并发的发展历史
其实,在早期计算机并没有包含操作系统,这个时候,这个计算机只跑一个程序,这个程序独享计算机的所有资源,这个时候不存在什么并发问题,但是对计算机的资源来说,确实是一种浪费。早期编程都是基于单进程来进行,随着计算机技术的发展,于是,操作系统出现了,操作系统改变了这种现状,让计算机可以运行多个程序,并且不同的程序占用独立的计算机资源,如内存,CPU等。
操作系统出现后:
- 资源利用率:可以在其他程序执行过程出现等待的时候,去执行其他程序,从而提高程序的利用率
- 公平性:所有的程序可以共享计算机资源,一种有效的方式是通过时间片的方式来让程序共享计算机资源
- 任务通信:在编写多任务程序时,可以一个程序执行一个任务,必要时,程序之间进行通信即可
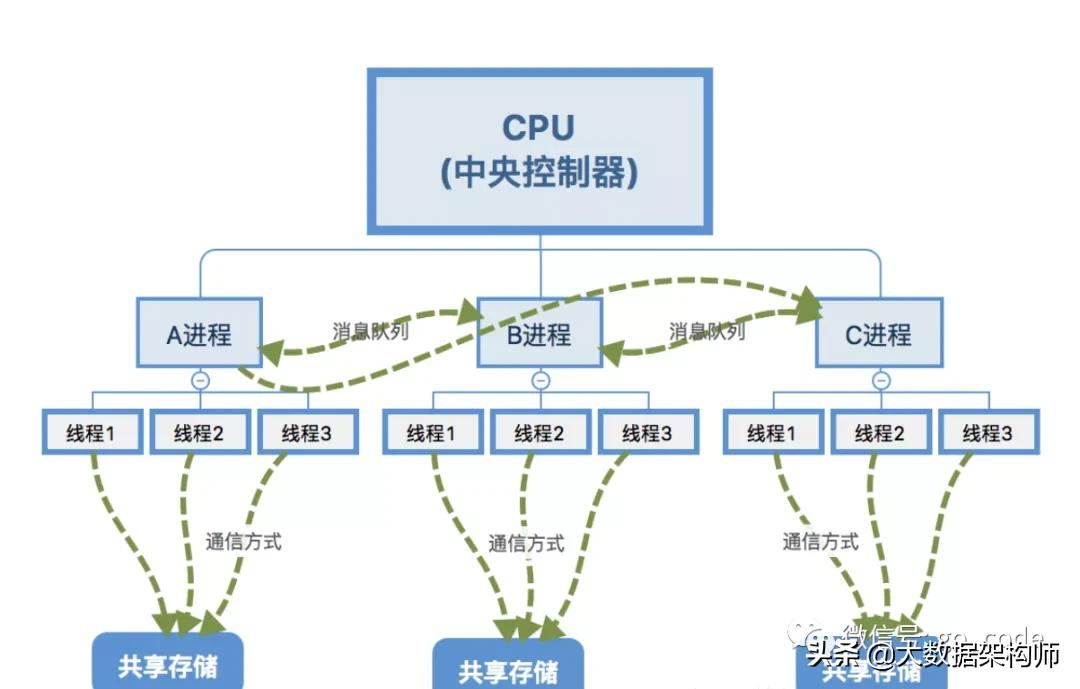
当计算机从单程序变成多程序之后,这个时候又发展出了多线程,线程是进程里面的每个执行控制流,或叫执行路线。如果没有明确的协同机制,那么每个线程将独立运行,共享着进程的内存及CPU资源,多进程多线程之间虽然让多任务并行处理的能力大大提升,但是本质上还是分时系统,并不是时间上真正的并行,解决这个问题的方式显而易见,就是让多个CPU能够同时计算任务,从而实现真正意义上的多任务并行。
并发的优势
并发可以满足多任务任务需求,比如一边写代码一边听音乐,即使编写多线程程序具有挑战性,但它仍在使用中,是因为它可以带来如下的好处:
- 更好的资源利用
- 在某些场景下程序的设计会更简单
- 提升程序的响应性
- 多进程/多任务:单个CPU下的并发,如在使用QQ的同时打开爱奇艺看剧
- 多线程/子任务:单个应用下的并发,如博客网站可以处理不同用户的访问请求
