背景
最近参与的项目是基于 OpenStack 提供容器管理能力,丰富公司 IaaS 平台的能力。日常主要工作就是在开源的 novadocker 项目(开源社区已停止开发)基础上进行增强,与公司的其他业务组件进行对接等。
周末给下游部门的 IaaS 平台进行了一次升级,主要升级了底层操作系统,基本用例跑通过,没出现什么问题,皆大欢喜。
结果周一一到公司就传来噩耗,性能测试发现业务进程运行在容器中比业务进程运行在宿主机上吞吐量下降了 100 倍,这让周一显得更加阴暗。
周一
先找下游了解了下业务模型,他们说已经把业务模型最简化了,当前的模式是:业务进程运行在容器中,通过与主机共享 IPC namespace 的方式来使用共享内存与宿主机上的 Daemon 进程进行通信,整个过程不涉及磁盘读写、网络交互等。
撸起袖子开始干,定位第一步,当然是找瓶颈了,分析下到底问题出在哪。
top
用到的第一个命令自然是 top,top 是 linux 里一个非常强大的命令,通过它基本上能看到系统中的所有指标。

上面是 top 命令运行时的一个示意图,比较重要的指标都已经标了出来:
1 处表示系统负载,它表示当前正在等待被 cpu 调度的进程数量,这个值小于系统 vcpu 数(超线程数)的时候是比较正常的,一旦大于 vcpu 数,则说明并发运行的进程太多了,有进程迟迟得不到 cpu 时间。这种情况给用户的直观感受就是敲任何命令都卡。
2 处表示当前系统的总进程数,通常该值过大的时候就会导致 load average 过大。
3 处表示 cpu 的空闲时间,可以反应 cpu 的繁忙程度,该值较高时表示系统 cpu 处于比较清闲的状态,如果该值较低,则说明系统的 cpu 比较繁忙。需要注意的是,有些时候该值比较高,表示 cpu 比较清闲,但是 load average 依然比较高,这种情况很可能就是因为进程数太多,进程切换占用了大量的 cpu 时间,从而挤占了业务运行需要使用的 cpu 时间。
4 处表示进程 IO 等待的时间,该值较高时表示系统的瓶颈可能出现在磁盘和网络。
5 处表示系统的剩余内存,反应了系统的内存使用情况。
6 处表示单个进程的 cpu 和内存使用情况。关于 top 命令中各个指标含义的进一步描述可以参见:
http://www.jb51.net/LINUXjishu/34604.html
使用 top 命令查看了下系统情况,发现一切正常。load average 也不高,task 也不多,cpu 和内存都还很空闲,就连 IO 等待时间都很低,也没有哪个进程的 cpu 和内存使用率偏高,一切都很和谐,没有瓶颈!
当然,没有瓶颈是不可能的。由于我们的容器都是绑核的,所以很有可能是分配给容器的那些核是处于繁忙状态,而由于总核数较多,将 cpu 的使用率给拉了下来。于是又按下了“1”键,切换到详细模式下:
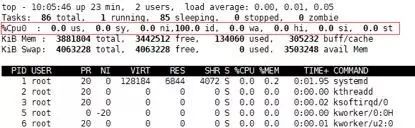
在这种模式下,可以看到每个 vcpu 的使用情况。一切依然很和谐,诡异的和谐。
看来从 cpu 这块是看不出来什么了,那就继续看看是不是磁盘搞的鬼吧。
iostate
iostate 命令是用来查看磁盘使用情况的一个命令,经验告诉我们,磁盘和网络已经成为影响性能的最大嫌疑犯。
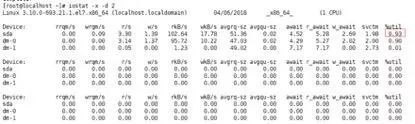
使用 iostate 工具时,通常只用关注最后一行(%util)即可,它反映了磁盘的繁忙程度。虽然下游部门已经说了他们跑的用例是一个纯内存的场景,不涉及磁盘读写。但是客户的话信得住,母猪也能上树,我还是要跑一下 iostate,看下磁盘情况怎么样。结果,依旧很和谐,磁盘使用率基本为零。
