rocksdb是什么?
rocksdb是facebook的项目,目的是开发一套能在服务器压力下,真正发挥高速存储硬件性能的高效数据库系统;使用C++实现;
是嵌入式数据库kv数据库;不提供网络服务,只提供数据持久化的方案。
rocksdb是基于leveldb实现的,原始代码是从leveldb 1.5上fork出来的;
分布式三篇著名的论文,源自于google:
- GFS, 分布式文件存储;
- BigTable,分布式kv存储;
- MapReduce,大数据处理。
leveldb的作者就是BigTable的作者。
rocksdb解决了什么问题?
主要解决写多读少的问题,牺牲读性能来加速写性能;
Mysql innodb B+树,解决了读多写少的问题;
怎么解决的?
rocksdb是基于LSM-Tree(log structure merge-tree)实现的;
利用LSM-Tree来提升写性能;
LSM-Tree
主要思想是利用磁盘顺序IO来提升写性能;LSM-Tree并不是Tree数据结构,仅仅是一种存储结构;LSM-Tree是为了写多读少(对读的性能实时性要求相对较低)的场景而提出的解决方案;如日志系统、海量数据存储、数据分析等。
以下问题需要考虑:
- 磁盘顺序写,会记录同一个key的多次写操作,存在数据冗余,怎么解决数据冗余的问题?
- 怎么提高读性能?
- 数据肯定是先写到缓存里面的,缓存使用什么样的数据结构?
- 缓存中的数据通过什么样的策略刷到磁盘中?
- 怎么保证缓存和磁盘中数据的一致性?
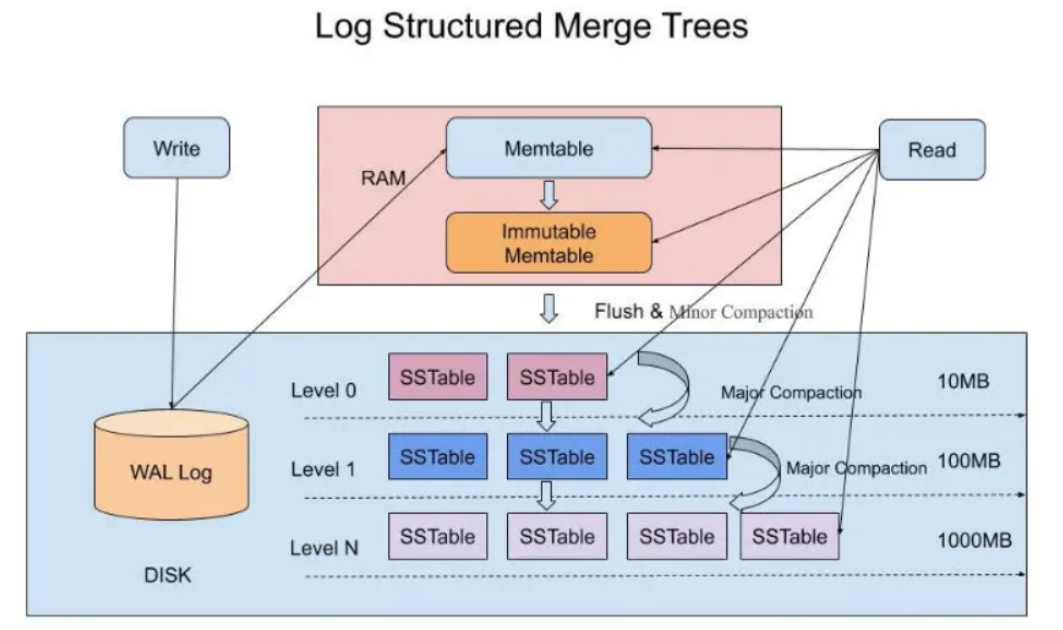
memtable
memtable是一个内存数据结构,它保存了落盘到sst文件前的数据;写入数据的时候总是先将数据写入到memtable,读取的时候也是先查询memtable;一旦一个memtable被写满,它会变为immutable memtable,即只读的memtable;然后会创建一块新的memtable来提供写入操作;immutable memtable将异步落盘的sst文件中,之后该memtable将会被删除。
memtable默认使用的数据结构是skiplist;
immutable memtable的两个作用?
