bs4之Beautiful Soup
-
-
- 安装
- 解析器说明
- 解析文档使用方法
- 选择器
- 节点选择器
-
- 选择元素
-
- 具体解析
- 嵌套选择
- 关联选择
- css选择器
-
- 选择器类型及使用
- css高级用法
-
- 嵌套选择
- 属性获取
- 方法选择器
-
- find_all()
- find()
- 其他的方法选择器
-
三岁学编程,笔记,中间会有一些问题有待解决,希望大家一同探讨,共同提高
安装
Beautiful Soup 是解析HTML和XML的工具,并提取的数据。
安装采用安装python第三方库 bs4pip install bs4 或pip3 install bs4
Beautiful Soup 中支持多种解析器,包括第三方解析器
| 安装内容 | 安装代码(cmd下安装) |
|---|---|
| bs4 | pip install bs4 |
| html.parser | python自带解析器无需下载 |
| lxml解析器 | pip install lxml |
| html5lib解析器 | pip install html5lib |
解析器说明
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| python标准库 | Beautiful Soup(markup, ‘html.parser’) | python标准库,执行速度适中文档容错能力强 | 2.7或3.2前版本不是很适用(容错差) |
| lxml解析器 | Beautiful Soup(markup, ‘lxml’) | 解析速度快,容错能力强 | 需要安装C语言库(第三方库) |
| lxml之XML解析器 | Beautiful Soup(markup, [‘lxml’,‘xml’])或Beautiful Soup(markup, ‘xml’) | 速度快,而且是唯一支持XML的解析器 | 需要安装第三方库 |
| html5ilb | Beautiful Soup(markup, ‘html5lib’) | 最好的容错性,以浏览器形式生成html5格式文档 | 速度慢,不依赖拓展 |
建议使用lxml解析器,在实际过程中也会推荐lxml,如果是XML格式则使用XML解析器。
解析文档使用方法
因为 Beautiful Soup是第三方库,需要导入from bs4 import BeautifulSoup
通过 Beautiful Soup 实例化对象(进行解析)采用BeautifulSoup(markup, features)
markup : 代表要被解析的文档 ,可以直接传入,或者从文件中打开
features:代表着解析方式,就是上面的4种解析方法
#导入第三方库
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)#把html变量进行解析
soup = BeautifulSoup(open(a.html))#把文件2进行解析
注:以上未标注解析方法(解析器)时默认Python自带解析器
soup = BeautifulSoup(html, 'lxml')#把html变量采用‘lxml’解析器进行解析
选择器
Beautiful Soup 选择器有三种 分别是:节点选择器,方法选择器,css选择器
| 选择器 | 作用 |
|---|---|
| 节点选择器 | 获取数据基本方法 |
| 方法选择器 | 查找定位元素 |
| css选择器 | 查找定位元素 |
当三种选择器结合运用基本上能够解决大部分的查找,偶尔加上正则表达式锦上添花
节点选择器
选择元素
节点选择器是采用标签作为节点进行提取对象但是前提是对象必须是tag对象(即标签对象)
常用属性
| 属性 | 描述 |
|---|---|
| head | HTML页面的<head>内容 |
| title | HTML页面标签中<head>之中由<title>标记 |
| bady | 页面中<bady>的内容 |
| p | 页面中第一个<p>标签的内容 |
| strings | 页面上所有呈现在web上的字符串,即标签内容 |
| stripped_strings | 所有呈现在web的非空字符串 |
emmm是不是一脸懵逼进来一脸懵逼出去,最后发现懵逼树下只有你和我。嘎嘎嘎
emmm,小编理解,就是
实例化对象.标签名 = 标签内容
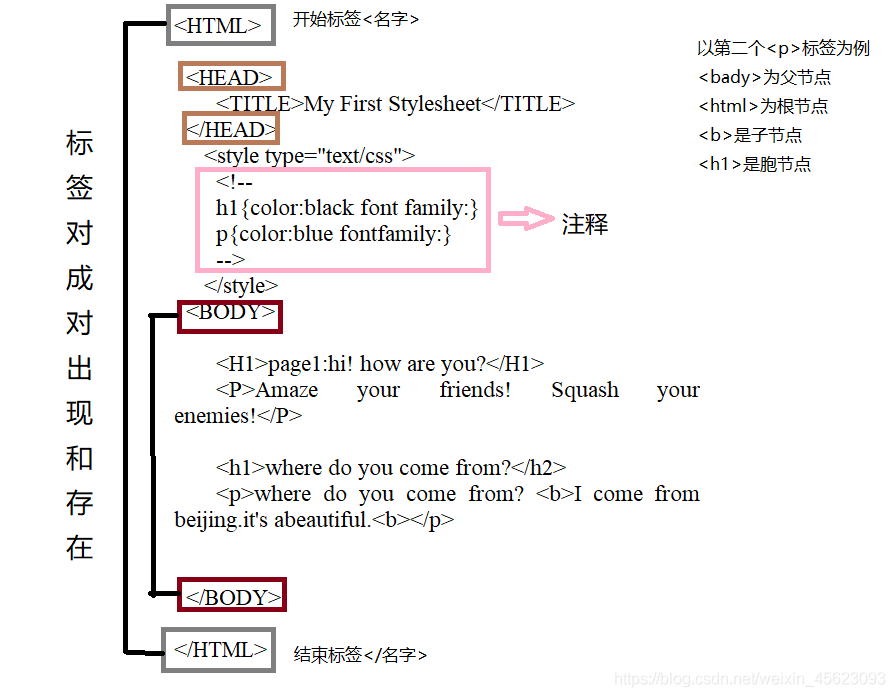
小编没有学过HTML,以上理解比较片面,如有问题请帮忙指正
