一:深度优先搜索DFS
我们以图为例,图是由一些小圆点(顶点)和连接这些小圆点的直线(边)组成。例如:
现在我们想要遍历这个图,我们可以从1号顶点开始,遍历就是将图中每一个顶点都访问一次。使用深度优先搜索会得到这么一个结果
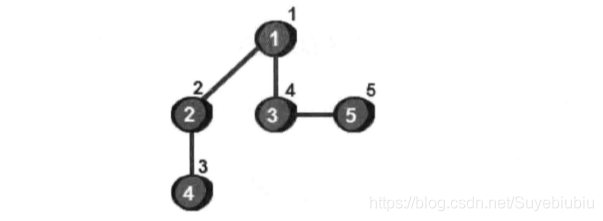
他们身上标注的数字就是他们的访问次序。这个次序还有一个非常好听的名字叫时间戳。下面我们来分析这个深度优先搜索的整个过程。
过程分析:
首先是从一个未曾走过的顶点作为起始点。比如在我们例子中1号顶点就是我们的起始点,沿着1号节点的边去尝试访问其他未走到过的顶点,首先发现2号顶点还没有访问过,于是我们来到了2号顶点的位置,再以2号顶点作为出发点继续尝试访问其他顶点。来到了4号顶点,再以4号顶点为出发点继续访问,但是我们发现已经到头了,没法继续访问,我们就返回到2号节点,返回2号节点后我们发现一样没法继续访问,我们继续返回到1号节点,我们在1号节点位置看看是否还可以访问其他没有被访问过的顶点。此时会来到3号顶点,再以3号顶点为发出点继续访问5号节点。到此,我们所有顶点均被访问过了,遍历过程结束。
在整个过程中我们将返回过程称为回溯,并且我们默认左侧优先级高于右侧。优先访问左节点,便于代码书写。
我们在讲解代码之前,还要想一个问题,就是我们怎么解决存储一个图的问题呢?最常见的是使用一个二维数组e来存储一张图,如下:
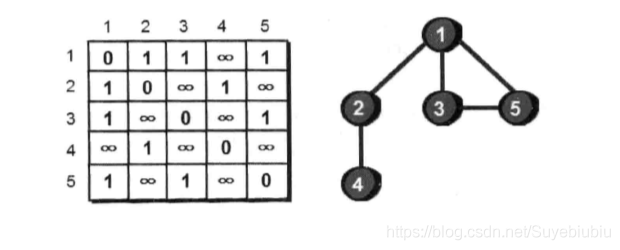
上面的二维数组中,第i行第j列表示的是从顶点i到顶点j是否有边,无穷代表着没有边,1表示有边,这里我们将自己到自己设为0.我们将这种储存图的方法称为图的邻接矩阵存储法。
注意观察的同学可以会看到,这个二维数组是沿着主对角线对称的,因为上面的这个图是个无向图。图中的边没有方向。ok,我们接下解决如何使用DFS解决我们这个问题了。

上面的代码中,cur存储的是当前正在遍历的节点,二维数组e存储的就是图的边。数组book用来记录哪些边已经被访问过了,标记为1表示已经被访问过的节点。变量sum用来记录已经访问过多少个顶点了,变量n存储的是图的顶点的总个数。完整代码如下:


我们可以输入数据进行验证一下:

二:广度优先搜索
同一张图,我们再用广度优先搜索遍历一下,广度优先搜索的次序如下:(顶点上的数组为访问的次序)
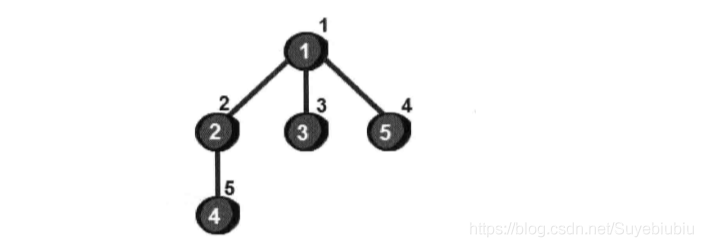
那么我们还是像DFS一样探讨一下整个BFS过程。
过程分析:
首先我们还是以一个未被访问过的节点作为起始点,我们比如以1号节点为起始点,我们将1号顶点放到队列中,然后我们将与1号节点相邻的所有未被访问过的顶点2号,3号和5号放到队列中,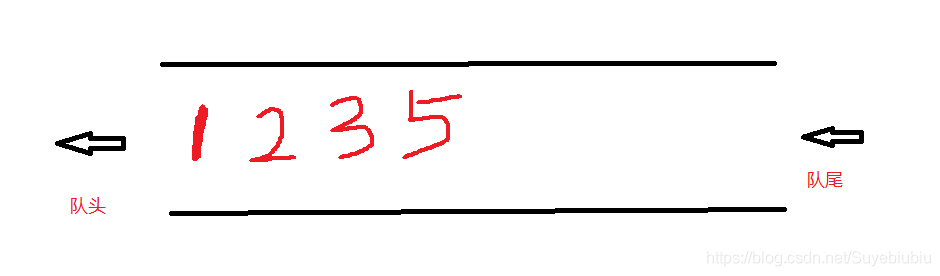
接下来再将2号顶点相邻的未被访问过的所有顶点4号顶点放到队列中,到此所有顶点都被访问过,遍历结束。
广度优先搜索的主要思想就是:首先从一个从未被访问过的顶点出发,访问其所有相邻的顶点,然后对每个相邻的顶点再访问其相邻但是未被访问过的所有节点。直到所有的节点均被访问过,遍历过程结束。代码实现如下:




输入一下数据我们进行验证:

三:深度优先搜索 VS 广度优先搜索
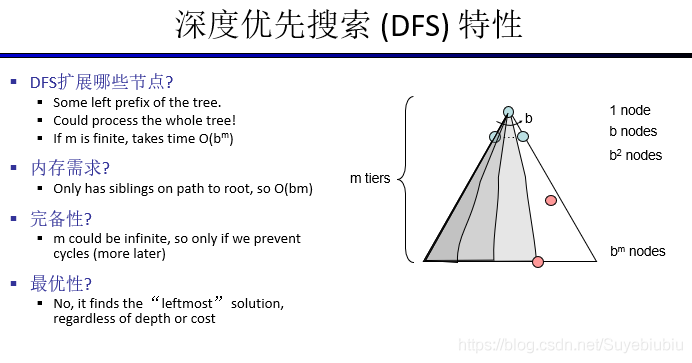
深度优先搜索(DFS),可以被形象的描述为“打破沙锅问到底”,具体一点就是访问一个顶点之后,我继而访问它的下一个邻接的顶点,如此往复,直到当前顶点一被访问或者它不存在邻接的顶点。
同样,算法导论采用了“聪明的做法”,用三种颜色来标记三种状态。但这三种状态不同于广度优先搜索:
- WHITE 未访问顶点
- GRAY 一条深度搜索路径上的顶点,即被发现时
- BLACK 此顶点的邻接顶点被全部访问完之后——结束访问次顶点
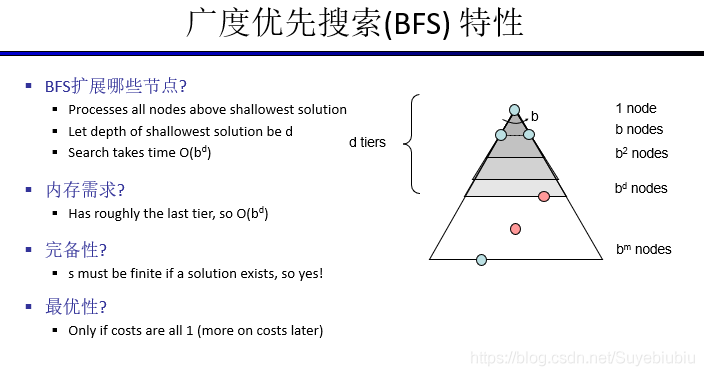
广度优先搜索(BFS),可以被形象的描述为“浅尝辄止”,具体一点就是每个顶点只访问它的邻接节点(如果它的邻接节点没有被访问)并且记录这个邻接节点,当访问完它的邻接节点之后就结束这个顶点的访问。
广度优先用到了“先进先出”队列,通过这个队列来存储第一次发现的节点,以便下一次的处理;而对于再次发现的节点,我们不予理会——不放入队列,因为再次发现的节点:
- 无非是已经处理完的了;
- 或者是存储在队列中尚未处理的
两个算法都是O(V+E),在用到的时候适当选取。在使用白灰黑标志的时候,突然明白了如何用深度优先搜索来判断有向图中是否存在环。
深度优先和广度优先各有各的优缺点:
- 广优的话,占内存多,能找到最优解,必须遍历所有分枝. 广优的一个应用就是迪科斯彻单元最短路径算法.
- 深优的话,占内存少,能找到最优解(一定条件下),但能很快找到接近解(优点),可能不必遍历所有分枝(也就是速度快), 深优的一个应用就是连连看游戏.
- 在更多的情况下,深优是比较好的方案。