CPU负载查看方法:
使用vmstat查看系统维度的CPU负载
使用top查看进程维度的CPU负载
一、测试工具
1、使用 vmstat 查看系统纬度的 CPU 负载:
可以通过 vmstat 从系统维度查看 CPU 资源的使用情况。
用法说明:
格式:vmstat -n 1# -n 1 表示结果一秒刷新一次。示例输出:
[root@wangerxiao ~]# vmstat -t 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- -----timestamp-----
r b swpd free buff cache si so bi bo in cs us sy id wa st CST
3 0 0 5910832 134096 3931732 0 0 0 1 0 1 0 0 100 0 0 2016-11-13 19:57:36
0 0 0 5910816 134096 3931732 0 0 0 0 274 511 0 0 100 0 0 2016-11-13 19:57:37
回显说明:
返回结果中的主要数据列说明:
r: 表示系统中 CPU 等待处理的线程。由于 CPU 每次只能处理一个线程,所以,该数值越大,通常表示系统运行越慢。
us:用户模式消耗的 CPU 时间百分比。该值较高时,说明用户进程消耗的 CPU 时间比较多,比如,如果该值长期超过 50%,则需要对程序算法或代码等进行优化。
sy:内核模式消耗的 CPU 时间百分比。
wa:IO 等待消耗的 CPU 时间百分比。该值较高时,说明 IO 等待比较严重,这可能磁盘大量作随机访问造成的,也可能是磁盘性能出现了瓶颈。
id:处于空闲状态的 CPU 时间百分比。如果该值持续为 0,同时 sy 是 us 的两倍,则通常说明系统则面临着 CPU 资源的短缺。
回显说明:
返回结果中的主要数据列说明:
r: 表示系统中 CPU 等待处理的线程。由于 CPU 每次只能处理一个线程,所以,该数值越大,通常表示系统运行越慢。
us:用户模式消耗的 CPU 时间百分比。该值较高时,说明用户进程消耗的 CPU 时间比较多,比如,如果该值长期超过 50%,则需要对程序算法或代码等进行优化。
sy:内核模式消耗的 CPU 时间百分比。
wa:IO 等待消耗的 CPU 时间百分比。该值较高时,说明 IO 等待比较严重,这可能磁盘大量作随机访问造成的,也可能是磁盘性能出现了瓶颈。
id:处于空闲状态的 CPU 时间百分比。如果该值持续为 0,同时 sy 是 us 的两倍,则通常说明系统则面临着 CPU 资源的短缺。
2、使用 top 查看进程纬度的 CPU 负载:
可以通过 top 从进程纬度来查看其 CPU、内存等资源的使用情况。
用法说明:格式:top示例输出
[root@wangerxiao ~]# top
top - 20:02:37 up 35 days, 23:33, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 296 total, 1 running, 295 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 12139008 total, 5998320 free, 2074896 used, 4065792 buff/cache
KiB Swap: 2098172 total, 2098172 free, 0 used. 9739056 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1006 influxdb 20 0 5001836 332224 11568 S 1.0 2.7 1172:51 influxd
3578 icinga 20 0 1399032 12792 5152 S 0.3 0.1 136:59.57 icinga2
30207 root 20 0 40800 2120 1328 R 0.3 0.0 0:00.10 top
1 root 20 0 196848 11904 2348 S 0.0 0.1 7:32.27 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:02.22 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.71 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
回显说明:
默认界面上第三行会显示当前 CPU 资源的总体使用情况,下方会显示各个进程的资源占用情况。
可以直接在界面输入大小字母 P,来使监控结果按 CPU 使用率倒序排列,进而定位系统中占用 CPU 较高的进程。最后,根据系统日志和程序自身相关日志,对相应进程做进一步排查分析,以判断其占用过高 CPU 的原因。
操作案列:
3、hping3
hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。运行 hping3 命令,来模拟 Nginx 的客户端请求
# -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80
# -i u100表示每隔100微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把100调小,比如调成10甚至1
$ hping3 -S -p 80 -i u100 192.168.0.30
虽然在运行 hping3 命令时,我就已经告诉你,这是一个 SYN FLOOD 攻击,你肯定也会想到从网络方面入手,来分析这个问题。不过,在实际的生产环境中,没人直接告诉你原因。
4、tcpdump
# -i eth0 只抓取eth0网卡,-n不解析协议名和主机名
# tcp port 80表示只抓取tcp协议并且端口号为80的网络帧
$ tcpdump -i eth0 -n tcp port 80
15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
...
