前言
负载均衡这个概念,几乎在所有支持高可用的技术栈中都存在,例如微服务、分库分表、各大中间件(MQ、Redis、MyCat、Nginx、ES)等,也包括云计算、云调度、大数据中也是炙手可热的词汇。
负载均衡策略主要分为静态与动态两大类:
-
静态调度算法:指配置后只会依据配置好的策略进行请求分发的算法。
-
动态调度算法:指配置后会根据线上情况(网络/CPU 负载/磁盘 IO 等)来分发请求。
但负载均衡算法数量并不少,本篇主要对于一些常用且高效的负载策略进行剖析。
基本的负载算法
如果聊到最基本的负载均衡算法,那么相信大家多少都有了解,例如:轮询、随机、权重等这类算法。特点就在于实现简单,先来快速过一遍基本的算法实现。
| 轮询算法
轮询算法是最为简单、也最为常见的算法,也是大多数集群情况下的默认调度算法,这种算法会按照配置的服务器列表,按照顺序依次分发请求,所有服务器都分发一遍后,又会回到第一台服务器循环该步骤。
// 服务类:主要用于保存配置的所有节点
public class Servers {
// 模拟配置的集群节点
public static List<String> SERVERS = Arrays.asList(
"44.120.110.001:8080",
"44.120.110.002:8081",
"44.120.110.003:8082",
"44.120.110.004:8083",
"44.120.110.005:8084"
);
}
// 轮询策略类:实现基本的轮询算法
public class RoundRobin{
// 用于记录当前请求的序列号
private static AtomicInteger requestIndex = new AtomicInteger(0);
// 从集群节点中选取一个节点处理请求
public static String getServer(){
// 用请求序列号取余集群节点数量,求得本次处理请求的节点下标
int index = requestIndex.get() % Servers.SERVERS.size();
// 从服务器列表中获取具体的节点IP地址信息
String server = Servers.SERVERS.get(index);
// 自增一次请求序列号,方便下个请求计算
requestIndex.incrementAndGet();
// 返回获取到的服务器IP地址
return server;
}
}
// 测试类:测试轮询算法
public class Test{
public static void main(String[] args){
// 使用for循环简单模拟10个客户端请求
for (int i = 1; i <= 10; i++){
System.out.println("第"+ i + "个请求:" + RoundRobin.getServer());
}
}
}
/******输出结果*******/
第1个请求:44.120.110.001:8080
第2个请求:44.120.110.002:8081
第3个请求:44.120.110.003:8082
第4个请求:44.120.110.004:8083
第5个请求:44.120.110.005:8084
第6个请求:44.120.110.001:8080
第7个请求:44.120.110.002:8081
第8个请求:44.120.110.003:8082
第9个请求:44.120.110.004:8083
第10个请求:44.120.110.005:8084上述案例中,整个算法的实现尤为简单,就是通过一个原子计数器记录当前请求的序列号,然后直接通过 % 集群中的服务器节点总数,最终得到一个具体的下标值,再通过这个下标值,从服务器 IP 列表中获取一个具体的 IP 地址。
轮询算法的优势:
-
算法实现简单,请求分发效率够高。
-
能够将所有请求均摊到集群中的每个节点上。
-
易于后期弹性伸缩,业务增长时可以拓展节点,业务萎靡时可以缩减节点。
轮询算法的劣势:
-
对于不同配置的服务器无法合理照顾,无法将高配置的服务器性能发挥出来。
-
由于请求分发时,是基于请求序列号来实现的,所以无法保证同一客户端的请求都是由同一节点处理的,因此需要通过 session 记录状态时,无法确保其一致性。
轮询算法的应用场景:
-
集群中所有节点硬件配置都相同的情况。
-
只读不写,无需保持状态的情景。
| 随机算法
随机算法的实现也非常简单,也就是当客户端请求到来时,每次都会从已配置的服务器列表中随机抽取一个节点处理。
// 随机策略类:随机抽取集群中的一个节点处理请求
public class Random {
// 随机数产生器,用于产生随机因子
static java.util.Random random = new java.util.Random();
public static String getServer(){
// 从已配置的服务器列表中,随机抽取一个节点处理请求
return Servers.SERVERS.get(random.nextInt(Servers.SERVERS.size()));
}
}上述该算法的实现,非常明了,通过 java.util 包中自带的 Random 随机数产生器,从服务器列表中随机抽取一个节点处理请求,该算法的结果也不测试了,大家估计一眼就能看明白。
随机算法的优势:个人看来该算法单独使用的意义并不大,一般会配合下面要讲的权重策略协同使用。
随机算法的劣势:
-
无法合理的将请求均摊到每台服务器节点。
-
由于处理请求的目标服务器不明确,因此也无法满足需要记录状态的请求。
-
能够在一定程度上发挥出高配置的机器性能,但充满不确定因素。
| 权重算法
权重算法是建立在其他基础算法之上推出的一种概念,权重算法并不能单独配置,因为权重算法无法做到请求分发的调度,所以一般权重会配合其他基础算法结合使用。
如:轮询权重算法、随机权重算法等,这样可以让之前的两种基础调度算法更为“人性化”一些。
权重算法是指对于集群中的每个节点分配一个权重值,权重值越高,该节点被分发的请求数也会越多,反之同理。
这样做的好处十分明显,也就是能够充分考虑机器的硬件配置,从而分配不同权重值,做到“能者多劳”。
public class Servers{
// 在之前是Servers类中再加入一个权重服务列表
