Hive的数据存储格式
-
Hive的数据存储基于Hadoop HDFS。
-
Hive没有专门的数据文件格式,常见的有以下几种:TEXTFILE、SEQUENCEFILE、AVRO、RCFILE、ORCFILE、PARQUET。
下面我们详细的看一下Hive的常见数据格式:
- TextFile:
TEXTFILE 即正常的文本格式,是Hive默认文件存储格式,因为大多数情况下源数据文件都是以text文件格式保存(便于查看验数和防止乱码)。此种格式的表文件在HDFS上是明文,可用hadoop fs -cat命令查看,从HDFS上get下来后也可以直接读取。
TEXTFILE 存储文件默认每一行就是一条记录,可以指定任意的分隔符进行字段间的分割。但这个格式无压缩,需要的存储空间很大。 虽然可以结合Gzip、Bzip2、Snappy等使用,使用这种方式,Hive不会对数据进行切分,从而无法对数据进行并行操作。一般只有与其他系统由数据交互的接口表采用TEXTFILE 格式,其他事实表和维度表都不建议使用。
- RCFile:
Record Columnar的缩写。是Hadoop中第一个列文件格式。 能够很好的压缩和快速的查询性能。通常写操作比较慢,比非列形式的文件格式需要更多的内存空间和计算量。 RCFile是一种行列存储相结合的存储方式。 首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
- ORCFile:
Hive从0.11版本开始提供了ORC的文件格式,ORC文件不仅仅是一种列式文件存储格式,最重要的是有着很高的压缩比,并且对于MapReduce来说是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升,因为ORC较其他文件格式压缩比高,查询任务的输入数据量减少,使用的Task也就减少了。ORC能很大程度的节省存储和计算资源,但它在读写时候需要消耗额外的CPU资源来压缩和解压缩,当然这部分的CPU消耗是非常少的。
- Parquet:
通常我们使用关系数据库存储结构化数据,而关系数据库中使用数据模型都是扁平式的,遇到诸如List、Map和自定义Struct的时候就需要用户在应用层解析。但是在大数据环境下,通常数据的来源是服务端的埋点数据,很可能需要把程序中的某些对象内容作为输出的一部分,而每一个对象都可能是嵌套的,所以如果能够原生的支持这种数据,这样在查询的时候就不需要额外的解析便能获得想要的结果。Parquet的灵感来自于2010年Google发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能。Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定。这也是parquet相较于orc的仅有优势:支持嵌套结构。Parquet 没有太多其他可圈可点的地方,比如他不支持update操作(数据写成后不可修改),不支持ACID等.
- SEQUENCEFILE:
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。 这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。 SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。 SequenceFile最重要的优点就是Hadoop原生支持较好,有API,但除此之外平平无奇,实际生产中不会使用。
- AVRO:
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。Avro提供的机制使动态语言可以方便地处理Avro数据。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。
其中的TextFile、RCFile、ORC、Parquet为Hive最常用的四大存储格式
它们的存储效率及执行速度比较如下:
ORCFile存储文件读操作效率最高,耗时比较(ORC<Parquet<RCFile<TextFile)
ORCFile存储文件占用空间少,压缩效率高(ORC<Parquet<RCFile<TextFile)
存储格式实战应用
ods层一般使用的是TextFile原始数据类型
DROP TABLE IF EXISTS ods_activity_info_full;
CREATE EXTERNAL TABLE ods_activity_info_full
(
`id` STRING COMMENT '活动id',
`activity_name` STRING COMMENT '活动名称',