工具
yum -y install perf sysstat dstat(perf pidstat)
top,htop
pidstat——专门分析每个进程CPU使用情况的工具
pidstat -p $PID
perf——perf是linux2.6.31以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以分析指定应用程序的性能问题。是内置于linux内核源码数中的性能剖析工具,常用于性能瓶颈的查找和热点代码的定位
perf top主要是用于分析各个函数在某个性能事件上的热度,能够快速的定位热点函数,包括应用程序函数
execsnoop 就是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果
dstat 它吸收了 vmstat、iostat、ifstat 等几种工具的优点,可以同时观察系统的 CPU、磁盘 I/O、网络以及内存使用情况
strace 正是最常用的跟踪进程系统调用的工具
pstree查找父进程
sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
【yum -y install hping3 tcpdump】
使用top直接终止CPU消耗较大的进程
注意 :# 按下数字 1 切换到所有 CPU 的使用情况,观察一会儿按 Ctrl+C 结束。
如前面所述,可以通过 top 命令查看系统的负载问题,并定位耗用较多 CPU 资源的进程。
可以直接在 top 运行界面快速终止相应的异常进程。说明如下:
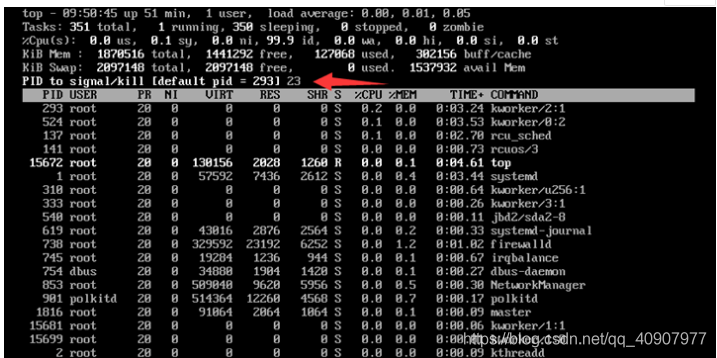
1,想要终止某个进程,只需按下小写的 k 键。
2,输入想要终止的进程 PID (top 输出结果的第一列)。比如,如下图所示,假如想要终止 PID 为 23 的进程,输入 23 后按回车。
**参数介绍 : **
* us:用户态CPU时间
* sy:内核态CPU时间
* ni:低优先级用户态CPU时间
* id:空闲时间
* wa:等待I/O的CPU时间
* hi:处理硬中断的CPU时间
* si:处理软中断的CPU时间
* st:当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间
进程状态:
R(Running) 表示进程在CPU的就绪队列中,正在运行或者正在等待运行
D(Disk Sleep) 不可中断状态睡眠,一般表示进程正在和硬件交互,并且交互过程不允许被其他进程或中断打断【系统硬件出现故障会导致此进程增多,需关注是不是I/O等性能问题】
Z(Zombie) 僵尸进程 ,也就是进程实际上已经结束了,但是父进程还没有收回它的资源(比如进程的描述符,PID等)
S(Interruptible Sleep) 也就是可中断状态失眠,表示进程因为等待某个事件而被系统挂起。当进程等待事件发生时,它会被唤醒并进入R状态。
I(Idel) 空闲状态,用在不可中断睡眠的内核线程上,硬件交互导致的不可中断进程用D表示,但对于某些内核进程来说,它们又可能实际上并没有任何负载,用Idel正是为了区分这种情况,要注意,D状态的进程会导致平均负载升高,I状态的进程不会
T或者t,也就是Stopped或Traced的缩写,表示进程处于暂停或者跟踪状态
X(Dead)表示进程已经消亡,不会在top中查看到
进程组表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员;
会话是指共享同一个控制终端的一个或多个进程组。
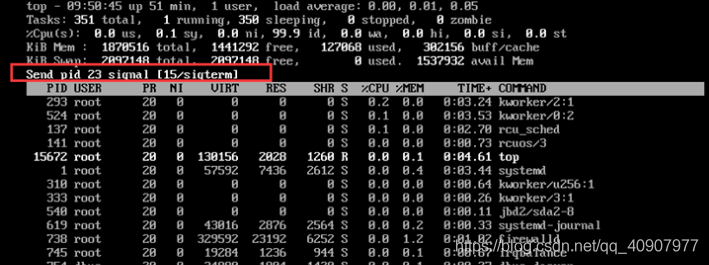
3,如下图所示,操作成功后,界面会出现类似 “Send pid 23 signal [15/sigterm]” 的提示信息让用户进行确认。按回车确认即可
