MySQL – 死锁的产生及解决方案
- 1. 死锁与产生死锁的四个必要条件
-
- 1.1 什么是死锁
- 1.2 死锁产生的4个必要条件
- 2. 死锁案例
-
- 2.1 表锁死锁
- 2.2 行锁死锁
- 2.3 共享锁转换为排他锁
- 3. 死锁排查
- 4. 实例分析
-
- 4.1 案例描述
- 4.2 案例死锁问题复现
- 4.3 死锁排查
- 4.4 解决死锁
- 5. 如何避免死锁
1. 死锁与产生死锁的四个必要条件
1.1 什么是死锁
死锁是指2+的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
摘自:@百度百科
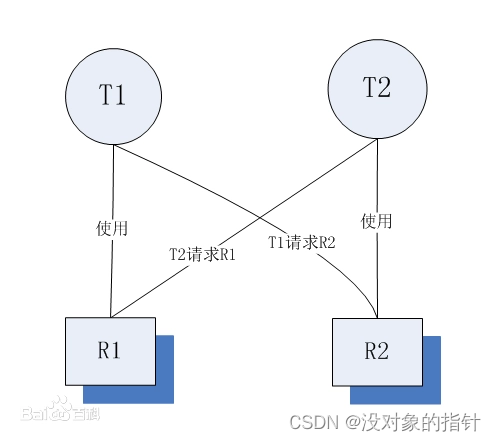
1.2 死锁产生的4个必要条件
虽然进程在运行过程中,可能发生死锁,但死锁的发生也必须具备一定的条件,死锁的发生必须具备以下四个必要条件:
1)互斥条件: 指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
2)请求和保持条件: 指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
3)不剥夺条件: 指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
4)环路等待条件: 指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
我们强调所有四个条件必须同时成立才会出现死锁。环路等待条件意味着占有并等待条件,这样四个条件并不完全独立。
死锁的关键在于:2+ 的 session 加锁的顺序不一致。
那么对应的解决死锁问题的关键就是:让不同的 session 加锁有次序。
2. 死锁案例
2.1 表锁死锁
- 产生原因:
用户A访问表A(锁住了表A),然后又访问表B;另一个用户B访问表B(锁住了表B),然后企图访问表A;这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B才能继续,同样用户B要等用户A释放表A才能继续,这就死锁就产生了。
用户A–》A表(表锁)–》B表(表锁)
用户B–》B表(表锁)–》A表(表锁)
- 解决方案:
这种死锁比较常见,是由于程序的 BUG 产生的,除了调整的程序的逻辑没有其它的办法。仔细分析程序的逻辑,对于数据库的多表操作时,尽量按照相同的顺序进行处理,尽量避免同时锁定两个资源,如操作A和B两张表时,总是按先A后B的顺序处理, 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源。
2.2 行锁死锁
- 产生原因1:
如果在事务中执行了一条没有索引条件的查询,引发全表扫描,把行级锁上升为全表记录锁定(等价于表级锁),多个这样的事务执行后,就很容易产生死锁和阻塞,最终应用系统会越来越慢,发生阻塞或死锁。
- 解决方案1:
SQL 语句中不要使用太复杂的关联多表的查询;使用 explain “执行计划”对 SQL 语句进行分析,对于有全表扫描和全表锁定的 SQL 语句,建立相应的索引进行优化。
- 产生原因2:
两个事务分别想拿到对方持有的锁,互相等待,于是产生死锁。

- 解决方案2:
(1)在同一个事务中,尽可能做到一次锁定所需要的所有资源;
(2)按照 id 对资源排序,然后按顺序进行处理。
2.3 共享锁转换为排他锁
- 产生原因:
事务A 查询一条纪录,然后更新该条纪录;此时事务B 也更新该条纪录,这时事务B 的排他锁由于事务A 有共享锁,必须等A 释放共享锁后才可以获取,只能排队等待。事务A 再执行更新操作时,此处发生死锁,因为事务A 需要排他锁来做更新操作。但是,无法授予该锁请求,因为事务B 已经有一个排他锁请求,并且正在等待事务A 释放其共享锁。
事务A:
-- 共享锁,1
select * from dept where deptno=1 lock in share mode;
-- 排他锁,3
update dept set dname='java' where deptno=1;
事务B:
-- 由于1有共享锁,没法获取排他锁,需等待,2
update dept set dname='Java' where deptno=1;
- 解决方案:
(1)对于按钮等控件,点击立刻失效,不让用户重复点击,避免引发同时对同一条记录多次操作;
(2)使用乐观锁进行控制。乐观锁机制避免了长事务中的数据库加锁开销,大大提升了大并发量下的系统性能。需要注意的是,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。
3. 死锁排查
MySQL 提供了几个与锁有关的参数和命令,可以辅助我们优化锁操作,减少死锁发生。
- 查看死锁日志:
通过 show engine innodb status \G 命令查看近期死锁日志信息,主要关注日志中的 LATEST DETECTED DEADLOCK 部分;
使用方法:
(1)查看近期死锁日志信息;
(2)使用 explain 查看下 SQL 执行计划。
- 查看锁状态变量
通过 show status like 'innodb_row_lock%' 命令检查状态变量,分析系统中的行锁的争夺情况
- Innodb_row_lock_current_waits:当前正在等待锁的数量
- Innodb_row_lock_time:从系统启动到现在锁定总时间长度
- Innodb_row_lock_time_avg: 每次等待锁的平均时间
- Innodb_row_lock_time_max:从系统启动到现在等待最长的一次锁的时间
- Innodb_row_lock_waits:系统启动后到现在总共等待的次数
如果等待次数高,而且每次等待时间长,需要分析系统中为什么会有如此多的等待,然后着手定制优化。
4. 实例分析
4.1 案例描述
本次发生死锁的是库存扣减接口,该接口的主要逻辑是用户下单后,扣减订单商品在某个仓库的库存量。比如用户一个在vivo官网下单买了1台X50手机和1台X30耳机,那么下单后,首先根据用户收货地址确定发货仓库,然后从该仓库里面分别减去一个X50库存和一个X30库存。分析死锁sql之前,先看下商品库存表的定义(为方便理解,只保留主要字段):
CREATE TABLE `store` (
`id` int(10) AUTO_INCREMENT COMMENT '主键',
`sku_code` varchar(45) COMMENT '商品编码',
`ws_code` varchar(32) COMMENT '仓库编码',
`store` int(10) COMMENT '库存量',
PRIMARY KEY (`id`),
KEY `idx_skucode` (`sku_code`),
KEY `idx_wscode` (`ws_code`)
) ENGINE=InnoDB COMMENT='商品库存表'
注意这里分别给 sku_code 和 ws_code 两个字段单独定义了索引:idx_skucode,idx_wscode。这样做的原因主要是业务上有根据单个字段查询的要求。
4.2 案例死锁问题复现
再看下库存扣减update语句:
update store
set store = store-#{store}
where sku_cod e= #{skuCode} and ws_code = #{wsCode} and (store-#{store}) >= 0;
这个 SQL 的业务含义就是对某个商品(skuCode)从某个仓库(wsCode)中扣减 store 个库存量,同时上面的 where 条件同时出现了 sku_code 和 ws_code 字段,压测数据中 sku_code 的选择度要比 ws_code 高,理论上这条 SQL 应该会走 idx_skucode 索引,那么真实情况是怎样的呢?
好,接下来对库存扣减接口卡进行压测,50的并发,每个订单5个商品,刚压不到半分钟就出现了死锁,再压,问题依旧,说明是必现的问题,必现解决后才能继续。
4.3 死锁排查
通过 show engine innodb status \G 命令查看近期死锁日志信息,主要关注日志中的 LATEST DETECTED DEADLOCK 部分:
-----------------------
LATEST DETECTED DEADLOCK
------------------------
2020-xx-xx 21:09:05 7f9b22008700
*** (1) TRANSACTION:
TRANSACTION 4219870943, ACTIVE 0 sec fetching rows
mysql tables in use 3, locked 3
LOCK WAIT 10 lock struct(s), heap size 2936, 3 row lock(s)
MySQL thread id 301903552, OS thread handle 0x7f9b21a7b700, query id 5373393954 10.101.22.135 root updating
update store
set update_time = now(), store = store-1
where sku_code='5468754' and ws_code = 'NO_001' and (store-1) >= 0
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3331 page no 16 n bits 904 index `idx_wscode` of table `store` trx id 4219870943 lock_mode X locks rec but not gap waiting
Record lock, heap no 415 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 5; hex 5730303735; asc NO_001;;
