一、算法原理概述
MD5 即Message-Digest Algorithm 5 (信息-摘要算法5)
- MD4 (1990)、MD5(1992, RFC 1321) 由
Ron Rivest发明,是广泛 使用的Hash 算法,用于确保信息传输的完整性和一致性。 - MD5 使用little-endian(小端模式),输入任意不定长度信息,以 512-bit 进行分组,生成四个32-bit 数据,最后联合输出固定 128-bit 的信息摘要。
- MD5 算法的基本过程为:填充、分块、缓冲区初始化、循环压 缩、得出结果。
- MD5 不是足够安全的。
Hans Dobbertin在1996年找到了两个不同的512-bit 块,它们 在MD5 计算下产生相同的hash值。- 至今还没有真正找到两个不同的消息,它们的MD5 的
hash值相等。
基本流程
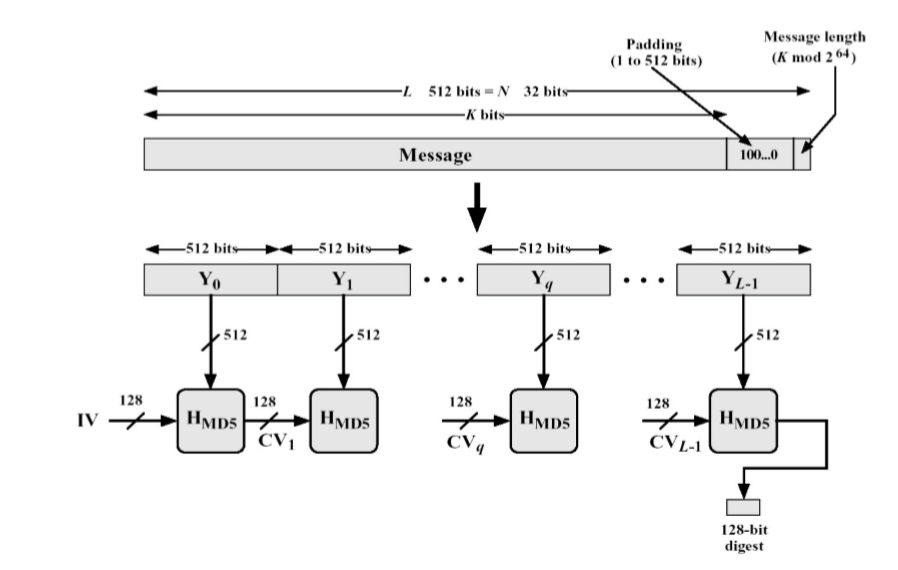
填充padding
- 在长度为Kbits 的原始消息数据尾部填充长度为Pbits 的标识 100…0,1< P < 512 (即至少要填充1个bit),使得填充后的消息位 数为:K + P=448 (mod 512).
- 注意到当K=448 (mod 512) 时,需要P= 512.
