一、什么是解释器模式
解释器(Interpreter)模式是一种对象的行为模式。给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
所谓“语言”,指的是使用规定格式和文法的一类字符组合。
所谓“文法”,简单点说就是我们俗称的“语法规则”。
以java语言为例,其变量声明文法为:[public|protected|private]+[static]+[final]+变量类型+变量名+[=初始值],以下这条字符串变量声明语句就是该文法的一种表示:private static final String sql=” select * from user where 1=1″ 。
解释器模式的本质:分离实现,解释执行
设计意图:为语言中的不同的文法表示,分别定义一个与该文法表示相对应的的解释器,然后通过这个解释器来对该文法表示进行解释。
二、解释器模式的结构
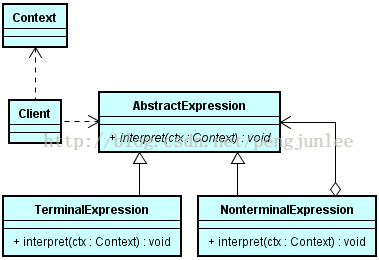
解释器模式涉及的角色及其职责如下:
抽象表达式(AbstractExpression)角色:约定解释器的解释操作,主要是一个interpret()方法。
终结符表达式(TerminalExpression)角色:用来实现文法中和终结符相关的解释操作,不再包含其它的解释器,如果用组合模式来构建抽象语法树的话,就相当于组合模式中的叶子对象,可以有多种终结符解释器。
非终结符表达式(NonterminalExpression)角色:用来实现文法中和非终结符相关的解释操作,通常一个解释器对应一个语法规则,可以包含其它的解释器,如果用组合模式来构建抽象语法树的话,就相当于组合模式中的组合对象,可以有多种非终结符解释器。
环境(Context)角色:也称“上下文”,常用HashMap来代替,通常包含解释器之外的一些全局信息(解释器需要的数据,或是公共的功能)。
客户端(Client)角色:构建文法表示的抽象语法树(Abstract Syntax Tree,该抽象语法树由终结符表达式和非终结符表达式的实例装配而成),并调用解释操作interpret()方法。
解释器模式结构示意源代码如下:
首先定义一个抽象表达式(AbstractExpression)角色,并在其中定义一个执行解释操作的接口,示例代码如下。
/**
* 抽象表达式
*/
public abstract class AbstractExpression {
/**
* 解释的操作
* @param ctx 上下文对象
*/
public abstract void interpret(Context ctx);
}抽象表达式(AbstractExpression) 的具体实现分两种:终结符表达式(TerminalExpression)和非终结符表达式
/**
* 终结符表达式
*/
public class TerminalExpression extends AbstractExpression {
@Override
public void interpret(Context ctx) {
// 实现与语法规则中的终结符相关联的解释操作
}
}/**
* 非终结符表达式
*/
public class NonterminalExpression extends AbstractExpression {
@Override
public void interpret(Context ctx) {
// 实现与语法规则中的非终结符相关联的解释操作
}
}再来看看环境(Context)的定义,示例代码如下。
/**
* 上下文,包含解释器之外的一些全局信息
*/
public class Context {
}最后来看看客户端的定义,示例代码如下。
/**
* 使用解释器的客户
*/
public class Client {
/**
* 主要按照语法规格对特定的句子构建抽象语法树
* 然后调用解释操作
*/
}以上示例代码很简单, 只是为了说明解释器模式实现的基本结构和各个角色的功能, 实际的解释逻辑并未写出。
三、解释器模式应用举例
假如我们要实现这么一个功能:加减法计算器。
计算器中参与运算的元素为a、b、c、d等…,这些元素都与具体的业务相关,我们不细追究其所代表的意义。现要实现:客户端指定一个公式,如“a+b-c”,“a+b+c-d”,计算器就可以计算出结果。
设计好的类图结构示意如下:
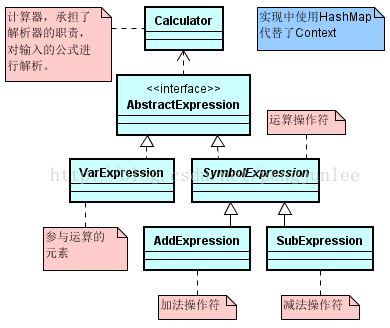
源代码如下。
import java.util.HashMap;
/**
* 抽象表达式,声明解释操作
*/
public interface AbstractExpression {
// 每个表达式都必须有一个解释操作
public int interprete(HashMap<String, Integer> var);
}import java.util.HashMap;
/**
* 终结符表达式,代表参加运算的元素对象
*/
public class VarExpression implements AbstractExpression {
private String key;
public VarExpression(String key) {
this.key = key;
}
public int interprete(HashMap<String, Integer> var) {
return (Integer) var.get(this.key);
}
}/**
* 非终结符表达式,运算符(此处为加法和减法)的抽象父类,真正的解释操作由其子类来实现
*/
public abstract class SymbolExpression implements AbstractExpression {
protected AbstractExpression left;
protected AbstractExpression right;
// 非终结符表达式的解释操作只关心自己左右两个表达式的结果
public SymbolExpression(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
}import java.util.HashMap;
/**
* 加法表达式
*/
public class AddExpression extends SymbolExpression {
public AddExpression(AbstractExpression left, AbstractExpression right) {
super(left, right);
}
// 把左右两个表达式运算的结果加起来
public int interprete(HashMap<String, Integer> var) {
return super.left.interprete(var) + super.right.interprete(var);
}
}import java.util.HashMap;
/**
* 减法表达式
*/
public class SubExpression extends SymbolExpression {