public static Map<String, Integer> WEIGHT_SERVERS = new LinkedHashMap<>();
static {
// 配置集群的所有节点信息及权重值
WEIGHT_SERVERS.put("44.120.110.001:8080",17);
WEIGHT_SERVERS.put("44.120.110.002:8081",11);
WEIGHT_SERVERS.put("44.120.110.003:8082",30);
}
}
// 随机权重算法
public class Randomweight {
// 初始化随机数生产器
static java.util.Random random = new java.util.Random();
public static String getServer(){
// 计算总权重值
int weightTotal = 0;
for (Integer weight : Servers.WEIGHT_SERVERS.values()) {
weightTotal += weight;
}
// 从总权重的范围内随机生成一个索引
int index = random.nextInt(weightTotal);
System.out.println(index);
// 遍历整个权重集群的节点列表,选择节点处理请求
String targetServer = "";
for (String server : Servers.WEIGHT_SERVERS.keySet()) {
// 获取每个节点的权重值
Integer weight = Servers.WEIGHT_SERVERS.get(server);
// 如果权重值大于产生的随机数,则代表此次随机分配应该落入该节点
if (weight > index){
// 直接返回对应的节点去处理本次请求并终止循环
targetServer = server;
break;
}
// 如果当前节点的权重值小于随机索引,则用随机索引减去当前节点的权重值,
// 继续循环权重列表,与其他的权重值进行对比,
// 最终该请求总会落入到某个IP的权重值范围内
index = index - weight;
}
// 返回选中的目标节点
return targetServer;
}
public static void main(String[] args){
// 利用for循环模拟10个客户端请求测试
for (int i = 1; i <= 10; i++){
System.out.println("第"+ i + "个请求:" + getServer());
}
}
}
/********运行结果********/
第1个请求:44.120.110.003:8082
第2个请求:44.120.110.001:8080
第3个请求:44.120.110.003:8082
第4个请求:44.120.110.003:8082
第5个请求:44.120.110.003:8082
第6个请求:44.120.110.003:8082
第7个请求:44.120.110.003:8082
第8个请求:44.120.110.001:8080
第9个请求:44.120.110.001:8080
第10个请求:44.120.110.002:8081上面这个算法对比之前的基本实现,可能略微有些复杂难懂,我们先上个图:

仔细观看上图后,逻辑应该会清晰很多,大体捋一下思路:
-
先求和所有的权重值,再随机生成一个总权重之内的索引。
-
遍历之前配置的服务器列表,用随机索引与每个节点的权重值进行判断。如果小于,则代表当前请求应该落入目前这个节点;如果大于,则代表随机索引超出了目前节点的权重范围,则减去当前权重,继续与其他节点判断。
-
最终随机出的索引总会落入到一个节点的权重范围内,最后返回对应的节点 IP。
| 轮询权重算法
// 轮询权重算法
public class RoundRobinweight {
private static AtomicInteger requestCount = new AtomicInteger(0);
public static String getServer(){
int weightTotal = 0;
for (Integer weight : Servers.WEIGHT_SERVERS.values()) {
weightTotal += weight;
}
String targetServer = "";
int index = requestCount.get() % weightTotal;
requestCount.incrementAndGet();
for (String server : Servers.WEIGHT_SERVERS.keySet()) {
Integer weight = Servers.WEIGHT_SERVERS.get(server);
if (weight > index){
targetServer = server;
break;
}
index = index - weight;
}
return targetServer;
}
public static void main(String[] args){
for (int i = 1; i <= 10; i++){
System.out.println("第"+ i + "个请求:" + getServer());
}
}
}
/********运行结果*********/
第1个请求:44.120.110.001:8080
第2个请求:44.120.110.001:8080
第3个请求:44.120.110.001:8080
第4个请求:44.120.110.001:8080
第5个请求:44.120.110.001:8080
第6个请求:44.120.110.001:8080
第7个请求:44.120.110.001:8080
第8个请求:44.120.110.001:8080
第9个请求:44.120.110.001:8080
第10个请求:44.120.110.001:8080观察上述中的案例,此刻会发现出端倪,代码实现过程相同,但此刻的输出结果,竟然全部请求都被分发到了 44.120.110.001:8080 这个节点,这是为什么呢?