- 再向上述填充好的消息尾部附加K 值的低64位(即K mod 264), 最后得到一个长度位数为K + P+ 64= 0 (mod 512) 的消息。
分块
- 把填充后的消息结果分割为L个512-bit 分组:Y0, Y1, …, YL-1。
- 分组结果也可表示成N个32-bit 字M0, M1, …, MN-1,N= Lx16。
初始化
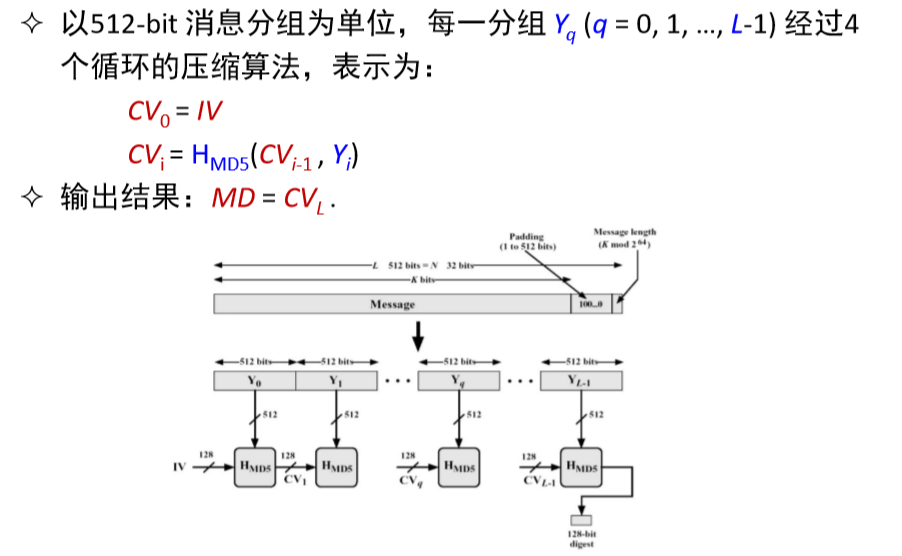
- 初始化一个128-bit 的MD 缓冲区,记为CVq,表示成4个32-bit 寄存器(A, B, C,D);CV0= IV。迭代在MD 缓冲区进行,最后一 步的128-bit 输出即为算法结果。
压缩函数

每轮循环中的一次迭代运算逻辑
- 对A迭代:a <— b+ ((a+ g(b, c, d) + X[k] + T[i]) <<<s)
- 缓冲区(A, B, C, D) 作循环轮换: (B, C, D, A) <—(A, B, C, D)
说明:
- a, b, c, d: MD 缓冲区(A, B, C, D) 的当前值。
- g: 轮函数(F, G, H, I中的一个)。
- <<<s: 将32位输入循环左移(CLS) s位。
- X[k] : 当前处理消息分组的第k个(k= 0…15) 32位字,即 M(qx16+k)。
- T[i] : T表的第i个元素,32位字;T表总共有64个元素,也 称为加法常数。
- : 模232 加法。
二、总体结构
public class MD5 {
//一系列常量数值
//开始使用MD5加密
private String start(String message){
//分块
//填充
//即小于448bit的情况,先填充100...0再填充K值的低64位
//此时只会新增一个分组
if(rest <= 56){
//填充100...0
//填充K值低64位
//处理分组
H(divide(inputBytes, i*64));
//即大于448bit的情况,先填充100...0再填充K值的低64位
//此时会新增两个分组
}else{
//填充10000000
//填充00000000
//填充低64位
//处理第一个尾部分组
H(divide(inputBytes, i*64));
//处理第二个尾部分组
H(divide(inputBytes, i*64));
}
//将Hash值转换成十六进制的字符串
//小端方式!
}
//从inputBytes的index开始取512位,作为新的512bit的分组
private static long[] divide(byte[] inputBytes,int start){
//存储一整个分组,就是512bit,数组里每个是32bit,就是4字节,为了消除符号位的影响,所以使用long
}
// groups[] 中每一个分组512位(64字节)
// MD5压缩函数
private void H(long[] groups) {
//缓冲区(寄存器)数组
//四轮循环
for(int n = 0; n < 4; n++) {
//16轮迭代
for(int i = 0; i < 16; i++) {
}
}
//加入之前计算的结果
//防止溢出
}
public static void main(String []args){
MD5 md=new MD5();
String message = "helloMD5";
System.out.println("MD5-Algorithm:\n\nOrigin Message: " + message);
System.out.println("Result Message: " + md.start(message));
System.out.println("Result Message(UpperCase): " + md.resultMessage.toUpperCase());
//F0F99260B5A02508C71F6D81C15E9A44
//3ED9E5F6855DBCDBCD95AC6C4FE0C0A5
}
}
三、模块分解
填充
填充时有两种情况
- 如果去掉整数个512bit的小组,剩下的位数不超过448bit,那样就可以先填充100…00(如果正好是448bit就不用填充了),再填充用K值的低64位64bit,那样的话就只是新增了一个小组
- 如果去掉整数个512bit的小组,剩下的位数超过了448bit,那样不够填充64bit,所以需要填充100…00到512bit,构成一个小组;然后再在第二个小组填充448bit个0,最后填充K值的低64位bit,这样就会新增两个小组
//填充
int rest = byteLen % 64;
//即将填充的一个分组
byte [] paddingBytes=new byte[64];
//原来的尾部数据
for(int i=0;i<rest;i++)
paddingBytes[i]=inputBytes[byteLen-rest+i];
//即小于448bit的情况,先填充100...0再填充K值的低64位
//此时只会新增一个分组
if(rest <= 56){
//填充100...0
if(rest<56){
//填充10000000
paddingBytes[rest]=(byte)(1<<7);
//填充00000000
for(int i=1;i<56-rest;i++)
paddingBytes[rest+i]=0;
}
//填充K值低64位