进程的调度
单核的 CPU 一次只能执行一个任务,想要实现多任务,需要把 CPU 的运行时间切成一段一段的时间片,每个时间片运行一个程序,循环的分配时间片给不同的应用程序,由于时间片非常的短,在用户看来,就像是多个任务同时在运行。

进程的调度
在计算机的世界里,内核把CPU的执行时间切分成许多时间片,比如1秒钟可以切分为100个10毫秒的时间片,每个时间片再分发给不同的进程,通常,每个进程需要多个时间片才能完成一个请求。这样,虽然微观上,比如说就这10毫秒时间CPU只能执行一个进程,但宏观上1秒钟执行了100个时间片,于是每个时间片所属进程中的请求也得到了执行,这就实现了请求的并发执行。
流水线
CPU就好像一个流水线上的工人,不断的处理流水线上的各种信息包裹,打开包裹读取指令并执行,遇到执行慢的IO调用(或执行时间片结束)则会暂时把它放到等候区,继续处理流水线上下一个等待处理的包裹。等候区有很多这样的包裹,等待着系统的IO执行完成,当IO调用结束后,又开始进入到等待处理队列。
进程的缺点:在操作系统中,每个进程的内存空间都是独立的,这样用多进程实现并发就有两个缺点:一是内核的管理成本高,二是无法简单地通过内存同步数据,很不方便于是多线程模式就出现了。
线程的调度
线程,是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。线程总是在进程之内的。一个进程至少会包含一个线程。
如果一个进程只包含了一个线程,那么它里面的所有代码都只会被串行地执行。每个进程的第一个线程都会随着该进程的启动而被创建,它们可以被称为其所属进程的主线程。相对应的,如果一个进程中包含了多个线程,那么其中的代码就可以被并发地执行。除了进程的第一个线程之外,其他的线程都是由进程中已存在的线程创建出来的。所以,线程可以通过共享内存地址空间,解决内核的管理成本、内存同步数据的问题。