1: len 8; hex 00000000000025a7; asc % ;;
*** (2) TRANSACTION:
TRANSACTION 4219870941, ACTIVE 0 sec fetching rows, thread declared inside InnoDB 1
mysql tables in use 3, locked 3
9 lock struct(s), heap size 2936, 4 row lock(s)
MySQL thread id 301939956, OS thread handle 0x7f9b22008700, query id 5373393941 10.101.22.135 root updating
update store
set update_time = now(), store = store-1
where sku_code='5655620' and ws_code = 'NO_001' and (store-1) >= 0
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 3331 page no 16 n bits 904 index `idx_wscode` of table `store` trx id 4219870941 lock_mode X locks rec but not gap
Record lock, heap no 415 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 5; hex 5730303735; asc NO_001;;
1: len 8; hex 00000000000025a7; asc % ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3331 page no 7 n bits 328 index `PRIMARY` of table `store` trx id 4219870941 lock_mode X locks rec but not gap waiting
Record lock, heap no 72 PHYSICAL RECORD: n_fields 9; compact format; info bits 0
0: len 8; hex 00000000000025a7; asc % ;;
1: len 6; hex 0000fb85fdf7; asc ;;
2: len 7; hex 1a00001d3b21d4; asc ;! ;;
3: len 7; hex 35343638373534; asc 5468754;;
4: len 5; hex 5730303735; asc NO_001;;
5: len 8; hex 8000000000018690; asc ;;
6: len 5; hex 99a76b2b97; asc k+ ;;
7: len 5; hex 99a7e35244; asc RD;;
8: len 1; hex 01; asc ;;
从上面日志可以看出,存在两个事务,分别在执行这两条sql时发生了死锁:
update store set update_time = now(), store = store-1 where sku_code='5468754' and ws_code = 'NO_001' and (store-1) >= 0;
update store set update_time = now(), store = store-1 where sku_code='5655620' and ws_code = 'NO_001' and (store-1) >= 0;
看一下实际数据:
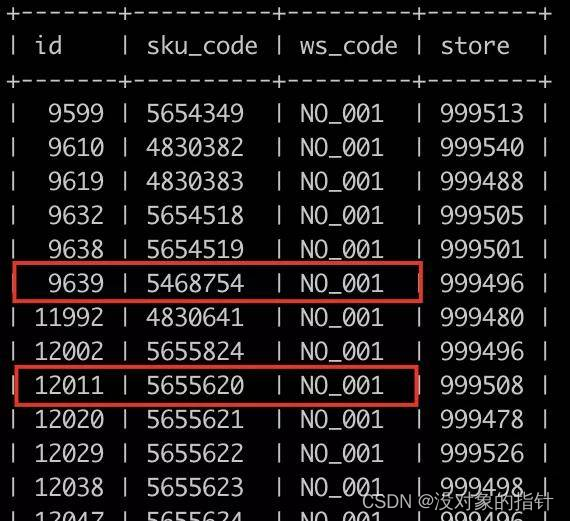
就是说,这两个事务在更新同一张表的不同行时发生了死锁。在我们直观印象里,innodb使用的是行锁,不同的行锁之间应该是互不干扰的?那这是怎么一回事呢?
和我们想象的不同,InnoDB 既没有使用 idx_skucode 索引,也没有使用 idx_wscode 索引,而是使用了 index_merge。index_merge 和这两个索引是什么关系呢?
查询资料得知 index_merge 是 MySQL 5.1 后引入的一项索引合并优化技术,它允许对同一个表同时使用多个索引进行查询,并对多个索引的查询结果进行合并(取交集(intersect)、并集(union)等)后返回。
回到上面的 update 语句:where sku_code='5468754' and ws_code = 'NO_001' ;如果没有 index_merge,要么走 idx_skucode 索引,要么走 idx_wscode 索引,不会出现两个索引一起使用的情况。而在使用 index_merge 技术后,会同时执行两个索引,分别查到结果后再进行合并(where条件是and,所以会做交集运算)。再结合第二部分对加锁机制(分步按记录加锁)的理解,是否隐约觉得两个索引的同时加锁是导致死锁的原因呢?