dstat
# 间隔1秒输出10组数据
$ dstat 1 10
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885
0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135
0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177
0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144
0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147
0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131
0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168
0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134
从 dstat 的输出,我们可以看到,每当 iowait 升高(wai)时,磁盘的读请求(read)都会很大。这说明 iowait 的升高跟磁盘的读请求有关,很可能就是磁盘读导致的。
pidstat
# 每隔1秒输出一组数据,共输出5组
$ pidstat 1 5
15:56:02 UID PID %usr %system %guest %wait %CPU CPU Command
15:56:03 0 15006 0.00 0.99 0.00 0.00 0.99 1 dockerd
...
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 15006 0.00 0.99 0.00 0.00 0.99 - dockerd
-----------------
-----------------
用户态 CPU 使用率 (%usr)
内核态 CPU 使用率(%system)
运行虚拟机 CPU 使用率(%guest)
等待 CPU 使用率(%wait)
以及总的 CPU 使用率(%CPU)
# -d 展示 I/O 统计数据,-p 指定进程号,间隔 1 秒输出 3 组数据
$ pidstat -d -p 4344 1 3
06:38:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:38:51 0 4344 0.00 0.00 0.00 0 app
06:38:52 0 4344 0.00 0.00 0.00 0 app
06:38:53 0 4344 0.00 0.00 0.00 0 app
在这个输出中, kB_rd 表示每秒读的 KB 数, kB_wr 表示每秒写的 KB 数,iodelay 表示 I/O 的延迟(单位是时钟周期)。它们都是 0,那就表示此时没有任何的读写,说明问题不是 4344 进程导致的。
pidstat -w -u 1 -w代表进程切换指标,-u表示输出cpu使用指标,每隔1s输出1组数据
Average: UID PID %usr %system %guest %CPU CPU Command
vmstat
vmstat 5
重点关注:
io
- bi 从块设备接收的块(block/s)
- bo 发送给块设备的块(block/s).如果这个值长期不为0,说明内存可能有问题,因为没有使用到缓存(当然,不排除直接I/O的情况,但是一般很少有直接I/O的)
system
- in (interrupt) 每秒的中断次数,包括时钟中断,需要关注,这两个值越大,内核消耗CPU会越大
- cs (context switch) 进程上下文切换次数,需要关注