`activity_type` STRING COMMENT '活动类型',
`activity_desc` STRING COMMENT '活动描述',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/mall/ods/ods_activity_info_full/';dim层一般使用的是ORC压缩格式为snappy
DROP TABLE IF EXISTS dim_sku_full;
CREATE EXTERNAL TABLE dim_sku_full
(
`id` STRING COMMENT 'sku_id',
`price` DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'spu编号',
`spu_name` STRING COMMENT 'spu名称',
`category3_id` STRING COMMENT '三级分类id',
`category3_name` STRING COMMENT '三级分类名称',
`category2_id` STRING COMMENT '二级分类id',
`category2_name` STRING COMMENT '二级分类名称',
`category1_id` STRING COMMENT '一级分类id',
`category1_name` STRING COMMENT '一级分类名称',
`tm_id` STRING COMMENT '品牌id',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,value_id :STRING,attr_name :STRING,value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,sale_attr_value_id :STRING,sale_attr_name :STRING,sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC -- ORC 有利于统计分析
LOCATION '/warehouse/mall/dim/dim_sku_full/'
TBLPROPERTIES ('orc.compress' = 'snappy'); -- ORC 提高压缩速度数据加载例子:
insert overwrite table dim_sku_full partition(dt='2020-06-14')
select
sku.id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.is_sale,
sku.spu_id,
spu.spu_name,
sku.category3_id,
c3.name,
c3.category2_id,
c2.name,
c2.category1_id,
c1.name,
sku.tm_id,
tm.tm_name,
attr.attrs,
sale_attr.sale_attrs,
sku.create_time
from sku
dwd层一般使用的是ORC压缩格式为snappy
DROP TABLE IF EXISTS dws_trade_user_payment_1d;
CREATE EXTERNAL TABLE dws_trade_user_payment_1d
(
`user_id` STRING COMMENT '用户id',
`payment_count_1d` BIGINT COMMENT '最近1日支付次数',
`payment_num_1d` BIGINT COMMENT '最近1日支付商品件数',
`payment_amount_1d` DECIMAL(16, 2) COMMENT '最近1日支付金额'
) COMMENT '交易域用户粒度支付最近1日汇总事实表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dws/dws_trade_user_payment_1d'
TBLPROPERTIES ('orc.compress' = 'snappy');ads层一般使用TextFile原始数据类型
DROP TABLE IF EXISTS ads_traffic_stats_by_channel;
CREATE EXTERNAL TABLE ads_traffic_stats_by_channel
(
`dt` STRING COMMENT '统计日期',