接下来以百度首页为soup进行解释
url = 'http://www.baidu.com'
html = getHTMLText(url)#此处省略了自定义函数
soup = BeautifulSoup(html, 'lxml')
print(soup.head)
结果:
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type"/>
<meta content="IE=Edge" http-equiv="X-UA-Compatible"/>
<meta content="always" name="referrer"/>
<link href="http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css"
rel="stylesheet" type="text/css"/>
<title>百度一下,你就知道</title>
</head>
#把里面第一个<head>标签及里面所有内容都提取出来了
print(soup.title)
结果:
<title>百度一下,你就知道</title>
#第一个<title>标签及内容
print(type(soup.title))
结果:
<class 'bs4.element.Tag'>
#这是一个tag对象(标签对象)
print(soup.p)
结果:
<p id="lh">
<a href="http://home.baidu.com">
关于百度
</a>
<a href="http://ir.baidu.com">
About Baidu
</a>
</p>
标签里面的常用属性:
| 属性 | 返回类型及描述 |
|---|---|
| name | 字符串,标签的名字 |
| attrs | 字典,包含了tag里面所有的属性 |
| contents | 列表,这个tag下面所有的tag的内容 |
| string | 字符串,tag所包围的整个文本,网页中的真实文字 |
举例:还是拿百度首页做例子
print(soup.a)
结果:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
print(soup.a.name)
结果:
a
print(soup.a.attrs)
结果:
{
'href': 'http://news.baidu.com', 'name': 'tj_trnews', 'class': ['mnav']}
print(soup.title.name)
结果:
title
print(soup.title.string)
结果:
百度一下,你就知道
print(soup.title.contents)
结果:
['百度一下,你就知道']
具体解析
soup.标签名
例:soup.tag
这里的name就是标签,获得的结果就是HTML对象的第一个该标签的全部内容
该对象的类型是tag类型
soup.标签名.name
例:soup.tag.name
结果为 a 类型为字符串
soup.标签名.attrs
例:soup.tag.attrs
返回结果是标签里面的所有信息返回格式为字典
{'href': 'http://news.baidu.com', 'name': 'tj_trnews', 'class': ['mnav']}
soup.标签名.string
例:soup.tag.string
返回的为标签里面的内容,返回类型为字符串
嵌套选择
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type"/>
<meta content="IE=Edge" http-equiv="X-UA-Compatible"/>
<meta content="always" name="referrer"/>
<link href="http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css"/>
<title>百度一下,你就知道</title>
</head>
以以上为例:
解析这是有一个<head>标签对包裹的里面有3个<meta>单标签和一个<link>单标签,同时还有一对<title>标签构成
可以通过soup.tag.tag来嵌套获得子标签内容。获得的类型还是tag类型
print(soup.head.title)
结果:
<title>百度一下,你就知道</title>
print(soup.head.title.string)
结果:
百度一下,你就知道
关联选择
在某些时候需要不能够一次性选择到位
或有几个相同的标签怎么办,那么就用关联选择。
一:子节点
soup.tag.contents
返回列表,把所有的结果都放在一个列表里面
soup.tag.children
返回一个生成器,需要通过for循环来获取各个值
for i in soup.tag.children:
print(i)
soup.tag.descendants
子孙节点返回一个生成器
二:父节点
soup.tag.parent
返回列表,返回父节点下面所有的内容(节点元素)
三:祖先节点
soup.tag.parents
返回一个生成器
用for循环进行返回,返回各个祖先节点的所有内容
也可以使用list()进行获得
list(soup.a.parents)
四:兄弟节点
获取后面一个节点
·soup.tag.next_sibling
返回一个节点元素
获取后面所有的节点
soup.tag.next_siblings
返回一个生成器
获取前面一个节点
soup.tag.previous_sibling
返回一个节点元素
返回前面所有的节点
soup.tag.previous_siblings
返回一个生成器
css选择器
使用方法:soup.select()即可获取结果
在括号中输入定位元素即可
选择器类型及使用
(1)id选择器使用#定位元素
<ul class=“list” id=list-1 >
其中获取该节点可以采用 #list-1
id在html文档中是独一无二存在的
(2)类选择器
还是以上的例子要用class元素进行定位就叫做类选择器
其中用.来表示
定位ul中的class类就要用ul.list
(3)标签选择器
通过标签进行选择
直接输入需要获取的标签名即可
(4)混合使用
在某些时候,获取需要的标签无法使用一个选择器进行获取时就可以混合使用,以获得所需要的内容
css高级用法
嵌套选择
css选择器获得的结果是一个对象列表所以可以循环嵌套,具体的不在详解
关键是没有一个好的HTML文本同于解析
属性获取
css返回的是tag类型的对象
所以也可用attrs获取属性
使用string获得文本(本节点)
使用strings获得文本(子孙节点)(返回一个生成器用list()或for循环调用)
方法选择器
find_all()
用于搜索当前节点下所有的符合条件的节点
没有指点节点则是全文
用法:
find_all(name, attrs, recursive, text, **kwargs)
name:节点的标签名,查找所有名为name的节点(tag对象)
| name使用形式 | 字符串、正则表达式、列表、True(作用) |
|---|---|
| 字符串 | 默认表示标签名 |
| 正则表达式 | 用表达式代替标签名,查找所有符合条件的标签内容 |
| 列表 | 把列表中多个标签全部进行查找 |
| True | 所有内容 |
attrs:查询含有属性值的标签
参数类型:字典类型
例:
查询id = link1的标签
soup.find_all(attrs= {
id:'link1'})
结果为soup下所有id=link1的标签内容
**kwargs:
接收常用的属性通过赋值的形式表达
以上面的内容为例
查询id = link1的标签
soup.find_all(id='link1')
查询class = story的标签
soup.find_all(class_ = 'story')
注:因为class是内置函数,传入参数会报错,需要加下划线
text:查询接收的文本标签,是字符串形式
相对应查找你要的内容直接进行检索
直接用与字符串的查找,和word的查找功能类似
查找Elsie
soup.find_all(text= 'Elsie')
['Elsie']
可以用于混合使用
查找a标签中含‘Elsie’的内容
soup.find_all('a',text = 'Elise')
limit:用于限制返回结果的数量
参数形式整数
recursive:决定是否返回子孙节点的值
类型为布尔型,默认True
find()
find() 返回查询到的第一个元素节点
使用上比find_all()少了一个limit参数其他的基本上一样
返回的结果是一个元素不是列表,而且只获取第一个元素,子孙节点无法获取
其他的方法选择器
其他的方法选择器大致可以表示为find_···()
他们的选择条件不同,不是经常使用掌握好find_all()和find()熟练使用可以满足大部分需求,其他的此处不做过多赘述。
以上内容为个人理解,有问题请及时沟通交流,及时修改!谢谢大家