cpu
- us 用户进程占用CPU时间比例,需要关注us+sy是否已经为100%
- sy 系统占用CPU时间比例
- id CPU空闲时间比
- wa IO等待时间比(IO等待高时,可能是磁盘性能有问题了)
- st steal time
proc
r (Running or Runnnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数。对比cpu的个数,如果等待进程大于cpu个数,需要注意
b (Blocked) 则是处于不可中断睡眠状态的进程数
strace
strace 正是最常用的跟踪进程系统调用的工具。所以,我们从 pidstat 的输出中拿到进程的 PID 号,比如 6082,然后在终端中运行 strace 命令,并用 -p 参数指定 PID 号
$ strace -p 6082
strace: attach: ptrace(PTRACE_SEIZE, 6082): Operation not permitted
这儿出现了一个奇怪的错误,strace 命令居然失败了,并且命令报出的错误是没有权限。按理来说,我们所有操作都已经是以 root 用户运行了,为什么还会没有权限呢?你也可以先想一下,碰到这种情况,你会怎么处理呢?一般遇到这种问题时,我会先检查一下进程的状态是否正常。比如,继续在终端中运行 ps 命令,并使用 grep 找出刚才的 6082 号进程:
果然,进程 6082 已经变成了 Z 状态,也就是僵尸进程。僵尸进程都是已经退出的进程,所以就没法儿继续分析它的系统调用。关于僵尸进程的处理方法,我们一会儿再说,现在还是继续分析 iowait 的问题。到这一步,你应该注意到了,系统 iowait 的问题还在继续,但是 top、pidstat 这类工具已经不能给出更多的信息了。这时,我们就应该求助那些基于事件记录的动态追踪工具了。你可以用 perf top 看看有没有新发现。再或者,可以像我一样,在终端中运行 perf record,持续一会儿(例如 15 秒),然后按 Ctrl+C 退出,再运行 perf report 查看报告:
perf top
$ perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol
7.28% perf [.] 0x00000000001f78a4
4.72% [kernel] [k] vsnprintf
4.32% [kernel] [k] module_get_kallsym
3.65% [kernel] [k] _raw_spin_unlock_irqrestore
...
类似与top,它能够实时显示占用CPU时钟最多的函数或者指令,因此可以用来查找热点函数
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。
比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。
当函数名未知时,用十六进制的地址来表示。还是以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 perf 工具自身,不过它的比例也只有 7.28%,说明系统并没有 CPU 性能问题。 perf top 的使用你应该很清楚了吧。
实例
查看top发现

有6个R状态的进程,查看却是stress(测试)进程
$ pidstat -p 24344(进程id)
16:14:55 UID PID %usr %system %guest %wait %CPU CPU Command
# 从所有进程中查找PID是24344的进程
$ ps aux | grep 24344
root 9628 0.0 0.0 14856 1096 pts/0 S+ 16:15 0:00 grep --color=auto 24344