因为此时是通过请求序列号去进行判断的,所以最终效果会成为:
-
前 17 个请求会交给 44.120.110.001:8080 节点。
-
后续 11 个请求会交给 44.120.110.002:8081 节点。
-
最后 30 个请求会交给 44.120.110.003:8082 节点。
-
然后持续重复该过程…..
此时似乎离我们预期的负载效果发生了偏离,如果采用这种方案去实现轮询权重算法,最终会将一个集群变为单点服务,这显然并不是期待中的效果,因此需要一种新的方式去实现,那么又该如何去做呢?
此时需要牵扯到一种请求调度的高级算法:平滑加权轮询算法。
| 平滑加权轮询算法
平滑轮询加权算法的本质就是为了解决之前实现方式中所存在的问题,能够将请求均匀的按照权重值分发到每台机器。
这种算法设计的非常巧妙,实现过程也尤为有趣,我们一起来看看:
// 权重服务器的配置类
public class Servers {
public static Map<String, Integer> WEIGHT_SERVERS = new LinkedHashMap<>();
static {
// 权重值设置的略微小一点,方便后续理解算法
WEIGHT_SERVERS.put("44.120.110.001:8080",3);
WEIGHT_SERVERS.put("44.120.110.002:8081",2);
WEIGHT_SERVERS.put("44.120.110.003:8082",1);
}
}
// 权重类
public class Weight {
// 节点信息
private String server;
// 节点权重值
private Integer weight;
// 动态权重值
private Integer currentWeight;
// 构造方法
public Weight() {}
public Weight(String server, Integer weight, Integer currentWeight) {
this.server = server;
this.weight = weight;
this.currentWeight = currentWeight;
}
// 封装方法
public String getServer() {
return server;
}
public void setServer(String server) {
this.server = server;
}
public Integer getWeight() {
return weight;
}
public void setWeight(Integer weight) {
this.weight = weight;
}
public Integer getCurrentWeight() {
return this.currentWeight;
}
public void setCurrentWeight(Integer currentWeight) {
this.currentWeight = currentWeight;
}
}
public class RoundRobinWeight {
// 初始化存储每个节点的权重容器
private static Map<String,Weight> weightMap = new HashMap<>();
// 计算总权重值,只需要计算一次,因此放在静态代码块中执行
private static int weightTotal = 0;
static {
sumWeightTotal();
}
// 求和总权重值,后续动态伸缩节点时,再次调用该方法即可。
public static void sumWeightTotal(){
for (Integer weight : Servers.WEIGHT_SERVERS.values()) {
weightTotal += weight;
}
}
// 获取处理本次请求的具体服务器IP
public static String getServer(){
// 判断权重容器中是否有节点信息
if (weightMap.isEmpty()){
// 如果没有则将配置的权重服务器列表挨个载入容器
Servers.WEIGHT_SERVERS.forEach((servers, weight) -> {
// 初始化时,每个节点的动态权重值都为0
weightMap.put(servers, new Weight(servers, weight, 0));
});
}
// 每次请求时,更改动态权重值
for (Weight weight : weightMap.values()) {
weight.setCurrentWeight(weight.getCurrentWeight()
+ weight.getWeight());
}
// 判断权重容器中最大的动态权重值
Weight maxCurrentWeight = null;
for (Weight weight : weightMap.values()) {
if (maxCurrentWeight == null || weight.getCurrentWeight()
> maxCurrentWeight.getCurrentWeight()){
maxCurrentWeight = weight;
}
}
// 最后用最大的动态权重值减去所有节点的总权重值