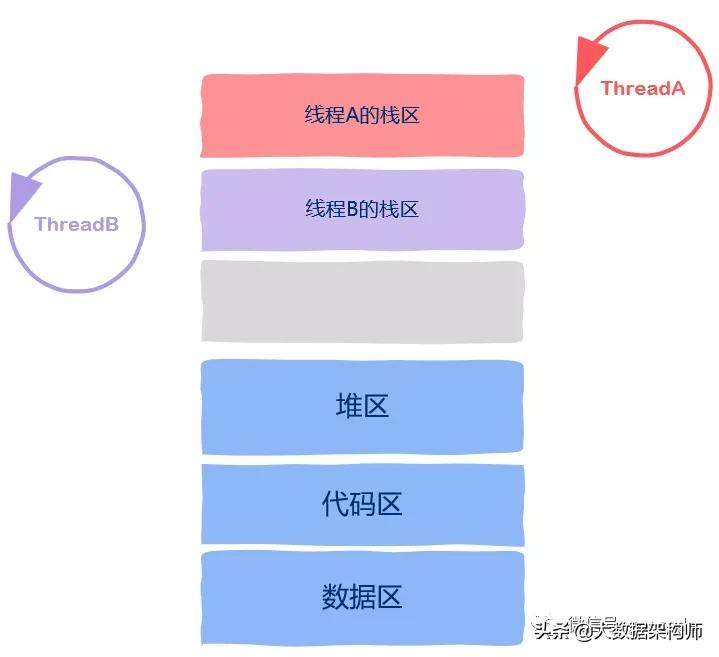
线程
由于线程运行的本质就是函数运行,函数运行时信息是保存在栈帧中的,因此 每个线程都有自己独立的、私有的栈区。

代码区
进程地址空间中的代码区,这里保存的是什么呢?从名字中有的同学可能已经猜到了,没错,这里保存的就是我们写的代码,更准确的是 编译后的可执行机器指令。
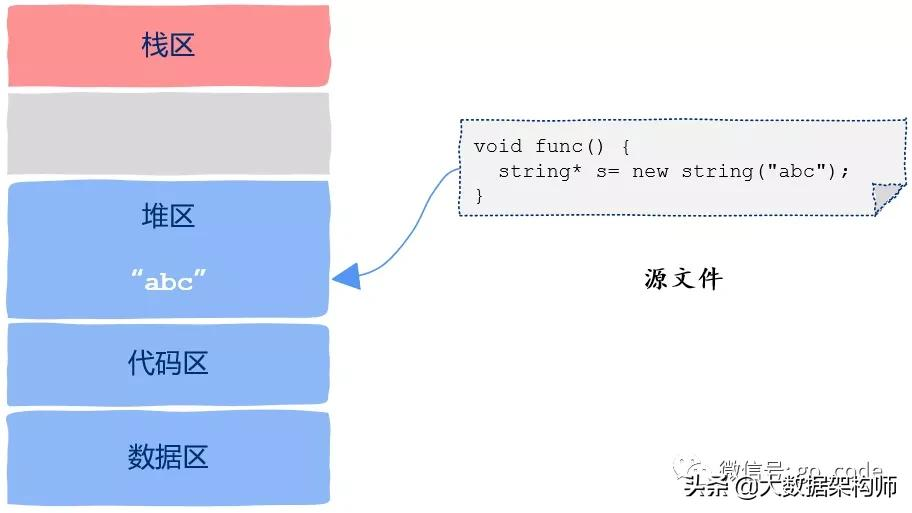
heap
heap很显然,只要知道变量的地址,也就是指针,任何一个线程都可以访问指针指向的数据,因此堆区也是线程共享的属于进程的资源。
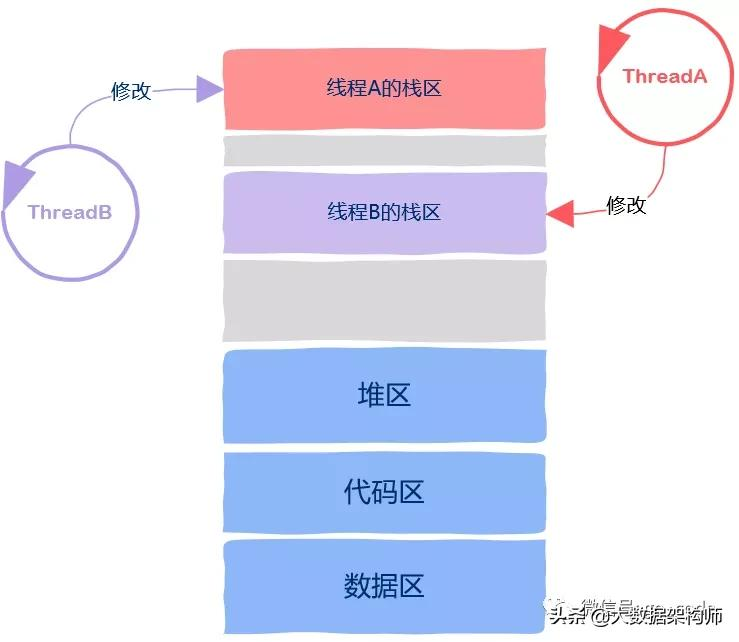
stack
通常来说栈区是线程私有,既然有通常就有不通常的时候,不通常是因为不像进程地址空间之间的严格隔离,线程的栈区没有严格的隔离机制来保护,因此 如果一个线程能拿到来自另一个线程栈帧上的指针,那么该线程就可以改变另一个线程的栈区,也就是说这些线程可以任意修改本属于另一个线程栈区中的变量。
线程的调度与缺点:
在同一个进程中并行运行多个线程,是对在同一台计算机上并行运行多个进程的模拟。因此,线程也被称为轻量级进程。与进程调度类似,CPU在线程之间快速切换,制造了线程并行运行的假象。由于各个线程都可以访问进程地址空间的每一个内存地址,所以一个线程可以读、写,甚至清除另一个线程的堆栈。也就是说,线程之间是没有保护的。但要注意的是,每个线程都有自己的堆栈、程序计数器、寄存器等信息,这些不是共享的。

