示它。
- Positional Encoding:Attention机制缺乏时序信息。Positional Encoding可以将每个词在句子中的位置信息加入到嵌入层中,从而为Attention机制提供了时序信息。
整体流程
- 输入数据生成词的嵌入式向量表示(Embedding),生成位置编码(Positional
Encoding,简称PE)。 - 进入Encoders部分。先进入多头注意力层(Multi-Head Attention),是自注意力处理,然后进入全连接层(又叫前馈神经网络层),每层都有ResNet、Add &Norm。
- 每一个Encoder的输入,都来自前一个Encoder的输出,但是第一个Encoder的输入就是 Embedding+ PE。
- 进入Decoders部分。先进入第一个多头注意力层(是Masked自注意力层),再进入第二个多头注意力层(是 Encoder-Decoder 注意力层),每层都有ResNet、Add&Norm。
- 每一个Decoder 都有两部分输入。
Decoder的第一层(Maksed多头自注意力层)的输入,都来自前一个Decoder的输出但是第一个Decoder是不经过第一层的(因为经过算出来也是0)。
Decoder 的第二层(Encoder-Decoder 注意力层)的输入,Query都来自该Decoder的第一层,且每个Decoder的这一层的Key、Value都是一样的,均来自最后一个Encoder。 - 最后经过 Linear、Softmax归一化。
GPT
论文作者取了标题中“generative pre-training”,将模型命名为GPT。
在自然语言理解中,存在许多不同的任务,但标记数据相对较少。因此,针对这个问题,一种解决方法是在没有标注的数据上训练一个预训练模型,然后在有标记的数据上进行微调。
GPT模型基于Transformer架构。与循环神经网络(RNN)相比,Transformer在迁移学习方面更加稳健,因为它具有更结构化的记忆,可以处理更长的文本,并从句子和段落层面提取更好的语义信息。
预训练
该模型从输入的K个单词和模型参数中预测下一个单词的出现概率。将每个单词的预测概率加起来,就得到了目标函数。目标就是通过训练模型,使其能够输出与给定文本类似的文章。
微调模型
在微调任务中有两个目标函数。一个是预测下一个单词,另一个是预测给定完整序列的标签。通过对它们的加权平均来平衡这两个目标函数。
自然语言处理任务的多样性也导致了需要为每个任务构建不同的模型,GPT采用的解决方案是改变输入的形式而不是改变模型本身。
NLP中四种常见的用户任务:
- “分类”(classification),例如对一段文本进行情感分类,判断其是正面还是负面。
- “蕴含”(entailment),即判断一段文本是否蕴含某种假设。
- “相似”(similarity),即判断两段文本的相似程度。
- “多选题”(multiple choice),即从多个答案中选择正确的答案。
在GPT模型中,它们都可以表示为一个序列和对应的标签。
GPT2
在进行下游任务时,使用一个称为“zero shot”的设置。也就是说,在进行下游任务时,不需要下游任务的任何标注信息,也不需要再次训练模型,然后得到了差不多的结果。这种方法的好处是只需训练一个模型,便可以在任何地方使用。
GPT3
GPT3是为了解决GPT2的有效性而设计的。因此,它回到了GPT一开始考虑的few-shot学习的设置,即不再追求太过极致的性能表现,而是在有限的样本上提供有用的信息。
few-shot是指通过提供一些样例来学习,而不是像传统的训练方式那样需要大规模的数据集进行训练。
这样做的好处在于,无需耗费大量的时间和成本来收集和标注数据集,而且模型可以更加关注于样例之间的共性,从而提高模型的泛化能力。
在GPT3的微调设置里,他是要求不做梯度更新的。
在 Meta Learning 中,模型不仅要学习如何解决特定的任务,还要学习如何快速适应新的任务。这样的训练方法有助于提高模型的泛化能力,使得模型在新的领域中表现更好。
in-context learning 是另一种训练模型的方法。它指的是在给定一个任务的上下文中,让模型从少量样本中学习如何解决这个任务。in-context learning 只会对给定的任务产生影响,不会改变模型的权重。
局限性
- 在人类语言中,有些词是必须要记住的,而有些则不是。但GPT3无法区分它们的重要性。
- 由于训练数据来自整个网络上的文章,其有效性可能不高。对于人类来说,这种方式可能不可靠。
- 像许多深度学习模型一样,GPT3无法解释。
GPT4
主要是功能性描述介绍。
- GPT-4是一个大型多模型,它在某些困难的专业和学术基准测试中具有人类水平的表现。
- GPT-4 的一个重点是构建可预测扩展的深度学习堆栈。
- OpenAI在GPT-4的开发和部署过程中实施了各种安全措施和流程,减少了它产生有害内容的能力。
相关论文
《Attention is all you need》[J]. Advances in neural information processing systems, 2017.
《Improving language understanding by generative pre-training》[J]. 2018.
《Language models are unsupervised multitask learners》[J]. OpenAI blog, 2019.
《Language models are few-shot learners》[J]. Advances in neural information processing systems, 2020
《GPT-4 Technical Report》
《GPT-4 System Card》