maxCurrentWeight.setCurrentWeight(maxCurrentWeight.getCurrentWeight()
- weightTotal);
// 返回最大的动态权重值对应的节点IP
return maxCurrentWeight.getServer();
}
public static void main(String[] args){
// 使用for循环模拟6次请求
for (int i = 1; i <= 6; i++){
System.out.println("第"+ i + "个请求:" + getServer());
}
}
}
/********输出结果********/
第1个请求:44.120.110.001:8080
第2个请求:44.120.110.002:8081
第3个请求:44.120.110.001:8080
第4个请求:44.120.110.003:8082
第5个请求:44.120.110.002:8081
第6个请求:44.120.110.001:8080先看结果,对比之前的实现方式而言,该算法在分发请求时,确实均匀了很多很多。
而且请求分发的数量与我们配置的权重值也恰巧相符合:
-
44.120.110.001:8080:3 次
-
44.120.110.002:8081:2 次
-
44.120.110.003:8082:1 次
这是不是很神奇?如何做到的呢,接下来简单聊一下该算法的核心思想。
在之前的权重算法中,服务器列表中只有两个值:服务器 IP、对应的权重值,而在当前这种算法中,需要再引入一个动态权重值的概念。
所以我们再上述案例中,将服务器的列表抽象成了一个 Weight 类,在该类中除开原本的 servers、weight 之外,多添加了一个字段 currentWeight,用于记录每个节点的动态权重(该值是变化的)。
在该算法中,会先计算已配置的权重值总和,然后第一次请求,会初始化权重容器 weightMap,将每个配置的节点都封装成一个 Weight 对象,并将其动态权重值初始化为 0。
如下:
-
Weight(“server”:”44.120.110.001:8080″,”weight”:3,”currentWeight”:0)
-
Weight(“server”:”44.120.110.002:8081″,”weight”:2,”currentWeight”:0)
-
Weight(“server”:”44.120.110.003:8082″,”weight”:1,”currentWeight”:0)
OK,至此准备工作就绪,接下来是算法的核心过程,主要分为三步:
-
用原本的动态权重值加一次每个节点的静态权重值,计算出新的动态权重值。
-
遍历权重容器,找出动态权重值最大的节点,将其作为处理本次请求的节点。
-
用最大的动态权重值减去已配置的静态权重值总和,为一下轮分发做准备。
结合上述的算法过程和前面给出的案例,把整个过程摊开剖析一次:

上表中列出了六次请求的处理过程,整个过程到最后,动态权重值又会回归初始值:0,0,0,然后开启新的一轮计算,周而复始之,格外的神奇^_^。
平滑加权轮询算法也是应用最为广泛的轮询算法,在 Dubbo、Robbin、Nginx、Zookeeper 等一些集群环境中,当你配置了权重时,默认采用的就是该算法作为请求分发的策略。
一致性哈希算法
其实平滑加权轮询算法对于请求分发而言,是一种比较优秀的策略了,不过前面分析的所有策略,都存在一个致命问题:不能确保同一客户端的所有请求都分发在同一台服务器处理,因此无法实现有状态的请求。
好比最简单的登录功能,客户端发送请求登录成功,然后将其登录的状态保存在 session 中,结果客户端的第二次请求被分发到了另外一台机器。
由于第二台服务器 session 中没有相关的登录信息,因此会要求客户端重新登录,这显然造成的用户体验感是极差的,那么对于这种问题又该如何解决呢?
主要有两种方案:
-
采用外部中间件存储 session,例如 Redis,然后从 Redis 中获取登录状态。
-
采用特殊的请求分发策略,确保同一客户端的所有请求都会去到同一台机器上处理。
一致性哈希算法就是一种能够能够确保同一客户端的所有请求都会被分发到同一台机器的策略,不过一致性哈希算法依旧会存在问题,就是当集群中某个节点下线,或者集群出现拓展时,那么也会影响最终分发的目标机器。
所以一般一致性哈希算法并不能 100% 解决 session 一致性的问题,因此该算法一般很少用于网关层的请求分发,更多的场景是应用在分布式缓存等情况,接下来一起来看看。
| 通过其他分发算法实现缓存
在讲解一致性哈希算法之前,大家先来简单理解一下一致性哈希算法的产生背景。
先思考一个问题:假设目前单台缓存服务器无法承担外部的访问压力,此刻会如何去做呢?
答案是增加新的缓存服务器节点,拓展出一个集群对外提供服务。
好的,那问题又来了,现在缓存服务器是一个集群环境,此刻来了一个请求后该落入哪个节点呢?
假设采用轮询策略,那么写入 xxx 缓存信息的请求被分发到了第一个节点,客户端读取 xxx 时,请求又被分发到了第三个节点上,那么显然是读不到之前的缓存。
而且最关键的是,一般的轮询策略都是需要基于集群的节点数量进行请求分发的,因此集群中的节点一旦出现伸缩,最终会导致所有缓存内容全部失效。
就拿最基本的取模轮询来说,原本集群是 3 个节点,所以是基于取模 3 去分发请求,结果有台节点宕机了,成为了取模 2,那最后整个缓存系统分发请求完全乱套…..
如果采用随机策略…..,更不靠谱…..