`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`channel` STRING COMMENT '渠道',
`uv_count` BIGINT COMMENT '访客人数',
`avg_duration_sec` BIGINT COMMENT '会话平均停留时长,单位为秒',
`avg_page_count` BIGINT COMMENT '会话平均浏览页面数',
`sv_count` BIGINT COMMENT '会话数',
`bounce_rate` DECIMAL(16, 2) COMMENT '跳出率'
) COMMENT '各渠道流量统计'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/ads/ads_traffic_stats_by_channel/';Hive计算框架的更改(Hive on Spark)
(章节的最后有处理兼容性问题源码编译教程,网盘的是兼容已经解决了)
链接:https://pan.baidu.com/s/13wlhd4fh0fVBux8_txAsvg
提取码:yyds
Hive on Spark配置
注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
hive下载官网:
Index of /hive/hive-3.1.2
spark下载官网
Downloads | Apache SparkHive所在节点部署Spark
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz sudo vim /etc/profile.d/my_env.sh# SPARK_HOME
export SPARK_HOME=/home/bigdata/module/spark-3.0.0-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/my_env.sh在hive中创建spark配置文件
vi /home/bigdata/module/hive-3.1.2/conf/spark-defaults.confspark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1ghadoop fs -mkdir /spark-history向HDFS上传Spark纯净版jar包
说明1:由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
解压spark-3.0.0-bin-without-hadoop.tgz
tar -zxvf spark-3.0.0-bin-without-hadoop.tgz上传Spark纯净版jar包到HDFS
hadoop fs -mkdir /spark-jars
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars修改hive-site.xml文件
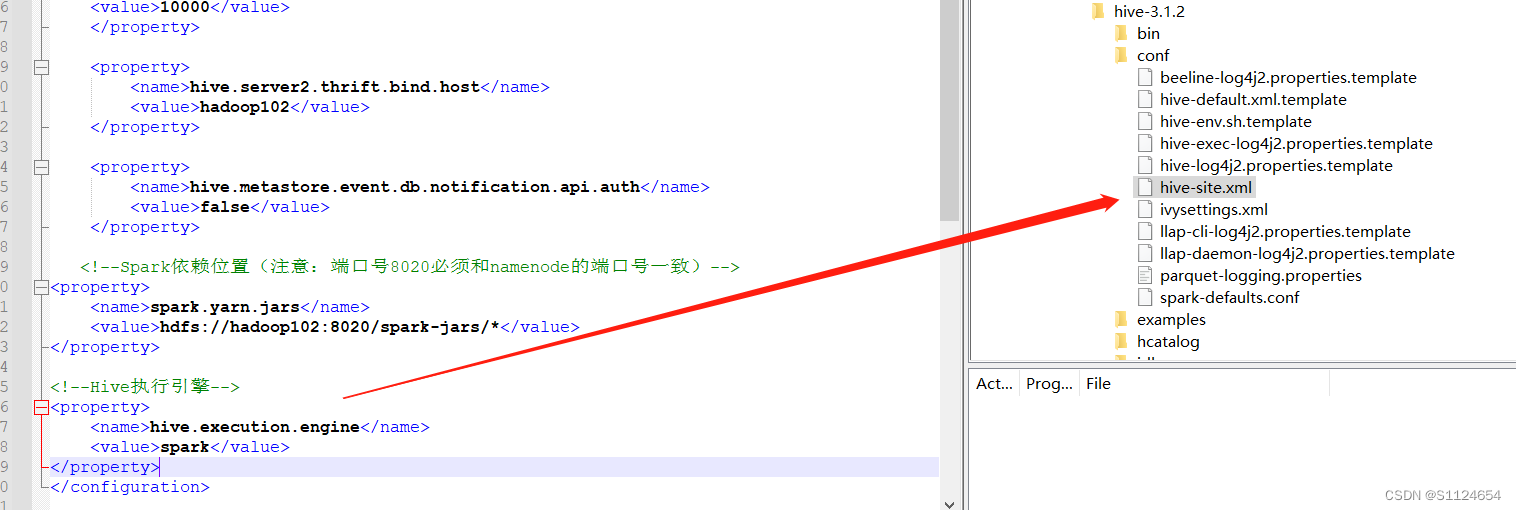
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>Hive on Spark测试
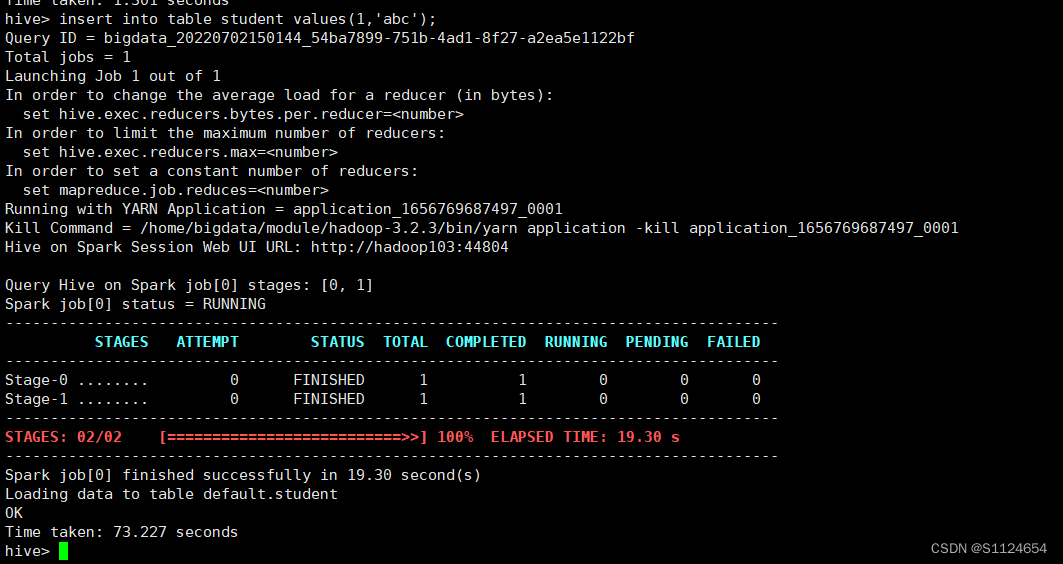
hivecreate table student(id int, name string);insert into table student values(1,'abc');如果出现下图说明配置成功
Yarn环境配置
增加ApplicationMaster资源比例
容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行。
生产环境该参数可使用默认值。但学习环境,集群资源总数很少,如果只分配10%的资源给Application Master,则可能出现,同一时刻只能运行一个Job的情况,因为一个Application Master使用的资源就可能已经达到10%的上限了。故此处可将该值适当调大。
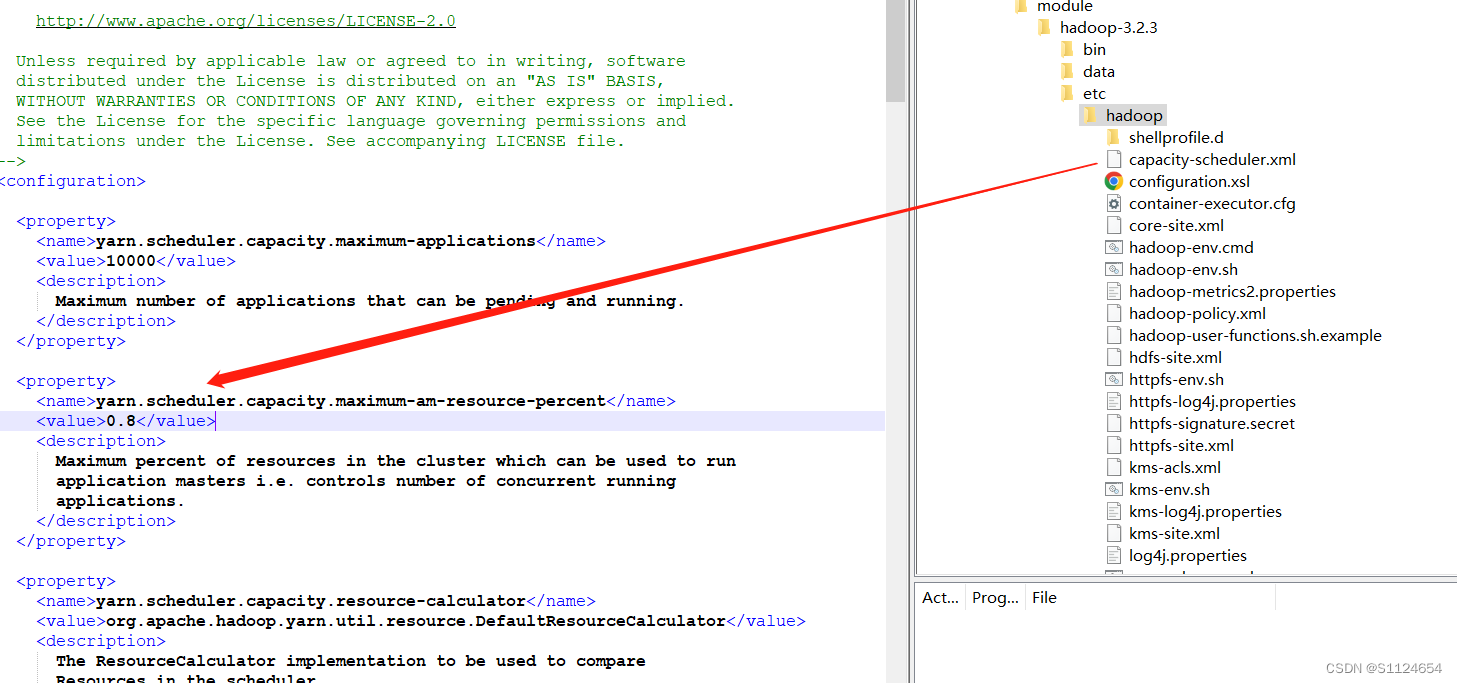
vim capacity-scheduler.xml<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property修改完以后分发配置文件到其他集群,然后重新启动hadoop, ./xsync为自定义的集群分发脚本
在我的shell专栏里面
./xsync /home/bigdata/module/hadoop-3.2.3/etc/hadoop/capacity-scheduler.xml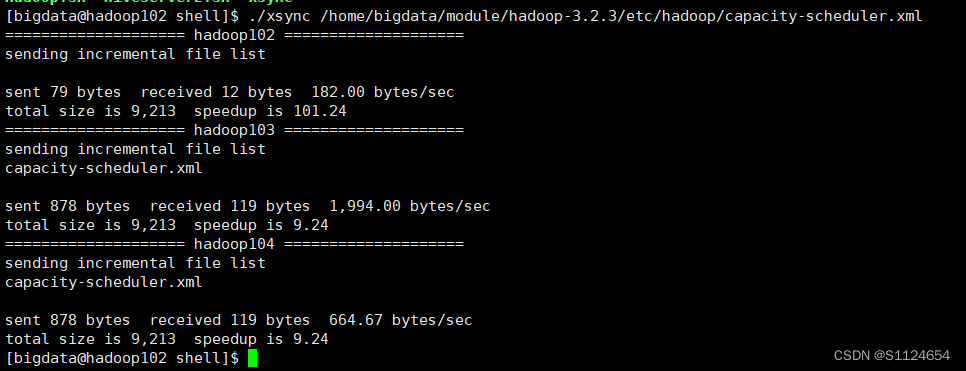