pstree 就可以用树状形式显示所有进程之间的关系:
$ pstree | grep stress
找到父进程后,再继续排查
用 execsnoop 监控上述案例,就可以直接得到 stress 进程的父进程 PID 以及它的命令行参数,并可以发现大量的 stress 进程在不停启动
# 按 Ctrl+C 结束
$ execsnoop
CPU使用率较低但负载较高
问题描述:
Linux 系统没有业务程序运行,通过 top 观察,类似如下图所示,CPU 很空闲,但是 load average 却非常高:

处理办法:
load average 是对 CPU 负载的评估,其值越高,说明其任务队列越长,处于等待执行的任务越多。
出现此种情况时,可能是由于僵死进程导致的。可以通过指令 ps -axjf 查看是否存在 D 状态进程。
D 状态是指不可中断的睡眠状态。该状态的进程无法被 kill,也无法自行退出。只能通过恢复其依赖的资源或者重启系统来解决。
kswapd0 进程占用 CPU 较高
操作系统都用分页机制来管理物理内存,操作系统将磁盘的一部分划出来作为虚拟内存,由于内存的速度要比磁盘快得多,所以操作系统要按照某种换页机制将不需要的页面换到磁盘中,将需要的页面调到内存中,由于内存持续不足,这个换页动作持续进行,kswapd0是虚拟内存管理中负责换页的,当服务器内存不足的时候kswapd0会执行换页操作,这个换页操作是十分消耗主机CPU资源的。如果通过top发现该进程持续处于非睡眠状态,且运行时间较长,可以初步判定系统在持续的进行换页操作,可以将问题转向内存不足的原因来排查。
问题描述:
kswapd0 进程占用了系统大量 CPU 资源。
处理办法:
Linux 系统通过分页机制管理内存的同时,将磁盘的一部分划出来作为虚拟内存。而 kswapd0 是 Linux 系统虚拟内存管理中负责换页的进程。当系统内存不足时,kswapd0 会频繁的进行换页操作。而由于换页操作非常消耗 CPU 资源,所以会导致该进程持续占用较高 CPU 资源。
如果通过 top 等监控发现 kswapd0 进程持续处于非睡眠状态,且运行时间较长并持续占用较高 CPU 资源,则通常是由于系统在持续的进行换页操作所致。则可以通过 free 、ps 等指令进一步查询系统及系统内进程的内存占用情况,做进一步排查分析。
案例 :
1、使用top命令定位异常进程。可以看见12836的CPU和内存占用率都非常高
此时可以再执行ps -ef | grep java,查看所有的java进程,在结果中找到进程号为12836的进程,即可查看是哪个应用占用的该进程。
-
使用top -H -p 进程号查看异常线程
-
使用printf “%x\n” 线程号将异常线程号转化为16进制
-
使用jstack 进程号|grep 16进制异常线程号 -A90来定位异常代码的位置(最后的-A90是日志行数,也可以输出为文本文件或使用其他数字)。可以看到异常代码的位置。
2、cpu load 过高原因以及排查
造成cpu load过高的原因.从编程语言层次上full gc次数的增大或死循环都有可能造成cpu load 增高
具体的排查一句话描述就是
首先要找到哪几个线程在占用cpu,之后再通过线程的id值在堆栈文件中查找具体的线程
寻找最占CPU的进程
通过命令 ps ux
通过top -c命令显示进程运行信息列表 (按键P按CPU占有资源排序)
# ps ux
#top -c
top -c#效果



寻找最耗CPU的线程
top -Hp 进程ID 显示一个进程ID的线程运行信息列表 (按键P按CPU占有资源排序)
如果该进程是java进程,需要具体查看是哪段代码造成的CPU负载过高,根据上述获得到的线程ID可以使用JDK下的jstack来查看堆栈。
由于在堆栈中线程id是用16进制表示的,因此可以将上述线程转化成16进制的表示。