上下文切换
线程的切换是由内核控制的,什么时候会切换线程呢?不只时间片用尽,当调用阻塞方法时,内核为了CPU 充分工作,也会切换到其他线程执行。一次上下文切换的成本在几十纳秒到几微秒间,当线程繁忙且数量众多时,这些切换会消耗绝大部分的CPU运算能力。
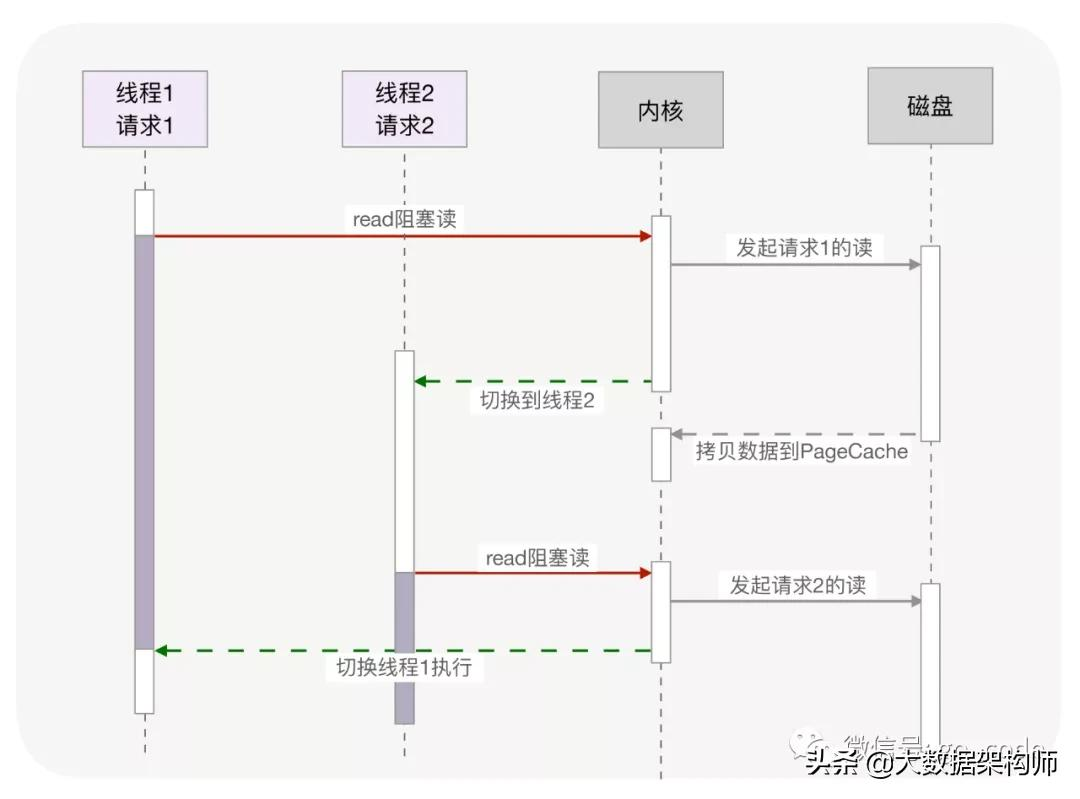
协程的调度
协程就是用户态的线程。通常创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有8MB,而协程栈的大小通常只有几十 KB。而且,C库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着10万个协程。

两级线程模型中用户线程与内核线程是一对一关系
每个协程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU中的栈寄存器SP指向了当前协程的栈,而指令寄存器IP保存着下一条要执行的指令地址。因此,从协程1切换到协程2时,首先要把SP、IP寄存器的值为线程1保存下来,再从内存中找出协程2上一次切换前保存好的寄存器值,写入CPU的寄存器,这样就完成了协程切换。

在GO语言中,语言的运行时系统会帮助我们自动地创建和销毁系统级的线程。这里的系统级线程指的就是我们刚刚说过的操作系统提供的线程。而对应的用户级协程指的是架设在系统级线程之上的,由我们编写的程序完全控制的代码执行流程。用户级协程的创建、销毁、调度、状态变更以及其中的代码和数据都完全需要我们的程序自己去实现和处理。这带来了很多优势,比如,因为它们的创建和销毁并不用通过操作系统去做,所以速度会很快,又比如,由于不用等着操作系统去调度它们的运行,所以往往会很容易控制并且可以很灵活。