for(int i=0;i<8;i++){
paddingBytes[56+i]=(byte)(K&0xFFL);
K=K>>8;
}
//处理分组
H(divide(paddingBytes,0));
//即大于448bit的情况,先填充100...0再填充K值的低64位
//此时会新增两个分组
}else{
//填充10000000
paddingBytes[rest]=(byte)(1<<7);
//填充00000000
for(int i=rest+1;i<64;i++)
paddingBytes[i]=0;
//处理第一个尾部分组
H(divide(paddingBytes,0));
//填充00000000
for(int i=0;i<56;i++)
paddingBytes[i]=0;
//填充低64位
for(int i=0;i<8;i++){
//这里很关键,使用小端方式,即Byte数组先存储len的低位数据,然后右移len
paddingBytes[56+i]=(byte)(K&0xFFL);
K=K>>8;
}
//处理第二个尾部分组
H(divide(paddingBytes,0));
}
分块
这里调用了divide分组函数,将完整小组分成个数为16,单个元素为32bit的数组
再直接调用H压缩函数,进行四轮循环和16次迭代
//分块
//完整小组(512bit)(64byte)的个数
int groupCount = byteLen/64;
for(int i = 0;i < groupCount;i++){
//每次取512bit
//处理一个分组
H(divide(inputBytes, i*64));
}
分组函数
这个函数传入的参数是一个字节数组,以及一个代表从哪里开始截取的int值
效果就是将这个字节数组从start开始的64个字节组成一个
元素个数为16,单个元素为32bit的数组
采用的方法是每次取四个字节,采用小端的方式拼接成一个long型的整数
因为int在某些情况下是4个字节,所以就是正好32bit,但是带符号,就影响后面数据的运算
//从inputBytes的index开始取512位,作为新的512bit的分组
private static long[] divide(byte[] inputBytes,int start){
//存储一整个分组,就是512bit,数组里每个是32bit,就是4字节,为了消除符号位的影响,所以使用long
long [] group=new long[16];
for(int i=0;i<16;i++){
//每个32bit由4个字节拼接而来
//小端的从byte数组到bit恢复方法
group[i]=byte2unsign(inputBytes[4*i+start])|
(byte2unsign(inputBytes[4*i+1+start]))<<8|
(byte2unsign(inputBytes[4*i+2+start]))<<16|
(byte2unsign(inputBytes[4*i+3+start]))<<24;
}
return group;
}
MD5压缩函数
用了两层循环
第一层表示四轮循环
第二层表示16轮迭代
中间按照缓冲区运算的要求处理数据
这里直接处理的是result数组,也就是真实的缓冲区,所以在开始暂存了它们当时的值为a,b,c,d
运算完毕后要加上这些值
运算过程中以及运算结束会有一些防溢出的操作
(有时候没有这个就会出错)
// groups[] 中每一个分组512位(64字节)
// MD5压缩函数
private void H(long[] groups) {
//缓冲区(寄存器)数组
long a = result[0], b = result[1], c = result[2], d = result[3];
//四轮循环
for(int n = 0; n < 4; n++) {
//16轮迭代
for(int i = 0; i < 16; i++) {
result[0] += (g(n, result[1], result[2], result[3])&0xFFFFFFFFL) + groups[k[n][i]] + T[n][i];
result[0] = result[1] + ((result[0]&0xFFFFFFFFL)<< S[n][i % 4] | ((result[0]&0xFFFFFFFFL) >>> (32 - S[n][i % 4])));
//循环轮换
long temp = result[3];
result[3] = result[2];
result[2] = result[1];
result[1] = result[0];
result[0] = temp;
}
}
//加入之前计算的结果
result[0] += a;
result[1] += b;
result[2] += c;
result[3] += d;
//防止溢出
for(int n = 0; n < 4 ; n++) {
result[n] &=0xFFFFFFFFL;
}
}
最后结果转换为字符串
之前得到的结果就是result数组,四个元素,每个元素是一个32bit的数据
现在要把他们转换为字符串
但是需要小端的处理方式
即long的低位作为字符串的高位
每次以一个字节处理,32bit四个字节分别通过与运算和移位运算分离出来,再让long的低位在前,高位在后,得到十六进制字符串就是MD5编码的结果
//将Hash值转换成十六进制的字符串
//小端方式!