后面还尝试了观察网络指标,发现确实也没有网络吞吐,完了,看来问题没那么简单。
周二
虽然周一看似白忙活了一天,但是也得到了一个重要结论:这个问题不简单!不过简单的在资源层面时分析不出来啥了,得寄出性能分析的大杀器——perf 了。
perf+ 火焰图
perf 是 linux 下一个非常强大的性能分析工具,通过它可以分析出进程运行过程中的主要时间都花在了哪些地方。
之前没太使用过 perf,因此刚开始进行分析,就自然而然地直接使用上了 perf+ 火焰图这种最常见的组合:
- 安装 perf。
yum install perf
-
下载火焰图工具。
git clone https://github.com/brendangregg/FlameGraph.git
-
采样。
perf record -e cpu-clock -g -p 1572(业务进程 id)
一段时间(通常 20s 足够)之后 ctrl+c,结束采样。
-
用 perf script 工具对 perf.data 进行解析。
perf script -i perf.data &> perf.unfold。
PS:如果在容器中运行的程序有较多的依赖,则该命令解析出来的符号中可能会有较多的“Unregistered symbol…”错误,此时需要通过
--symfs参数指定容器的rootfs位置来解决该问题。获取容器rootfs的方法根据 docker 的 storagedriver 的不同而有所不同,如果是device mapper类型,则可以通过 dockerinspect 找到容器的rootfs所在位置,如果是overlay类型,则需要通过 dockerexport 命令将该容器的rootfs导出来,如果是富容器的话,一般都有外置的rootfs,直接使用即可。 -
将 perf.unfold 中的符号进行折叠。
./stackcollapse-perf.pl perf.unfold &> perf.folded
-
最后生成 svg 图。
/flamegraph.pl perf.folded > perf.svg
最后就能得到像下面这种样子的漂亮图片。通常情况下,如果程序中有一些函数占用了大量的 CPU 时间,则会在图片中以长横条的样式出现,表示该函数占用了大量的 CPU 时间。

然而,perf+ 火焰图在这次并没有起到太大的作用,反复统计了很多次,并没有出现梦寐以求的“长横条”,还是很和谐。
perf stat
perf+ 火焰图并没有起到很好的效果,就想换个工具继续试试,但是找来找去、请教大神,也没找到更好的工具,只好继续研究 perf 这个工具。
perf 除了上面提到的 record(记录事件)、script(解析记录的事件)命令之外,还有其他一些命令,常用的有 report(与 script 类似,都是对 perf record 记录的事件进行解析,不同之处在于 report 直接解析程序中的运行热点,script 的扩展性更强一点,可以调用外部脚本对事件数据进行解析)、stat(记录进程一段时间之内触发的事件数)、top(实时分析程序运行时热点)、list(列出 perf 可以记录的事件数)等命令。
这些命令挨个试了个遍,终于在 perf stat 命令这块有了突破:
使用 perf stat 对业务进程运行在物理机和容器上分别进行统计,发现业务进程运行在容器中时,大部分事件(task-clock、context-switches、cycles、instructions 等)的触发次数是运行在物理机上时的百分之一。
这是什么原因呢?一定是什么东西阻塞住了程序的运转,这个东西是什么呢?
前面已经分析了,不是磁盘,不是网络,也不是内存,更不是 cpu,那还有什么呢??