jstack java进程id | grep 16进制的线程id -C5 --color
3、服务器的cpu使用率特别高
排查思路:
-使用top或者mpstat查看cpu的使用情况
mpstat -P ALL 2 1
-top找出占用高的进程ID
-查看进程占用线程数量,如java:
ps -eLf|grep java|wc -l
1065
线上故障排查全套路
线上故障主要会包括cpu、磁盘、内存以及网络问题,而大多数故障可能会包含不止一个层面的问题,所以进行排查时候尽量四个方面依次排查一遍。
同时例如 jstack、jmap 等工具也是不囿于一个方面的问题的,基本上出问题就是df、free、top 三连,然后依次jstack、jmap伺候,具体问题具体分析即可。
CPU
一般来讲我们首先会排查 CPU 方面的问题。CPU 异常往往还是比较好定位的。
原因包括业务逻辑问题(死循环)、频繁gc以及上下文切换过多。而最常见的往往是业务逻辑(或者框架逻辑)导致的,可以使用jstack来分析对应的堆栈情况。
使用 jstack 分析 CPU 问题
我们先用 ps 命令找到对应进程的pid(如果你有好几个目标进程,可以先用top看一下哪个占用比较高)。
接着用top -H -p pid来找到 CPU 使用率比较高的一些线程
top
然后将占用最高的 pid 转换为 16 进制printf ‘%x\n’ pid得到 nid

接着直接在 jstack 中找到相应的堆栈信息jstack pid |grep ‘nid’ -C5 –color

可以看到我们已经找到了 nid 为 0x42 的堆栈信息,接着只要仔细分析一番即可。
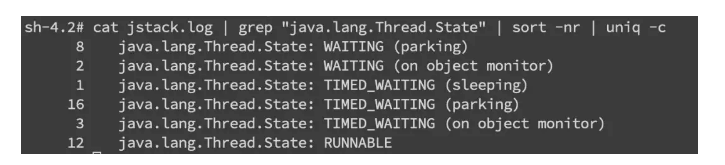
当然更常见的是我们对整个 jstack 文件进行分析,通常我们会比较关注 WAITING 和 TIMED_WAITING 的部分,BLOCKED 就不用说了。我们可以使用命令
cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c
来对 jstack 的状态有一个整体的把握,如果 WAITING 之类的特别多,那么多半是有问题啦。
频繁 gc
当然我们还是会使用 jstack 来分析问题,但有时候我们可以先确定下 gc 是不是太频繁,使用jstat -gc pid 1000命令来对 gc 分代变化情况进行观察,1000 表示采样间隔(ms),S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU 分别代表两个 Survivor 区、Eden 区、老年代、元数据区的容量和使用量。
YGC/YGT、FGC/FGCT、GCT 则代表 YoungGc、FullGc 的耗时和次数以及总耗时。如果看到 gc 比较频繁,再针对 gc 方面做进一步分析,具体可以参考一下 gc 章节的描述。
上下文切换
针对频繁上下文问题,我们可以使用vmstat命令来进行查看
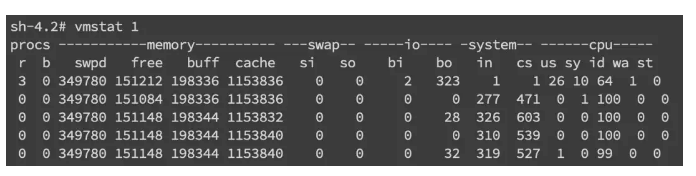
cs(context switch)一列则代表了上下文切换的次数。
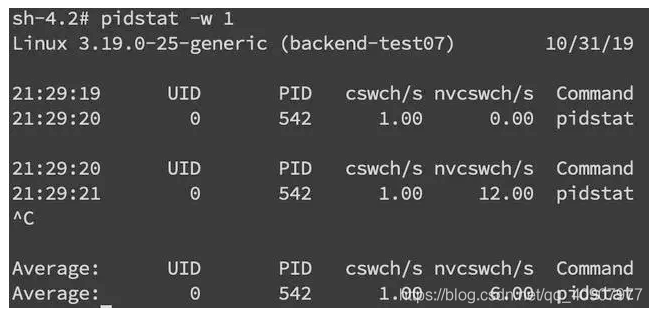
如果我们希望对特定的 pid 进行监控那么可以使用 pidstat -w pid命令,cswch 和 nvcswch 表示自愿及非自愿切换。
磁盘
磁盘问题和 CPU 一样是属于比较基础的。首先是磁盘空间方面,我们直接使用df -hl来查看文件系统状态

更多时候,磁盘问题还是性能上的问题。我们可以通过 iostat -d -k -x来进行分析
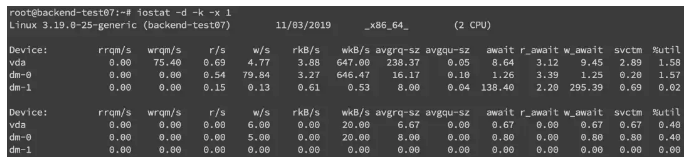