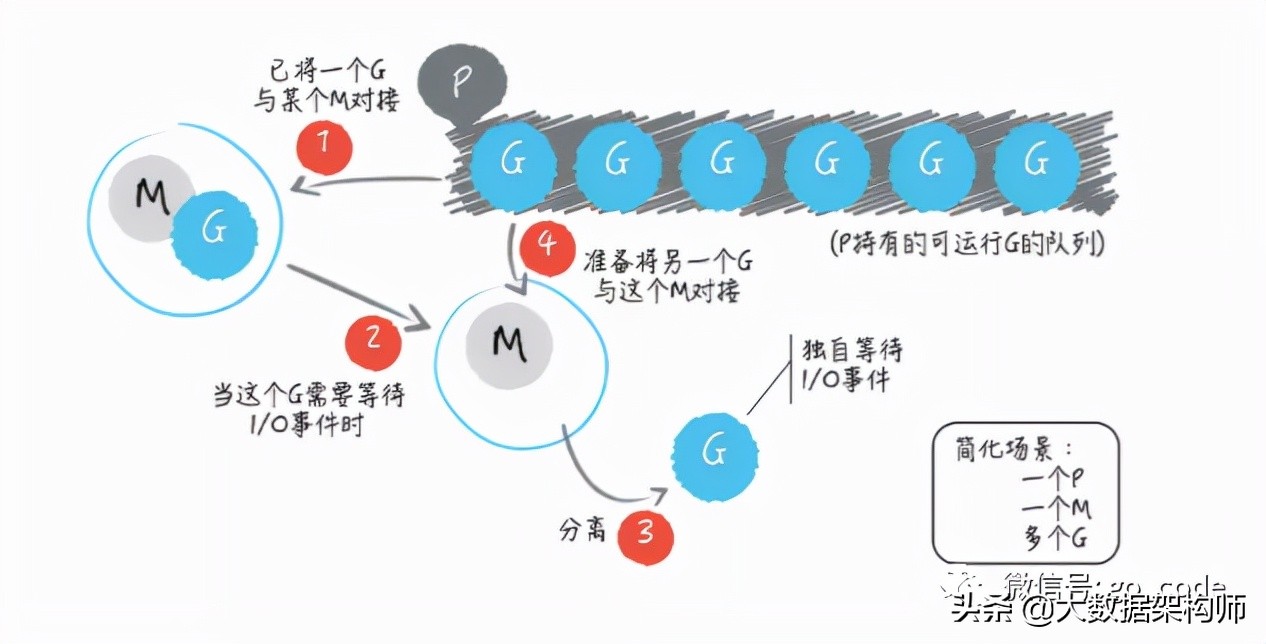
- G – Goroutine,Go协程,是参与调度与执行的最小单位
- M – Machine,指的是系统级线程
- P – Processor,指的是逻辑处理器,P关联了的本地可运行G的队列(也称为LRQ),最多可存放256个G。
其中的M指代的就是系统级线程。而P指的是一种可以承载若干个G,且能够使这些G适时地与M进行对接,并得到真正运行的中介。
当一个正在与某个M对接并运行着的G,需要因某个事件(比如等待 I/O或锁的解除)而暂停运行的时候,调度器总会及时地发现,并把这个G与那个M分离开,以释放计算资源供那些等待运行的G使用。而当一个G需要恢复运行的时候,调度器又会尽快地为它寻找空闲的计算资源(包括M)并安排运行。另外,当M不够用时,调度器会帮我们向操作系统申请新的系统级线程,而当某个M已无用时,调度器又会负责把它及时地销毁掉。所以Go程序总是能高效地利用操作系统和计算机资源。程序中的所有goroutine也都会被充分地调度,其中的代码也都会被并发地运行,即使这样的goroutine有数以十万计,也仍然可以如此。
小 结
进程、线程、协程的区别主要体现在执行体的颗粒度上。最初的执行体任务比较简单,用一个进程就能满足需求,随着执行体做的事情越来越复杂,就出现了进程内多任务的需求。
进程和线程都属于系统级的任务,切换进程、线程都需要经历用户态跃迁内核态,切换成功后再由内核态切回用户态。
为了实现高性能,我们应该尽可能的减少异步线程。因为协程没有局部存储,相对来说空间成本就小很多,同时它又能满足需求。