因此在这种需求背景下,大名鼎鼎的一致性哈希算法问世了,一致性哈希算法其实也使用的取模方式,只是,刚才描述的取模轮询法是对服务器的数量进行取模,而一致性哈希算法是对 2^32 取模,什么意思呢?我们一点点来讲。
| 一致性哈希核心-哈希环
实现一致性哈希算法的核心结构在于哈希环,前面讲到过一致性哈希是基于 2^32 做取模。
那么首先可以将二的三十二次方想象成一个圆,这个圆总共由 2^32 个点组成,如下:
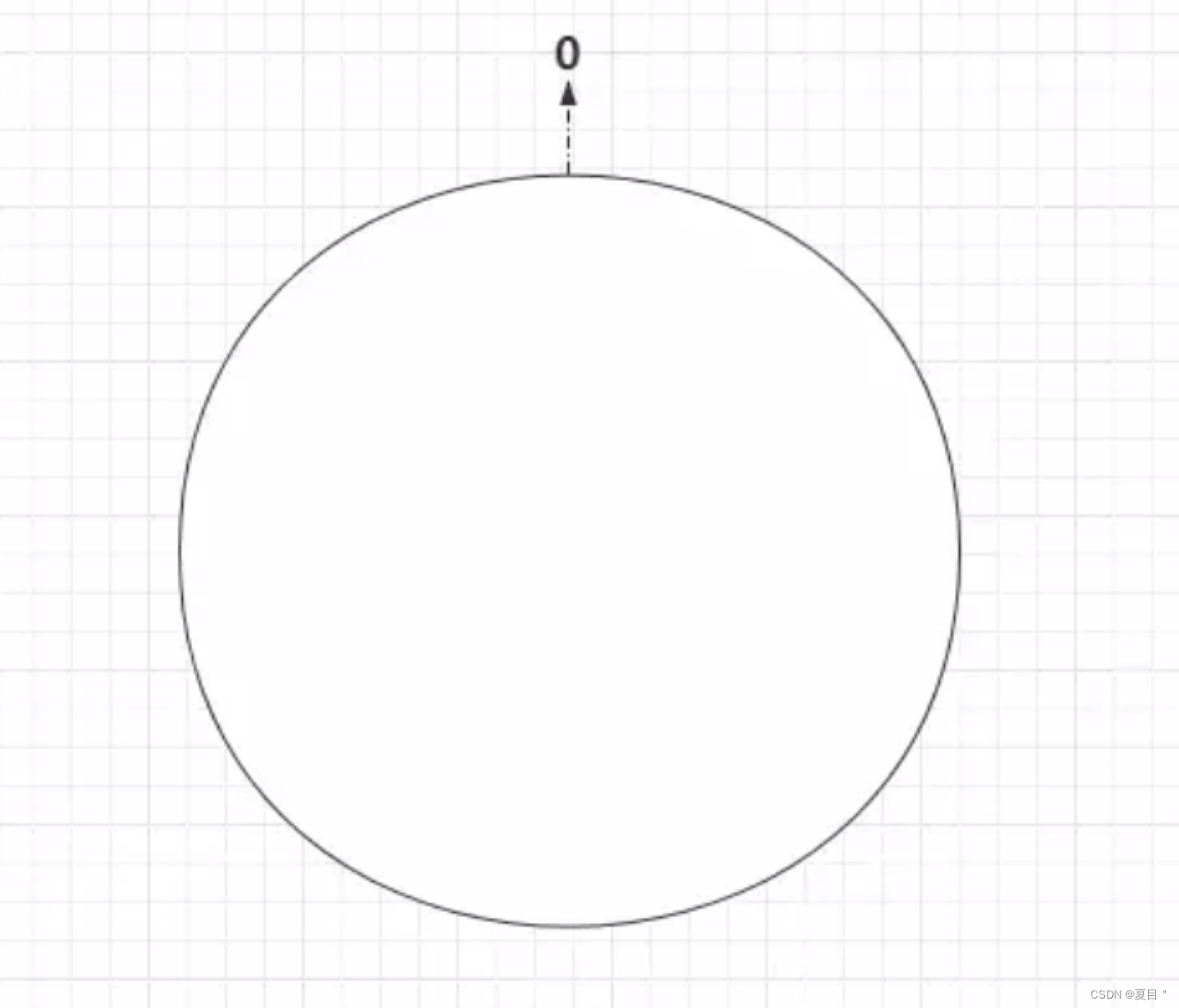
圆环的正上方第一个点代表 0,0 右侧的点按照 1、2、3、4….的顺序依此类推,直到 2^32-1,也就是说 0 左侧的第一个点代表着 2^32-1。
最终这个在逻辑上由 2^32 个点组成的圆,被称为哈希环。