然后重启hadoop就配置完成了
切换成Spark
set hive.execution.engine=spark;切换成MR
set hive.execution.engine=mr;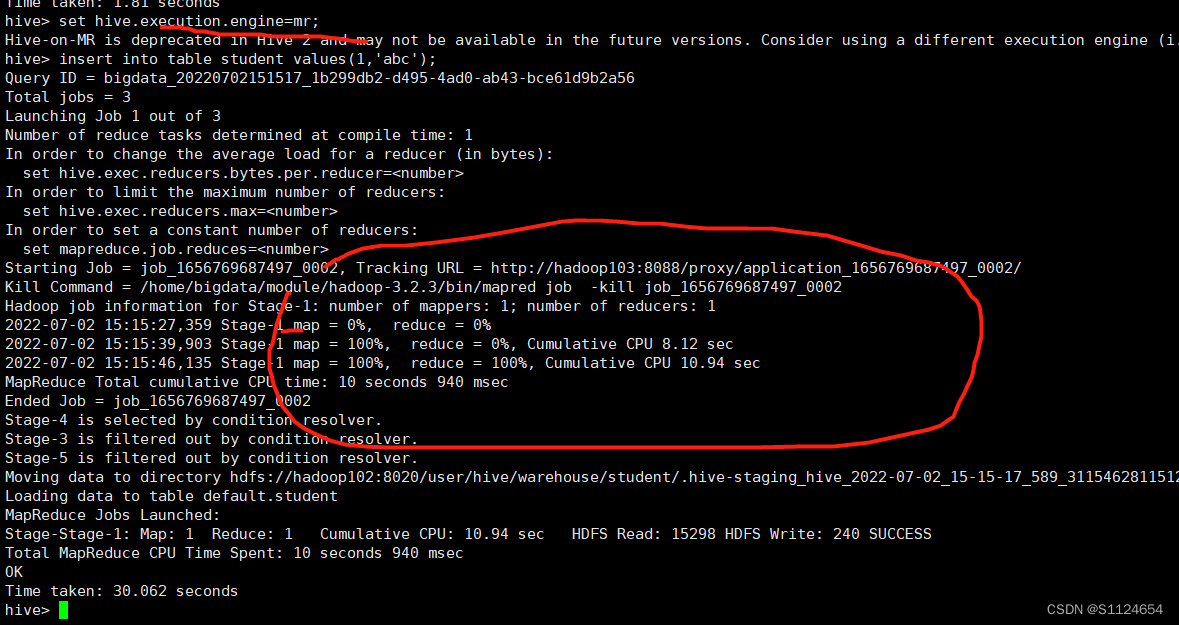
Hive的基本语法
Hive建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
// 定义字段名,字段类型
[(col_name data_type [COMMENT col_comment], ...)]
// 给表加上注解
[COMMENT table_comment]
// 分区
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
// 分桶
[CLUSTERED BY (col_name, col_name, ...)
// 设置排序字段 升序、降序
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[
// 指定设置行、列分隔符
[ROW FORMAT row_format]
// 指定Hive储存格式:textFile、rcFile、SequenceFile 默认为:textFile
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [ WITH SERDEPROPERTIES (...) ] (Note: only available starting with 0.6.0)
]
// 指定储存位置
[LOCATION hdfs_path]
// 跟外部表配合使用,比如:映射HBase表,然后可以使用HQL对hbase数据进行查询,当然速度比较慢
[TBLPROPERTIES (property_name=property_value, ...)] (Note: only available starting with 0.6.0)
[AS select_statement] (Note: this feature is only available starting with 0.5.0.)
建表格式1:全部使用默认建表方式
create table students
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
// 必选,指定列分隔符
建表格式2:指定location (这种方式也比较常用)
create table students2
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input1';
// 指定Hive表的数据的存储位置,一般在数据已经上传到HDFS,想要直接使用,会指定Location,
//通常Locaion会跟外部表一起使用,内部表一般使用默认的location
建表格式3:指定存储格式
create table students3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS rcfile;
// 指定储存格式为rcfile,inputFormat:RCFileInputFormat,outputFormat:RCFileOutputFormat,
//如果不指定,默认为textfile,
//注意:除textfile以外,其他的存储格式的数据都不能直接加载,需要使用从表加载的方式。
建表格式4:create table xxxx as select_statement(SQL语句) (这种方式比较常用)
注:
- 新建表不允许是
外部表。 - select后面表需要是已经存在的表,建表同时会加载数据。
- 会启动mapreduce任务去读取源表数据写入新表
create table students4 as select * from students2;
建表格式5:create table xxxx like table_name 只想建表,不需要加载数据
create table students5 like students;
Hive加载数据
- 使用
hdfs dfs -put '本地数据' 'hive表对应的HDFS目录下' - 使用 load data inpath
从hdfs导入数据,路径可以是目录,会将目录下所有文件导入,但是文件格式必须一致
// 将HDFS上的/input1目录下面的数据 移动至 students表对应的HDFS目录下
// 注意是 移动!移动!移动!