for(int i=0;i<4;i++){
resultMessage += Long.toHexString(result[i] & 0xFF) +
Long.toHexString((result[i] & 0xFF00) >> 8) +
Long.toHexString((result[i] & 0xFF0000) >> 16) +
Long.toHexString((result[i] & 0xFF000000) >> 24);
}
四、数据结构
long []groups 存储小组
String resultMessage存储结果字符串
//四个寄存器的初始向量IV,采用小端存储
static final long A=0x67452301L
static final long B=0xefcdab89L
static final long C=0x98badcfeL
static final long D=0x10325476L
private long [] result={A,B,C,D}; 模拟存储结果的四个寄存器
static final long T[][]迭代过程中采用的近似值int(2^32 x |sin(i)|)
static final int k[][] 表示X[k]中的的k取值,决定如何使用消息分组中的字
static final int S[][] 各次迭代中采用的做循环移位的s值
private static long g(int i, long b, long c, long d) 4轮循环中使用的生成函数(轮函数)g
五、运行结果
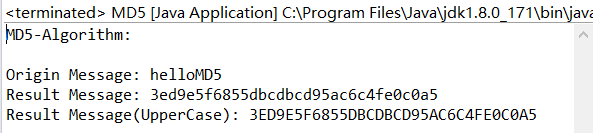
输入原始消息:helloMD5
得到编码结果为:3ED9E5F6855DBCDBCD95AC6C4FE0C0A5
用站长之家的工具验证,结果正确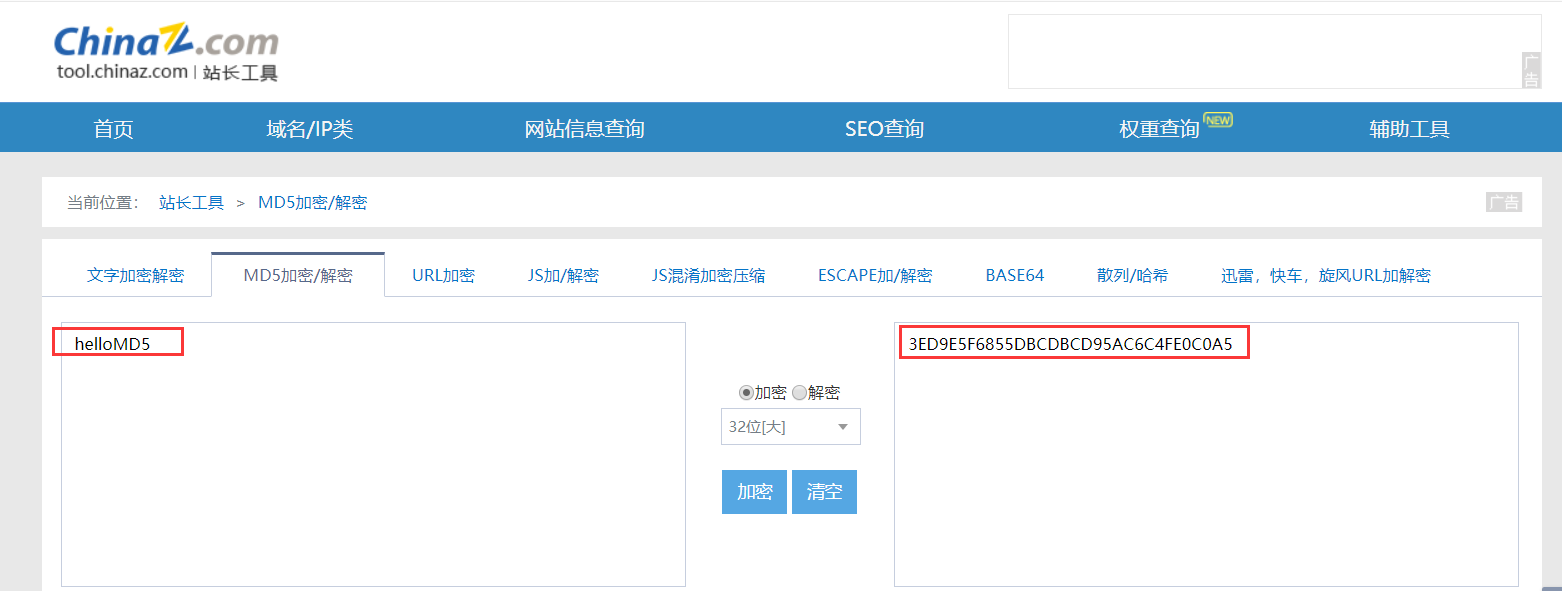
六、源代码
/**
* @author Janking
*/
public class MD5 {
//存储小组
long[] groups = null;
//存储结果
String resultMessage = "";
//四个寄存器的初始向量IV,采用小端存储
static final long A = 0x67452301L;
static final long B = 0xefcdab89L;
static final long C = 0x98badcfeL;
static final long D = 0x10325476L;
//java不支持无符号的基本数据(unsigned),所以选用long数据类型
private long[] result = {
A, B, C, D};
static final long T[][] = {
{
0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821},
{
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a},
{
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665},
{
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391}};
//表示X[k]中的的k取值,决定如何使用消息分组中的字
static final int k[][] = {
{
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15},
{
1, 6, 11, 0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12},
{
5, 8, 11, 14, 1, 4, 7, 10, 13, 0, 3, 6, 9, 12, 15, 2},
{
0, 7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9}};