最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了。
另外我们还需要知道是哪个进程在进行读写,一般来说开发自己心里有数,或者用 iotop 命令来进行定位文件读写的来源。
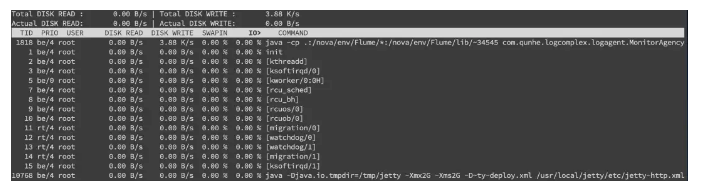
不过这边拿到的是 tid,我们要转换成 pid,可以通过 readlink 来找到 pidreadlink -f /proc/*/task/tid/…/…。

找到 pid 之后就可以看这个进程具体的读写情况cat /proc/pid/io
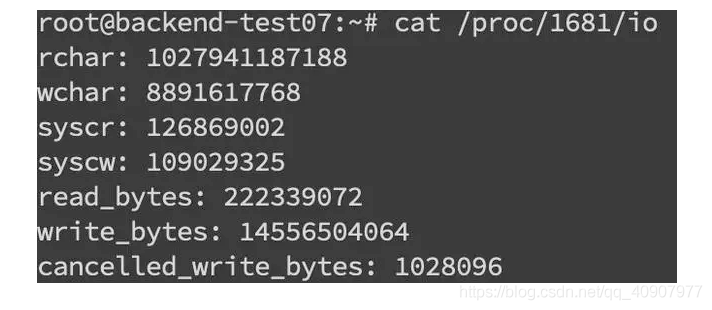
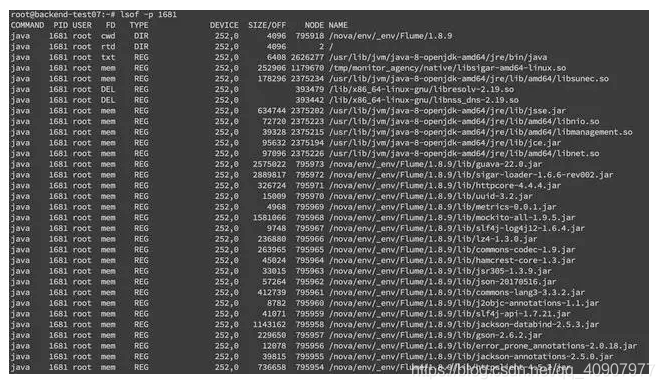
我们还可以通过 lsof 命令来确定具体的文件读写情况 lsof -p pid
内存
内存问题排查起来相对比 CPU 麻烦一些,场景也比较多。主要包括 OOM、GC 问题和堆外内存。一般来讲,我们会先用 free 命令先来检查一发内存的各种情况。

堆内内存
内存问题大多还都是堆内内存问题。表象上主要分为 OOM 和 Stack Overflow。
OOM
JMV 中的内存不足,OOM 大致可以分为以下几种:
Exception in thread “main” java.lang.OutOfMemoryError: unable to create new native thread
这个意思是没有足够的内存空间给线程分配 Java 栈,基本上还是线程池代码写的有问题,比如说忘记 shutdown,所以说应该首先从代码层面来寻找问题,使用 jstack 或者 jmap。如果一切都正常,JVM 方面可以通过指定Xss来减少单个 thread stack 的大小。另外也可以在系统层面,可以通过修改/etc/security/limits.confnofile 和 nproc 来增大 os 对线程的限制。
Exception in thread “main” java.lang.OutOfMemoryError: Java heap space
这个意思是堆的内存占用已经达到-Xmx 设置的最大值,应该是最常见的 OOM 错误了。解决思路仍然是先应该在代码中找,怀疑存在内存泄漏,通过 jstack 和 jmap 去定位问题。如果说一切都正常,才需要通过调整Xmx的值来扩大内存。
Caused by: java.lang.OutOfMemoryError: Meta space
这个意思是元数据区的内存占用已经达到XX:MaxMetaspaceSize设置的最大值,排查思路和上面的一致,参数方面可以通过XX:MaxPermSize来进行调整(这里就不说 1.8 以前的永久代了)。
Stack Overflow
栈内存溢出,这个大家见到也比较多。
Exception in thread “main” java.lang.StackOverflowError
表示线程栈需要的内存大于 Xss 值,同样也是先进行排查,参数方面通过Xss来调整,但调整的太大可能又会引起 OOM。
使用 JMAP 定位代码内存泄漏
上述关于 OOM 和 Stack Overflow 的代码排查方面,我们一般使用 JMAPjmap -dump:format=b,file=filename pid来导出 dump 文件

通过 mat(Eclipse Memory Analysis Tools)导入 dump 文件进行分析,内存泄漏问题一般我们直接选 Leak Suspects 即可,mat 给出了内存泄漏的建议。另外也可以选择 Top Consumers 来查看最大对象报告。
和线程相关的问题可以选择 thread overview 进行分析。除此之外就是选择 Histogram 类概览来自己慢慢分析,大家可以搜搜 mat 的相关教程。