load data inpath '/input1/students.txt' into table students;
// 清空表
truncate table students;
从本地文件系统导入
// 加上 local 关键字 可以将Linux本地目录下的文件 上传到 hive表对应HDFS 目录下 原文件不会被删除
load data local inpath '/usr/local/soft/data/students.txt' into table students;
// overwrite 覆盖加载
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
create table xxx as SQL语句,表对表加载
create table test.aa as select * from test.bb
insert into table xxxx SQL语句 (没有as),表对表加载:
// 将 students表的数据插入到students2
//这是复制 不是移动 students表中的表中的数据不会丢失
insert into table students2 select * from students;
// 覆盖插入 把into 换成 overwrite
insert overwrite table students2 select * from students;
注:
1,如果建表语句没有指定存储路径,不管是外部表还是内部表,存储路径都是会默认在hive/warehouse/xx.db/表名的目录下。
加载的数据如果在HDFS上会移动到该表的存储目录下。注意是移动,不是复制
2,删除外部表,文件不会删除,对应目录也不会删除
Hive 内部表(Managed tables)vs 外部表(External tables)
外部表和普通表的区别
- 外部表的路径可以自定义,内部表的路径需要在 hive/warehouse/目录下
- 删除表后,普通表数据文件和表信息都删除。外部表仅删除表信息
建表语句:
// 内部表
create table students_internal
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input2';
// 外部表
create external table students_external
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input3';
加载数据:
hive> dfs -put /usr/local/soft/data/students.txt /input2/;
hive> dfs -put /usr/local/soft/data/students.txt /input3/;
删除表:
hive> drop table students_internal;
Moved: 'hdfs://master:9000/input2' to trash at: hdfs://master:9000/user/root/.Trash/Current
OK
Time taken: 0.474 seconds
hive> drop table students_external;
OK
Time taken: 0.09 seconds
1、可以看出,删除内部表的时候,表中的数据(HDFS上的文件)会被同表的元数据一起删除;删除外部表的时候,只会删除表的元数据,而不会删除表中的数据(HDFS上的文件)
2、一般在公司中,使用外部表多一点,因为数据可以需要被多个程序使用,避免误删,通常外部表会结合location一起使用
3、外部表还可以将其他数据源中的数据 映射到 hive中,比如说:hbase,ElasticSearch…
4、设计外部表的初衷就是 让 表的元数据 与 数据 解耦
Hive 分区
分区表实际上是在表的目录下在以分区命名,建子目录;作用:进行分区裁剪,避免全表扫描,减少MapReduce处理的数据量,提高效率
一般在公司的hive中,所有的表基本上都是分区表,通常按日期分区、地域分区;分区表在使用的时候记得加上分区字段;分区也不是越多越好,一般不超过3级,根据实际业务衡量
分区的概念和分区表:
分区表指的是在创建表时指定分区空间,实际上就是在hdfs上表的目录下再创建子目录。
在使用数据时如果指定了需要访问的分区名称,则只会读取相应的分区,避免全表扫描,提高查询效率。
建立分区表:
create external table students_pt1
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(pt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
增加一个分区:
alter table students_pt1 add partition(pt='20210904');
删除一个分区:
alter table students_pt drop partition(pt='20210904');
查看某个表的所有分区
// 推荐这种方式(直接从元数据中获取分区信息)
show partitions students_pt;
// 不推荐
select distinct pt from students_pt;
往分区中插入数据:
insert into table students_pt partition(pt='20210902') select * from students;
load data local inpath '/usr/local/soft/data/students.txt' into table students_pt partition(pt='20210902');
查询某个分区的数据:
// 全表扫描,不推荐,效率低
select count(*) from students_pt;
// 使用where条件进行分区裁剪,避免了全表扫描,效率高
select count(*) from students_pt where pt='20210101';
// 也可以在where条件中使用非等值判断
select count(*) from students_pt where pt<='20210112' and pt>='20210110';
Hive动态分区
有的时候我们原始表中的数据里面包含了 ‘‘日期字段 dt’’,我们需要根据dt中不同的日期,分为不同的分区,将原始表改造成分区表。
hive默认不开启动态分区动态分区:根据数据中某几列的不同的取值 划分 不同的分区
# 表示开启动态分区
hive> set hive.exec.dynamic.partition=true;
# 表示动态分区模式:strict(需要配合静态分区一起使用)、nostrict
# strict: insert into table students_pt partition(dt='anhui',pt) select ......,pt from students;
hive> set hive.exec.dynamic.partition.mode=nostrict;
# 表示支持的最大的分区数量为1000,可以根据业务自己调整
hive> set hive.exec.max.dynamic.partitions.pernode=1000;
建立原始表并加载数据
create table students_dt
(
id bigint,
name string,
age int,
gender string,
clazz string,
dt string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
建立分区表并加载数据
create table students_dt_p
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
使用动态分区插入数据
// 分区字段需要放在 select 的最后,如果有多个分区字段 同理,
//它是按位置匹配,不是按名字匹配
insert into table students_dt_p partition(dt) select id,name,age,gender,clazz,dt from students_dt;
// 比如下面这条语句会使用age作为分区字段,而不会使用student_dt中的dt作为分区字段
insert into table students_dt_p partition(dt) select id,name,age,gender,dt,age from students_dt;
多级分区
create table students_year_month
(
id bigint,
name string,
age int,
gender string,
clazz string,
year string,
month string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
create table students_year_month_pt