结合之前的缓存案例,假设有四台缓存服务器 A、B、C、D,然后再通过每台服务器的 IP 哈希值取模 2^32,最终必然会得到一个 2^32 范围之内的整数,这个数在哈希环上定然也对应着一个点。
那么每台服务器的 IP 就可以映射到哈希环上,如下:
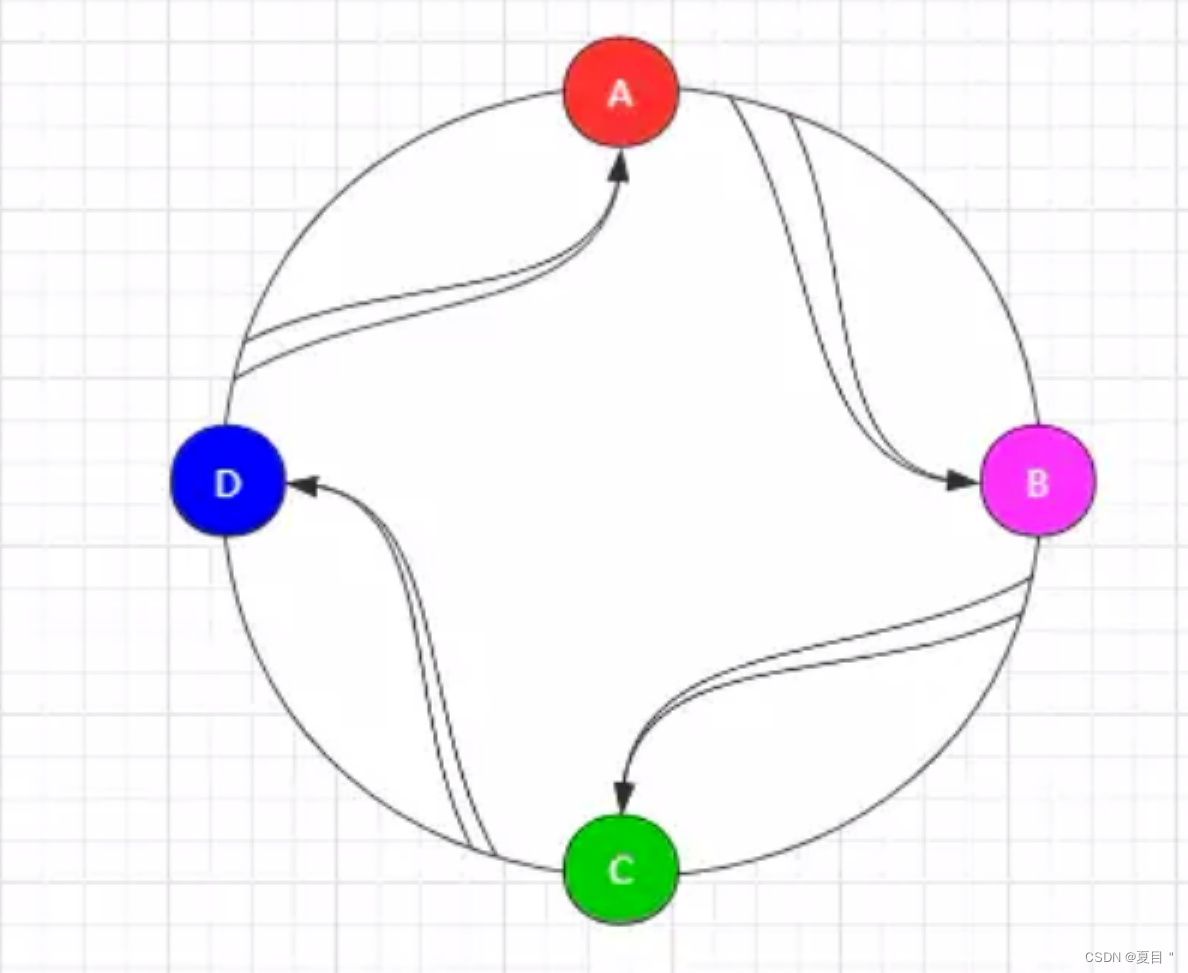
到此时,服务器已经和哈希环建立起了联系,那么此时当客户端发送请求时,又可以通过相同的计算方式,将客户端需要操作的缓存 Key 进行相同的哈希取模,然后同样将其映射到哈希环上。
例如写入一条缓存 name=竹子,如下:
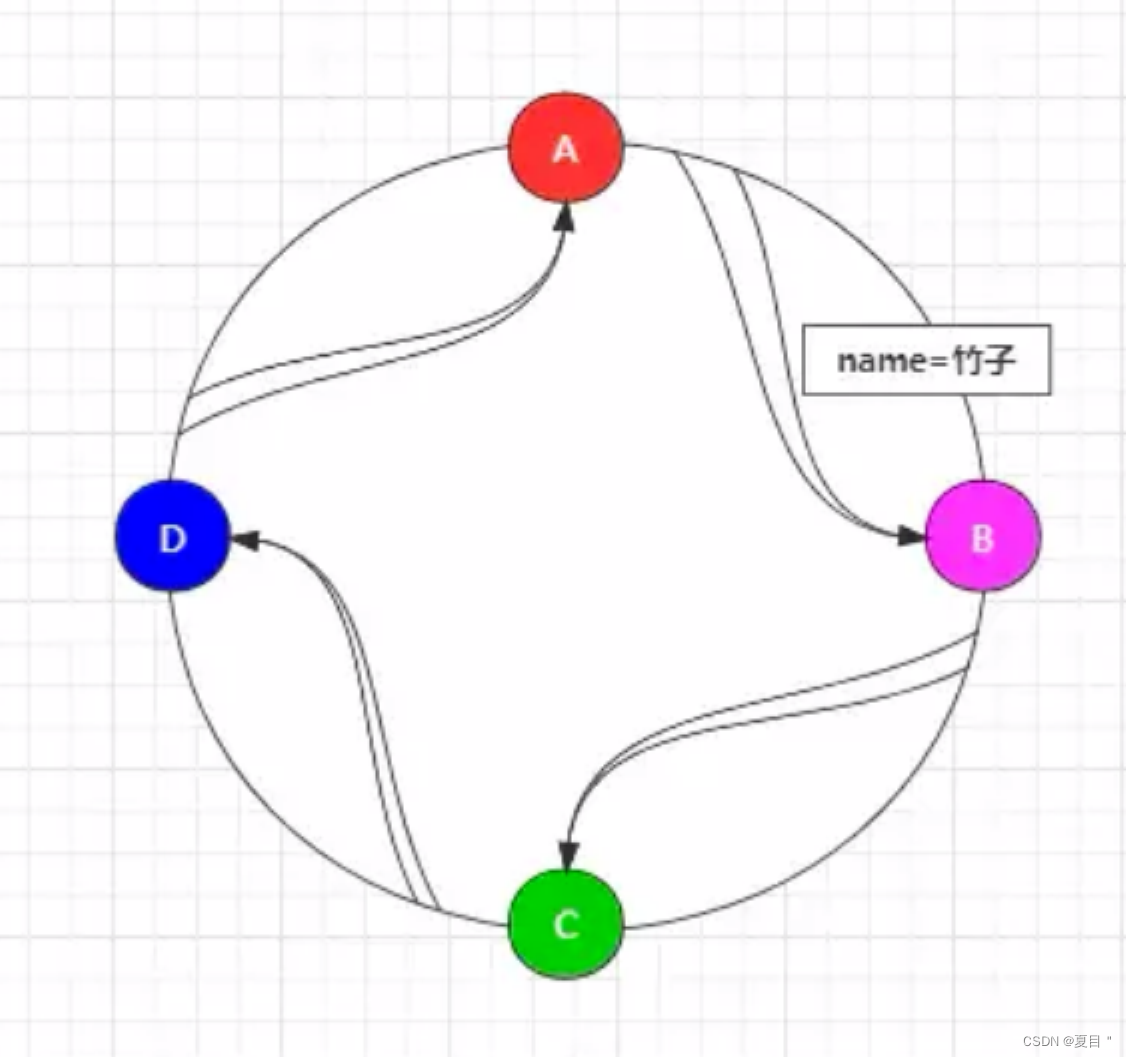
那么此时该缓存纠结要落入到哪台服务器呢?答案是 B,为什么?因为在哈希环结构中,沿着顺时针方向走,遇到的第一台服务器是 B,所以最终会落到 B 服务器上。