我们再深入死锁日志看一下,日志比较复杂,翻译过来大意如下:
- 事务一 4219870943 在执行update语句时,在等待索引idx_wscode上的行锁(编号space id 3331 page
no 16 n bits 904 )。 - 事务二 4219870941 在执行update语句时,已经持有idx_wscode上的行锁(编号space id 3331 page
no 16 n bits 904 ),从锁编号来看,就是事务一需要的锁。 - 事务二 4219870941 同时也在等待主键索引上的一把锁,这把锁谁在持有呢?从这行日志(3: len 7; hex 35343638373534; asc 5468754;;)可以看出,正是事务一要更新的那行记录,说明这把锁被事务一霸占着。
好了,死锁条件已经很清楚了:事务一在等待事务二持有的索引 idx_wscode 上的行锁(编号space id 3331 page no 16 n bits 904 ),而事务二同时也在等待事务一持有的主键索引(5468754)上的锁,大家互不相让,只能僵在那里死锁。
用一张图来说明一下这个情况:
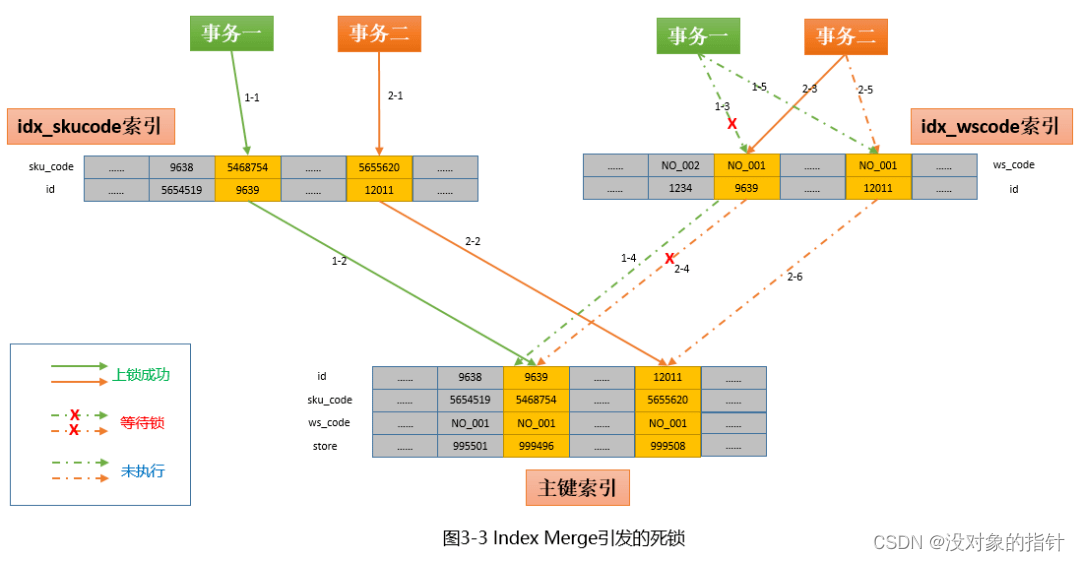
上图描述的只是发生死锁的一条可能路径,实际上仔细梳理的话还有其他路径也会导致死锁,大家感兴趣可以自己探索。上图解释如下:
-
事务一(where sku_code=‘5468754’ and ws_code = ‘NO_001’)首先走idx_skucode索引,分别对二级索引和主键索引加锁成功(1-1和1-2);
-
此时事务二开始执行( where sku_code=‘5655620’ and ws_code = ‘NO_001’),首先也是走idx_skucode(左上)索引,因为和事务一所加锁的记录不冲突,所以也顺利加锁成功(2-1和2-2);
-
事务二继续执行,这时走的是idx_wscode(右上)索引,先对二级索引加锁成功(2-3,此时事务一还没有开始在idx_wscode上加锁),但是在对主键索引加索引时,发现id=9639的主键索引已经被事务一上锁,因此只能等待(2-4),同时在2-4完成加锁前,对其他记录的加锁也会暂停(2-5和2-6,因为InnoDB是逐条记录加锁的,前一条未完成则后面的不会执行);
-
此时事务一继续执行,这时走的是idx_wscode索引,但是加锁的时候发现(NO_001,9639)这条索引项已经被事务二上锁,所以也只能等待。同理,后面的1-4也无法执行。
到此就出现了“两个事务,反向加锁”导致的死锁现象。
4.4 解决死锁
死锁的本质原因还是由加锁顺序不同所导致,本例中是由于Index Merge同时使用2个索引方向加锁所导致,解决方法也比较简单,就是消除因index merge带来的多个索引同时执行的情况。
1)利用 force index(idx_skucode) 强制走某个索引,这样 InnoDB 就会忽略index merge,避免多个索引同时加锁的情况。

2)禁用 Index Merge,这样 InnoDB 只会使用 idx_skucode 和 idx_wscode 中的一个,所有事物加锁顺序都一样,不会造成死锁。
用命令禁用Index Merge:
SET GLOBAL optimizer_switch='index_merge=off, index_merge_union=off, index_merge_sort_union=off, index_merge_intersection=off';

重新登录终端后再看下执行计划:

3)既然Index Merge同时使用了2个独立索引,我们不妨新建一个包含这两个索引所有字段的联合索引,这样InnoDB就只会走这个单独的联合索引,这其实和禁用index merge是一个道理。
新增联合索引:
alter table store add index idx_skucode_wscode(sku_code, ws_code);
再看下执行计划,type = range 说明没有使用 index merge,另外 key = idx_skucode_wscode 说明走的是刚刚创建的联合索引:

4)最后推荐另外一种绕过 index merge 限制的方式。即去除死锁产生的条件,具体方法是先利用 idx_skucode 和 idx_wscode 查询到主键 id,再拿主键 id 进行 update 操作。这种方式避免了由 update 引入X锁,由于最终更新的条件是唯一固定的,所以不存在加锁顺序的问题,避免了死锁的产生。
案例来源:@dbaplus社群
5. 如何避免死锁
- 事务尽可能小,不要将复杂逻辑放进一个事务里。
- 涉及多行记录时,约定不同事务以相同顺序访问。
- 业务中要及时提交或者回滚事务,可减少死锁产生的概率。
- 表要有合适的索引。
- 可尝试将隔离级别改为 RC 。