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(year string,month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into table students_year_month_pt partition(year,month) select id,name,age,gender,clazz,year,month from students_year_month;
Hive分桶
分桶实际上是对文件(数据)的进一步切分;Hive默认关闭分桶;分桶的作用:在往分桶表中插入数据的时候,会根据 clustered by 指定的字段 进行hash分组 对指定的buckets个数 进行取余,进而可以将数据分割成buckets个数个文件,以达到数据均匀分布,可以解决Map端的“数据倾斜”问题,方便我们取抽样数据,提高Map join效率;分桶字段 需要根据业务进行设定
开启分桶开关
hive> set hive.enforce.bucketing=true;
建立分桶表
create table students_buks
(
id bigint,
name string,
age int,
gender string,
clazz string
)
CLUSTERED BY (clazz) into 12 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
往分桶表中插入数据
// 直接使用load data 并不能将数据打散
load data local inpath '/usr/local/soft/data/students.txt' into table students_buks;
// 需要使用下面这种方式插入数据,才能使分桶表真正发挥作用
insert into students_buks select * from students;
Hive连接JDBC
启动hiveserver2的服务(看过我上一个阶段的小伙伴可以使用脚本操作超级方便)
hive --service hiveserver2 &
新建maven项目并添加两个依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
编写Java通过JDBC连接Hive
import java.sql.*;
public class HiveJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn = DriverManager.getConnection("jdbc:hive2://master:10000/test3");
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery("select * from students limit 10");
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
int age = rs.getInt(3);
String gender = rs.getString(4);
String clazz = rs.getString(5);
System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
}
rs.close();
stat.close();
conn.close();
}
}
Hive的数据类型
基本数据类型
数值型:
TINYINT — 微整型,只占用1个字节,只能存储0-255的整数。
SMALLINT– 小整型,占用2个字节,存储范围–32768 到 32767。
INT– 整型,占用4个字节,存储范围-2147483648到2147483647。
BIGINT– 长整型,占用8个字节,存储范围-2^63到2^63-1。
布尔型
BOOLEAN — TRUE/FALSE
浮点型
FLOAT– 单精度浮点数。
DOUBLE– 双精度浮点数。
字符串型
STRING– 不设定长度。
日期类型
- 时间戳 timestamp
- 日期 date
create table testDate(
ts timestamp
,dt date
) row format delimited fields terminated by ',';
// 2021-01-14 14:24:57.200,2021-01-11
- 时间戳与时间字符串转换
// from_unixtime 传入一个时间戳以及pattern(yyyy-MM-dd)
//可以将 时间戳转换成对应格式的字符串
select from_unixtime(1630915221,'yyyy年MM月dd日 HH时mm分ss秒')
// unix_timestamp 传入一个时间字符串以及pattern,
//可以将字符串按照pattern转换成时间戳
select unix_timestamp('2021年09月07日 11时00分21秒','yyyy年MM月dd日 HH时mm分ss秒');
select unix_timestamp('2021-01-14 14:24:57.200')
复杂数据类型
主要有三种复杂数据类型:Structs,Maps,Arrays
Hive HQL使用语法
我们知道SQL语言可以分为5大类:
(1)DDL(Data Definition Language) 数据定义语言
用来定义数据库对象:数据库,表,列等。
关键字:create,drap,alter等
( 2)DML(Data Manipulation Language) 数据操作语言
用来对数据库中表的数据进行增删改。
关键字:insert,delete,update等
( 3)DQL(Data Query Language)数据查询语言
用来查询数据库表的记录(数据)。
关键字:select,where 等
( 4)DCL(Data Control Language) 数据控制语言
用来定义数据库的访问权限和安全级别,及创建用户。
关键字:GRANT,REVOKE等
(5)TCL(Transaction Control Language) 事务控制语言
T CL经常被用于快速原型开发、脚本编程、GUI和测试等方面,
关键字: commit、rollback等。
HQL语法-DDL
创建数据库 create database xxxxx;
查看数据库 show databases;
删除数据库 drop database tmp;
强制删除数据库:drop database tmp cascade;
查看表:SHOW TABLES;
查看表的元信息:
desc test_table;
describe extended test_table;
describe formatted test_table;
查看建表语句:show create table table_XXX
重命名表:
alter table test_table rename to new_table;
修改列数据类型:alter table lv_test change column colxx string;
增加、删除分区:
alter table test_table add partition (pt=xxxx)
alter table test_table drop if exists partition(...);
HQL语法-DML
where 用于过滤,分区裁剪,指定条件
join 用于两表关联,left outer join ,join,mapjoin(1.2版本后默认开启)
group by 用于分组聚合,通常结合聚合函数一起使用
order by 用于全局排序,要尽量避免排序,是针对全局排序的,即对所有的reduce输出是有序的
sort by :当有多个reduce时,只能保证单个reduce输出有序,不能保证全局有序
cluster by = distribute by + sort by
distinct 去重
Hive HQL使用注意
- count(1)、count(*)和count(字段名)执行效果上的区别
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
- HQL 执行优先级:
from、where、 group by 、having、order by、join、select 、limit - where 条件里不支持不等式子查询,实际上是支持 in、not in、exists、not exists
- hive中大小写不敏感
- 在hive中,数据中如果有null字符串,加载到表中的时候会变成 null (不是字符串)
如果需要判断 null,使用 某个字段名 is null 这样的方式来判断;或者使用 nvl() 函数,不能 直接 某个字段名 == null - 使用explain查看SQL执行计划
Hive 的函数使用
Hive-常用函数
关系运算
// 等值比较 = == <=>
// 不等值比较 != <>
// 区间比较: select * from default.students where id between 1500100001 and 1500100010;
// 空值/非空值判断:is null、is not null、nvl()、isnull()
// like、rlike、regexp用法数值计算