//各次迭代中采用的做循环移位的s值
static final int S[][] = {
{
7, 12, 17, 22},
{
5, 9, 14, 20},
{
4, 11, 16, 23},
{
6, 10, 15, 21}};
//4轮循环中使用的生成函数(轮函数)g
private static long g(int i, long b, long c, long d) {
switch (i) {
case 0:
return (b & c) | ((~b) & d);
case 1:
return (b & d) | (c & (~d));
case 2:
return b ^ c ^ d;
case 3:
return c ^ (b | (~d));
default:
return 0;
}
}
//开始使用MD5加密
private String start(String message) {
//转化为字节数组
byte[] inputBytes = message.getBytes();
//6A 61 6E 6b 69 6e 67
//获取字节数组的长度
int byteLen = inputBytes.length;
//得到K值(以bit作单位的message长度)
long K = (long) (byteLen << 3);
//完整小组(512bit)(64byte)的个数
int groupCount = byteLen / 64;
//分块
for (int i = 0; i < groupCount; i++) {
//每次取512bit
//处理一个分组
H(divide(inputBytes, i * 64));
}
//填充
int rest = byteLen % 64;
//即将填充的一个分组
byte[] paddingBytes = new byte[64];
//原来的尾部数据
for (int i = 0; i < rest; i++)
paddingBytes[i] = inputBytes[byteLen - rest + i];
//即小于448bit的情况,先填充100...0再填充K值的低64位
//此时只会新增一个分组
if (rest <= 56) {
//填充100...0
if (rest < 56) {
//填充10000000
paddingBytes[rest] = (byte) (1 << 7);
//填充00000000
for (int i = 1; i < 56 - rest; i++)
paddingBytes[rest + i] = 0;
}
//填充K值低64位
for (int i = 0; i < 8; i++) {
paddingBytes[56 + i] = (byte) (K & 0xFFL);
K = K >> 8;
}
//处理分组
H(divide(paddingBytes, 0));
//即大于448bit的情况,先填充100...0再填充K值的低64位
//此时会新增两个分组
} else {
//填充10000000
paddingBytes[rest] = (byte) (1 << 7);
//填充00000000
for (int i = rest + 1; i < 64; i++)
paddingBytes[i] = 0;
//处理第一个尾部分组
H(divide(paddingBytes, 0));
//填充00000000
for (int i = 0; i < 56; i++)
paddingBytes[i] = 0;
//填充低64位
for (int i = 0; i < 8; i++) {
//这里很关键,使用小端方式,即Byte数组先存储len的低位数据,然后右移len
paddingBytes[56 + i] = (byte) (K & 0xFFL);
K = K >> 8;
}
//处理第二个尾部分组
H(divide(paddingBytes, 0));
}
//将Hash值转换成十六进制的字符串
//小端方式!