- 用来落盘
- 提高并发读写性能
memtable中为什么使用skiplist?
缓存中应该使用什么数据结构来存储?
有序结构,并且缓存中没有冗余数据
为什么不使用rbtree?
- 红黑树查找下一个节点的复杂度是O(log2n);skiplist查找一个节点是的时间复杂度是O(1); rocksdb需要实现iterator功能,需要进行遍历,skiplist更加合适;
- 并发读写,skiplist锁粒度比rbtree小;skiplist锁单个节点,rbtree锁整个红黑树。
rbtree与skiplist使用场景比较
- 定时器,查找最小的节点; rbtree时间复杂度O(log2n), skiplist时间复杂度O(1);
- nginx slab使用红黑树,能不能使用skiplist?最好不要用skiplist,因为共享内存一开始要分配固定大小内存,skiplist节点大小不是固定的,节点层级不确定,有冗余数据;
skiplist加锁位置:
- max_height; 需要对它进行并发读写;增删改查,第一步都需要先进行查找,先在最高层进行查找;新增节点,生成的随机高度,有可能大于max_height;
- 对node加锁;
落盘策略
- 定时刷新
- 阈值刷新
WAL(write ahead log)
mysql中,redo log 实现WAL,写前日志;用来恢复数据,异步刷盘;rocksdb也有WAL日志;在出现宕机的时候,WAL日志可以用于恢复memtable的数据;当memtable中的数据落盘到sst文件后,才会删除对应的WAL日志。
ss table(sorted string table)
每个immutable memtable都会落盘为一个ss table文件;
L0层可能会有重复数据,会有数据冗余,不利于快速查找;文件间无序,文件内部有序;
L1 ~ LN 层会对重复数据进行合并,思想与时间轮算法一致;根据数据的冷热程度进行分层;
L1 ~ LN 每层数据没有重复,跨层可能有重复;文件间是有序的,同一层的每个文件,key的范围不同;
磁盘数据读性能的提升
blockcache
rocksdb在内存中缓存数据,以提高读性能;
rocksdb有两种实现方式,lrucache,clockcache;lrucache读写都需要加锁;clockcache写加锁,读不加锁;nginx定时器使用clockcache,32个操作槽位,提升并发性能;
布隆过滤器
布隆过滤器使用前提:不支持删除,ss table中的数据不存在删除;
特征:能确定一定不存在,不能确定一定存在(有误判率,并且可控);可控,提供预期存储元素个数和误判率,算出所占存储空间和hash函数个数;
在sst每一层增加一个布隆过滤器,提高查找效率。
怎么合并压缩?
怎么制定合并压缩的策略?
需要综合考虑LSM-Tree的三大问题;
LSM-Tree三大问题
类似于隔离级别,cap原则;只能减小其中的一个,另外两个会被放大。
读放大
B+树是2-4层,最多4次io,读性能高;LSM-Tree最多7层,读性能相比B+树要差;
B+树为什么读性能高,写性能低?
B+树分裂造成写性能比较低;
空间放大
所有的写操作都是顺序写,而不是就地更新,无效数据不会被马上清理掉;
B+树是就地更新,但是由于B+树以页(16K)为单位存储,但是页内有很大的空间浪费,空间放大更严重;
写放大
同一条数据多次写入磁盘;sst不同层级之间可能存在重复数据;
B+树分裂的时候有写放大,其他时候不会。
压缩策略
为了在读放大、空间放大以及写放大之间进行取舍,以适应不同的业务场景;所以需要选择不同的合并算法;
默认策略:leveled compaction & tiered
放大**
同一条数据多次写入磁盘;sst不同层级之间可能存在重复数据;
B+树分裂的时候有写放大,其他时候不会。
压缩策略
为了在读放大、空间放大以及写放大之间进行取舍,以适应不同的业务场景;所以需要选择不同的合并算法;
默认策略:leveled compaction & tiered
内存中多线程,磁盘合并也是多线程的。