取整函数(四舍五入):round
向上取整:ceil
向下取整:floor
条件函数
if(表达式,如果表达式成立的返回值,如果表达式不成立的返回值)
select if(1>0,1,0);
select if(1>0,if(-1>0,-1,1),0);
COALESCE
select COALESCE(null,'1','2'); // 1 从左往右 一次匹配 直到非空为止
select COALESCE('1',null,'2'); // 1
case when … then … else … end
select score
,case when score>120 then '优秀'
when score>100 then '良好'
when score>90 then '及格'
else '不及格'
end as pingfen
from default.score limit 20;
# 注意条件的顺序
日期函数
select from_unixtime(1610611142,'YYYY/MM/dd HH:mm:ss');
select from_unixtime(unix_timestamp(),'YYYY/MM/dd HH:mm:ss');
// '2021年01月14日' -> '2021-01-14'
select from_unixtime(unix_timestamp('2021年01月14日','yyyy年MM月dd日'),'yyyy-MM-dd');
// "04牛2021数加16逼" -> "2021/04/16"
select from_unixtime(unix_timestamp("04牛2021数加16逼","MM牛yyyy数加dd逼"),"yyyy/MM/dd");
字符串函数
concat('123','456'); // 123456
concat('123','456',null); // NULL
select concat_ws('#','a','b','c'); // a#b#c
select concat_ws('#','a','b','c',NULL); // a#b#c 可以指定分隔符,并且会自动忽略NULL
select concat_ws("|",cast(id as string),name,cast(age as string),gender,clazz) from students limit 10;
select substring("abcdefg",1); // abcdefg HQL中涉及到位置的时候 是从1开始计数
// '2021/01/14' -> '2021-01-14'
select concat_ws("-",substring('2021/01/14',1,4),substring('2021/01/14',6,2),substring('2021/01/14',9,2));
select split("abcde,fgh",","); // ["abcde","fgh"]
select split("a,b,c,d,e,f",",")[2]; // c
select explode(split("abcde,fgh",",")); // abcde
// fgh
// 解析json格式的数据
select get_json_object('{"name":"zhangsan","age":18,"score":[{"course_name":"math","score":100},{"course_name":"english","score":60}]}',"$.score[0].score"); // 100
Hive-高级函数
窗口函数(开窗函数):用户分组中开窗
在sql中有一类函数叫做`聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时我们便引入了窗口函数。(开创函数,我们一般用于分组中求 TopN问题)
样例演示:
数据:
111,69,class1,department1
112,80,class1,department1
113,74,class1,department1
114,94,class1,department1
115,93,class1,department1
121,74,class2,department1
122,86,class2,department1
123,78,class2,department1
124,70,class2,department1
211,93,class1,department2
212,83,class1,department2
213,94,class1,department2
214,94,class1,department2
215,82,class1,department2
216,74,class1,department2
221,99,class2,department2
222,78,class2,department2
223,74,class2,department2
224,80,class2,department2
225,85,class2,department2
建表:
create table new_score(
id int
,score int
,clazz string
,department string
) row format delimited fields terminated by ",";
窗口函数入门到精通图解之前我写过了传送门,大家可以使用这个数据,然后根据图解就能举一反三了
hive-窗口函数入门到精通_S1124654的博客-CSDN博客
Hive 行转列
使用关键字: lateral view explode
样例演示:
建表:
create table testArray2(
name string,
weight array<string>
)row format delimited
fields terminated by '\t'
COLLECTION ITEMS terminated by ',';
样例数据:
孙悟空 "150","170","180"
唐三藏 "150","180","190"

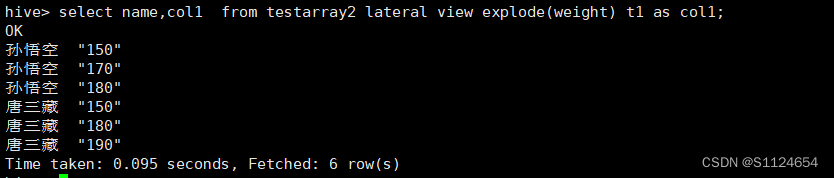
select name,col1 from testarray2 lateral view explode(weight) t1 as col1;
select key from (select explode(map('key1',1,'key2',2,'key3',3)) as (key,value)) t;

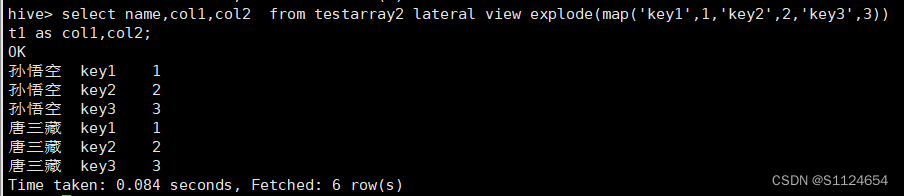
select name,col1,col2 from testarray2 lateral view explode(map('key1',1,'key2',2,'key3',3)) t1 as col1,col2;
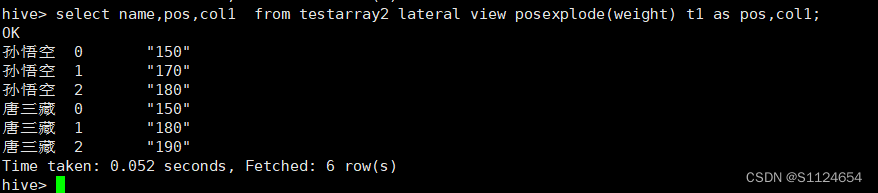
select name,pos,col1 from testarray2 lateral view posexplode(weight) t1 as pos,col1;
Hive 列转行
数据:
孙悟空 150
孙悟空 170
孙悟空 180
唐三藏 150
唐三藏 180
唐三藏 190
建表:
create table testLieToLine(
name string,
col1 int
)row format delimited
fields terminated by '\t';
测试:
select name,collect_list(col1) from testLieToLine group by name;

Hive自定义函数UserDefineFunction
UDF:一进一出
- 创建maven项目,并加入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
- 编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
import org.apache.hadoop.hive.ql.exec.UDF;
public class HiveUDF extends UDF {
// hadoop => #hadoop$
public String evaluate(String col1) {
// 给传进来的数据 左边加上 # 号 右边加上 $
String result = "#" + col1 + "$";
return result;
}
}
- 打成jar包并上传至Linux虚拟机(/usr/local/soft/jars/)
- 在hive shell中,使用
add jar路径将jar包作为资源添加到hive环境中
add jar /usr/local/soft/jars/HiveUDF2-1.0.jar;
- 使用jar包资源注册一个临时函数,fxxx1是你的函数名,’MyUDF’是主类名
create temporary function fxxx1 as 'MyUDF';
- 使用函数名处理数据
select fxx1(name) as fxx_name from students limit 10;