周三
是什么原因阻塞住了程序的运转呢?百思不得其解,百问不得其解,百猜不得其解,得,还是得动手,上控制变量法。
运行在容器中的程序和运行在物理机上有什么区别呢?我们知道,docker 容器 =cgroup+namespace+secomp+capability+selinux,那么就把这些技术一个个都去掉,看到底是哪个特性搞的鬼。
在这 5 个技术中,后三个都是安全相关的,都有开关可以控制,经过测试,发现把后三个都关掉之后,性能还是很差,说明这 3 个技术是无辜的,开始排查 cgroup 和 namespace。
首先怀疑的当然是 cgroup,毕竟它就是做资源限制的,很有可能一不小心限制错了,就把业务给限制了。
cgexec
cgexec 是 cgroup 提供的一个工具,可以在启动时就将程序运行到某个 cgroup 中,因此我们可以将业务程序运行在物理机上,但是放到业务容器所在的 cgroup 中,看看性能会不会下降。
具体用法如下:
cgexec -g *:/system.slice/docker-03c2dd57ba123879abab6f7b6da5192a127840534990c515be325450b7193c11.scope ./run.sh通过该命令即可将 run.sh 运行在与容器 03c2dd57 相同的 cgroup 中。在多次测试之后,发现这种情况下,业务进程的运行速度没有受到影响,cgroup 被洗白,那么真相只有一个——凶手就是 namespace。
周四
虽然说凶手已经确定是 namespace,但是 namespace 家族也有一大票人,有 ipc namespace、pid namespace 等等,还需要进一步确定真凶。
nsenter
nsenter 是一个 namespace 相关的工具,通过它可以进入某个进程所在的 namespace。在 docker exec 命令出现之前,它唯一一个可以进入 docker 容器的工具,在 docker exec 出现之后,nsenter 也由于其可以选择进入哪些 namespace 而成为 docker 问题定位的一个极其重要的工具。
通过如下命令,即可进入容器所在的 mount namespace。
nsenter --target $(docker inspect --format '{{.State.Pid}}' 容器 id) --mount bash同理,通过如下命令即可进入容器所在的 IPC namespace 和 pid namespace。
nsenter --target $(docker inspect --format '{{.State.Pid}}' 容器 id) --ipc --pid bash在不断的将业务进程在各个 namespace 之间切换后,终于进一步锁定了真凶:mount namespace。测试发现,一旦将业务进程放置到容器所在的 mount namespace,性能就会急剧下降。
这是为什么呢?这是为什么呢?mount namespace 到底做了什么,会有这么大的影响?
离开公司时已经时 12 点,隔壁工位的专家还在那电话会议,“我看哈,这一帧,在这个节点还是有的,但是到了这呢,就没了,它。。”,“那是找到丢包原因了?”,“别急嘛,我慢慢看,看这个节点。”。
在回家的出租车上,想想这个问题已经四天了,想想隔壁工位的专家都要成神了,还是会遇到棘手的问题,突然有种崩溃的感觉,费了九牛二虎之力猜把眼泪憋回去,不然还真怕吓着出租车师傅。
周五
早上起床还和女朋友谈起这事,说我最近遇到了一个大难题,想想已经好多年没遇到这么难搞的问题了。上一次遇到这种级别的问题,还是大四刚进实验室的时候,那时候有个问题花了一整周的时间才解决。要是今天我还解决不了这个问题,就破记录了。
记得当时是需要在实验室搭建 eucalyptus 集群,之前每次搭建都很顺利,但是那次却奇怪,怎么都搭建不成功,研究了一周之后,才发现是因为那台服务器的 bios 时间被还原了,eucalyptus 在安装过程中发现当前时间不在自己的有效时间内(太早了),因此一直安装失败。
言归正传,mount namespace 为什么有这么大的威力呢?它到底影响什么了呢?实在想不通,就去请教了下大神,大神想了想,回了我句,试试 ldd?
ldd
ldd 是什么?
当然这句话我没去问大神,转身自己查去了。
ldd 是 list, dynamic, dependencies 的缩写,意思是列出动态库依赖关系。顿时豁然开朗,mount namespace 隔离出了自己的文件系统,所以容器内外可以使用不同的依赖库,而不同的依赖库就可能造成无数种影响。
于是开始通过 ldd 对比容器中业务进程的依赖库与宿主机上业务进程的依赖库,最终发现容器中的 glibc 库与宿主机上的 glibc 库版本不一致,很可能是这个原因导致性能下降的。
于是将容器中的 glibc 库版本替换为宿主机上的 glibc 库之后,容器内业务的性能终于恢复了,猜想得到证实。
下班回家,一身轻松!
路过隔壁工位的专家时候,他刚好起身接水,顺口问道,“怎么样,平哥,丢失的那一帧找到没?”,“嗨,别提了,继续看”
后记
为什么容器内外 glibc 版本不一致就导致性能下降了呢?
这是和业务模型相关的,前面提到,下游的业务模型是通过与主机共享 IPC namespace 的方式来使用共享内存与宿主机上的 daemon 进程进行通信。而 glibc 在一次升级中,更新了信号量的数据结构(如下),就会导致在共享内存通信时,由于数据格式不一致,每次信号量通信都超时,从而影响了程序运行效率。