for (int i = 0; i < 4; i++) {
//解决缺少前置0的问题
resultMessage += String.format("%02x", result[i] & 0xFF) +
String.format("%02x", (result[i] & 0xFF00) >> 8) +
String.format("%02x", (result[i] & 0xFF0000) >> 16) +
String.format("%02x", (result[i] & 0xFF000000) >> 24);
}
return resultMessage;
}
//从inputBytes的index开始取512位,作为新的512bit的分组
private static long[] divide(byte[] inputBytes, int start) {
//存储一整个分组,就是512bit,数组里每个是32bit,就是4字节,为了消除符号位的影响,所以使用long
long[] group = new long[16];
for (int i = 0; i < 16; i++) {
//每个32bit由4个字节拼接而来
//小端的从byte数组到bit恢复方法
group[i] = byte2unsign(inputBytes[4 * i + start]) |
(byte2unsign(inputBytes[4 * i + 1 + start])) << 8 |
(byte2unsign(inputBytes[4 * i + 2 + start])) << 16 |
(byte2unsign(inputBytes[4 * i + 3 + start])) << 24;
}
return group;
}
//其实byte相当于一个字节的有符号整数,这里不需要符号位,所以把符号位去掉
public static long byte2unsign(byte b) {
return b < 0 ? b & 0x7F + 128 : b;
}
// groups[] 中每一个分组512位(64字节)
// MD5压缩函数
private void H(long[] groups) {
//缓冲区(寄存器)数组
long a = result[0], b = result[1], c = result[2], d = result[3];
//四轮循环
for (int n = 0; n < 4; n++) {
//16轮迭代
for (int i = 0; i < 16; i++) {
result[0] += (g(n, result[1], result[2], result[3]) & 0xFFFFFFFFL) + groups[k[n][i]] + T[n][i];
result[0] = result[1] + ((result[0] & 0xFFFFFFFFL) << S[n][i % 4] | ((result[0] & 0xFFFFFFFFL) >>> (32 - S[n][i % 4])));
//循环轮换
long temp = result[3];
result[3] = result[2];
result[2] = result[1];
result[1] = result[0];
result[0] = temp;
}
}
//加入之前计算的结果
result[0] += a;
result[1] += b;
result[2] += c;
result[3] += d;
//防止溢出
for (int n = 0; n < 4; n++) {
result[n] &= 0xFFFFFFFFL;
}
}
public static void main(String[] args) {
MD5 md = new MD5();
String message = "helloMD5";
System.out.println("MD5-Algorithm:\n\nOrigin Message: " + message);
System.out.println("Result Message: " + md.start(message));
System.out.println("Result Message(UpperCase): " + md.resultMessage.toUpperCase());
//Origin Message: helloMD5
//Result Message: 3ed9e5f6855dbcdbcd95ac6c4fe0c0a5
//Result Message(UpperCase): 3ED9E5F6855DBCDBCD95AC6C4FE0C0A5
}
}