#施笑槐$
#吕金鹏$
#单乐蕊$
#葛德曜$
#宣谷芹$
#边昂雄$
#尚孤风$
#符半双$
#沈德昌$
#羿彦昌$
UDTF:一进多出
样例数据:
"key1:value1,key2:value2,key3:value3"
key1 value1
key2 value2
key3 value3
方法一:使用 explode+split
select split(t.col1,":")[0],split(t.col1,":")[1]
from (select
explode(split("key1:value1,key2:value2,key3:value3",",")) as
col1) t;
自定UDTF
//自定义代码
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class HiveUDTF extends GenericUDTF {
// 指定输出的列名 及 类型
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
ArrayList<String> filedNames = new ArrayList<String>();
ArrayList<ObjectInspector> filedObj = new ArrayList<ObjectInspector>();
filedNames.add("col1");
filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
filedNames.add("col2");
filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(filedNames, filedObj);
}
// 处理逻辑 my_udtf(col1,col2,col3)
// "key1:value1,key2:value2,key3:value3"
// my_udtf("key1:value1,key2:value2,key3:value3")
public void process(Object[] objects) throws HiveException {
// objects 表示传入的N列
String col = objects[0].toString();
// key1:value1 key2:value2 key3:value3
String[] splits = col.split(",");
for (String str : splits) {
String[] cols = str.split(":");
// 将数据输出
forward(cols);
}
}
// 在UDTF结束时调用
public void close() throws HiveException {
}
}
SQL:
select my_udtf("key1:value1,key2:value2,key3:value3");
举例说明:
字段:id,col1,col2,col3,col4,col5,col6,col7,col8,col9,col10,col11,col12
共13列
数据:
a,1,2,3,4,5,6,7,8,9,10,11,12
b,11,12,13,14,15,16,17,18,19,20,21,22
c,21,22,23,24,25,26,27,28,29,30,31,32
转成3列:id,hours,value
例如:
a,1,2,3,4,5,6,7,8,9,10,11,12
a,0时,1
a,2时,2
a,4时,3
a,6时,4建表:
create table udtfData(
id string
,col1 string
,col2 string
,col3 string
,col4 string
,col5 string
,col6 string
,col7 string
,col8 string
,col9 string
,col10 string
,col11 string
,col12 string
)row format delimited fields terminated by ',';
java代码:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class HiveUDTF2 extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
ArrayList<String> filedNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldObj = new ArrayList<ObjectInspector>();
filedNames.add("col1");
fieldObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
filedNames.add("col2");
fieldObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(filedNames, fieldObj);
}
public void process(Object[] objects) throws HiveException {
int hours = 0;
for (Object obj : objects) {
hours = hours + 1;
String col = obj.toString();
ArrayList<String> cols = new ArrayList<String>();
cols.add(hours + "时");
cols.add(col);
forward(cols);
}
}
public void close() throws HiveException {
}
}
添加jar资源:
add jar /usr/local/soft/HiveUDF2-1.0.jar;
注册udtf函数:
create temporary function my_udtf as 'MyUDTF';
SQL:
select id
,hours
,value from udtfData lateral view
my_udtf(col1,col2,col3,col4,col5,col6,col7,col8,col9,col10,col11,col12)
t as hours,value ;
UDAF:多进一出
Hive 中的wordCount
建表:
create table words(
words string
)row format delimited fields terminated by '|';
数据:
hello,java,hello,java,scala,python
hbase,hadoop,hadoop,hdfs,hive,hive
hbase,hadoop,hadoop,hdfs,hive,hive

select word,count(*) from (select explode(split(words,',')) word from words) a group by a.word;
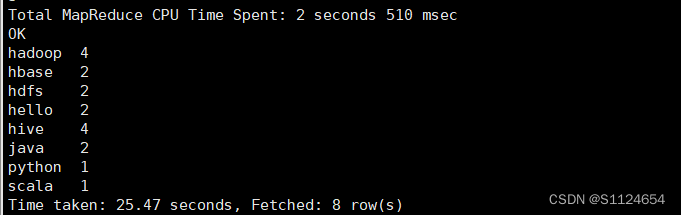
Hive 的Shell使用
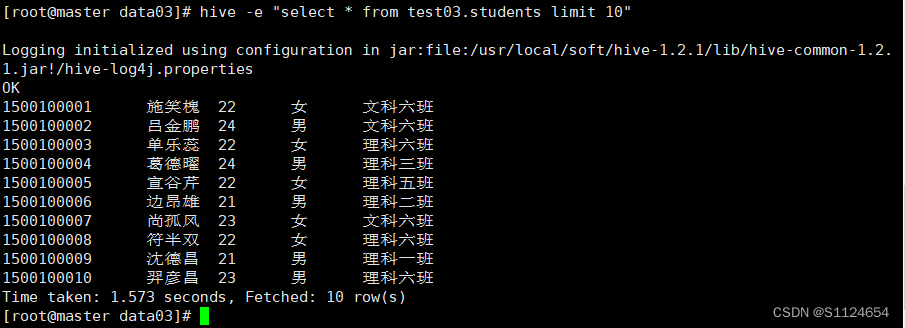
第一种shell
hive -e "select * from test03.students limit 10"
第二种shell
hive -f hql文件路径
# 将HQL写在一个文件里,再使用 -f 参数指定该文件
源码编译
意义:
如果在使用新版本的时候如果有版本不兼容的问题的时候我们就可以自己编译出能够兼容的版本
hive在linux环境编译比较方便
- 先下载源码
- 配置linux的maven环境
修改maven的镜像
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<!-- <url>https://repo1.maven.org/maven2/</url> -->
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring插件仓库</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror>
<id>repo2</id>
<name>Mirror from Maven Repo2</name>
<url>https://repo.spring.io/plugins-release/</url>
<mirrorOf>central</mirrorOf>
</mirror>
在不修改的情况先编译一遍
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
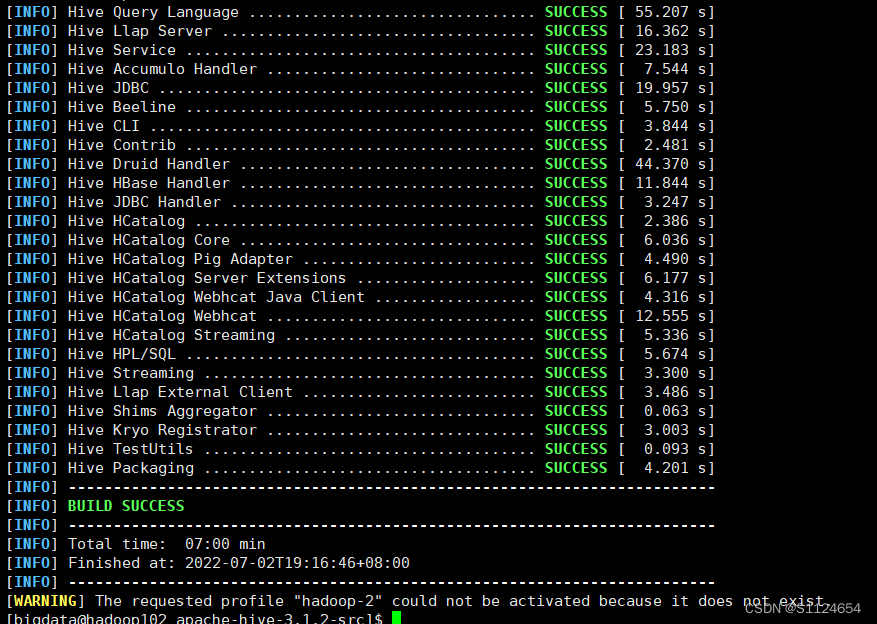
提升spark版本使得新版本的hive兼容spark3.0.0
参考github提交的代码进行修改
Commits · gitlbo/hive · GitHub
参考下面比较全的文章,然后加上自己知道的,希望能帮助到大家