public SubExpression(AbstractExpression left, AbstractExpression right) {
super(left, right);
}
// 左右两个表达式相减
public int interprete(HashMap<String, Integer> var) {
return super.left.interprete(var) - super.right.interprete(var);
}
}import java.util.HashMap;
import java.util.Stack;
public class Calculator {
private AbstractExpression expression;
/**
* 对公式进行解析操作
*
* @param expStr
* 输入的公式
*/
public Calculator(String expStr) {
// 定义一个堆栈,安排运算的先后顺序
Stack<AbstractExpression> stack = new Stack<AbstractExpression>();
// 表达式拆分为字符数组
char[] charArray = expStr.toCharArray();
// 运算
AbstractExpression left = null;
AbstractExpression right = null;
for (int i = 0; i < charArray.length; i++) {
switch (charArray[i]) {
case '+': // 加法
left = stack.pop();
right = new VarExpression(String.valueOf(charArray[++i]));
stack.push(new AddExpression(left, right));
break;
case '-': // 减法
left = stack.pop();
right = new VarExpression(String.valueOf(charArray[++i]));
stack.push(new SubExpression(left, right));
break;
default: // 公式中的变量
stack.push(new VarExpression(String.valueOf(charArray[i])));
}
}
// 把运算结果抛出来
this.expression = stack.pop();
}
// 计算结果
public int calculate(HashMap<String, Integer> var) {
return this.expression.interprete(var);
}
}import java.util.HashMap;
public class Client {
public static void main(String[] args) {
// 构造运算元素的值列表
HashMap<String, Integer> ctx = new HashMap<String, Integer>();
ctx.put("a", 10);
ctx.put("b", 20);
ctx.put("c", 30);
ctx.put("d", 40);
ctx.put("e", 50);
ctx.put("f", 60);
Calculator calc = new Calculator("a+b-c");
int result = calc.calculate(ctx);
System.out.println("Result of a+b-c: " + result);
calc = new Calculator("d-a-b+c");
result = calc.calculate(ctx);
System.out.println("Result of d-a-b+c: " + result);
}
}运行程序打印结果如下:
Result of a+b-c: 0
Result of d-a-b+c: 40该加减法计算器示例与解释器模式组成元素对照如下:
①给定一种语言, 本例中就是一个简单的加减运算。
②定义一种文法表示,本例中就是指定的参与运算的元素(abcdef)以及运算符(+-),以及由它们构造而成的公式,如 d-a-b+c。
③给定一个解释器来解释语言中的句子:本例中的解释器是多个类的组合,包括Calculator和AbstractExpression 。
④TerminalExpression表示终结符表达式,相当于本例中的VarExpression。
⑤NonterminalExpression是非终结符表达式,相当于本例中的加法、减法。
四、解释器模式的适用性
解释器模式似乎使用面不是很广,它描述了一个语言解释器是如何构成的,在实际应用中,我们可能很少去构造一个语言的文法。
建议在以下情况中选用解释器模式:
当有一个语言需要解释执行,并且可以将语言中的句子表示为一个抽象语法树的时候,可以考虑使用解释器模式。
五、解释器模式的优缺点
解释器模式有以下优点:
1) 易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。
2) 易于扩展新的语法
正是由于采用一个解释器对象负责一条语法规则的方式,使得扩展新的语法非常容易。扩展了新的语法,只需要创建相应的解释器对象,在创建抽象语法树的时候使用这个新的解释器对象就可以了。
解释器模式有以下缺点:
不适合复杂的语法
如果语法特别复杂,构建解释器模式需要的抽象语法树的工作是非常艰巨的,再加上有可能会需要构建多个抽象语法树。所以解释器模式不太适合于复杂的语法,对于复杂的语法,使用语法分析程序或编译器生成器可能会更好一些。
六、相关模式
(1)解释器和组合模式
这两种模式可以组合使用。通常解释器模式都会使用组合模式来实现,这样能够方便地构建抽象语法树。一般非终结符解释器相当于组合模式中的组合对象,终结符解释器相当于叶子对象。
(2)解释器模式和迭代器模式
这两种模式可以组合使用。由于解释器模式通常使用组合模式来实现,因此在遍历整个对象结构时,可以使用迭代器模式。
(3)解释器模式和享元模式
这两种模式可以组合使用。在使用解释器模式的时候,可能会造成多个细粒度对象,如各式各样的终结符解释器,而这些终结符解释器对不同的表达式来说是一样的,是可以共用的,因此可以引入享元模式来共享这些对象。
(4)解释器模式和访问者模式
这两种模式可以组合使用。在解释器模式中,语法规则和解释器对象是有对应关系的。语法规则的变动意味着功能的变化。自然会导致使用不同的解释器对象;而且一个语法规则可以被不同的解释器解释执行。因此在构建抽象语法树的时候,如果每个节点所对应的解释器对象是固定的,这意味着该节点对应的功能是固定的,那么就不得不根据需要来构建不同的抽象语法树。为了让构建的抽象语法树较为通用,那就要求解释器的功能不要那么固定,要能很方便地改变解释器的功能,这个时候就变成了如何能够很方便地更改树形结构中节点对象的功能了,访问者模式可以很好的实现这个功能。
七、总结
解释器模式通过一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。