当然,如果一致性哈希算法被用于请求分发,那么就以用户的 IP 作为哈希取模的条件,这样就能确保同一个客户端的所有请求都会被分发到同一台服务器。
一致性哈希算法中,就利用哈希环结构+哈希取模判断每个请求该落入的服务器,由于服务器 IP、客户端 IP 或缓存的 Key 都是相同的,所以在服务器数量不变的情况,相同的哈希条件进行哈希取模,最终计算出来的值永远都是相同的。
然后再通过计算出的值,在哈希环结构上进行顺时针查找,能够定位到的服务器也是相同的,所以相同属性的请求永远会落入到同一服务器。
| 哈希环的映射偏移问题
经过上述分析后,好像发现一致性哈希算法没啥大毛病,但上述中属于“理想状态”,可偏偏理想很丰满,现实却很骨感,实际映射服务器 IP 的过程中,可能会出现如下情况
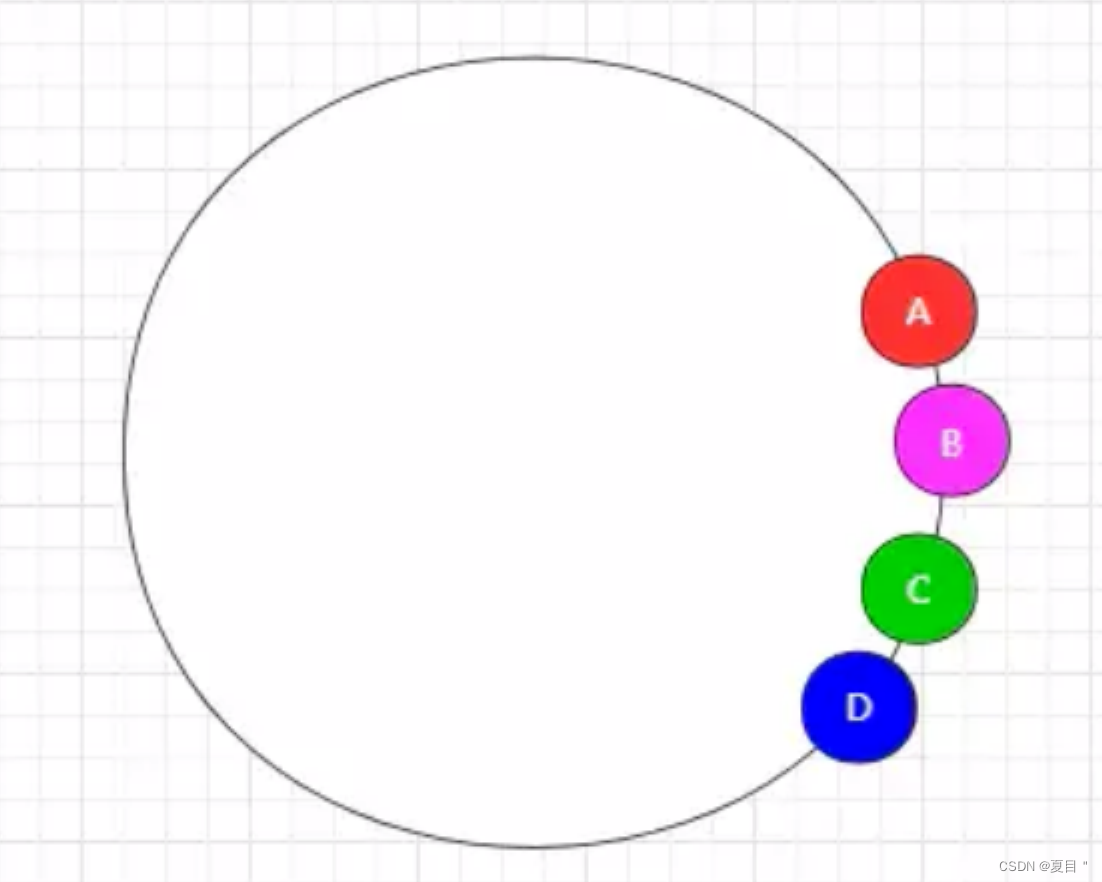
由于服务器 IP 哈希取模后,无法确保哈希得到的数字能够均匀分布,因此就有可能造成如上情况,所有的服务器IP都被映射在“一块儿”,最终导致 A 服务器承载了 90% 以上的访问压力。
| 映射偏移造成的宕机连锁反应
接上述,如果服务器 IP 映射在哈希环上出现偏移,在大流量的冲击下,这种情况很容易导致整个集群崩塌,首先是A扛不住并发冲击,宕机下线,紧接着流量交给 B,B 也扛不住,接着宕机,然后 C…..
因此哈希环映射偏移问题可能会造成的一系列连锁反应,所以在一致性哈希算法中,为了确保整个集群的健壮性,提出了一种虚拟节点的概念来解决此问题。
虚拟节点其实本质上就是真实服务器节点的复制品,虚拟节点映射的 IP 都是指向于真实服务器的。
就类似平时 .EXE 软件的快捷方式,现在为 QQ 创建了一个快捷方式,然后拷贝到了十个不同的目录下,但本质上这十个快捷方式指向的启动文件都是相同 exe 程序。
哈希环中的虚拟节点也同理,如下:
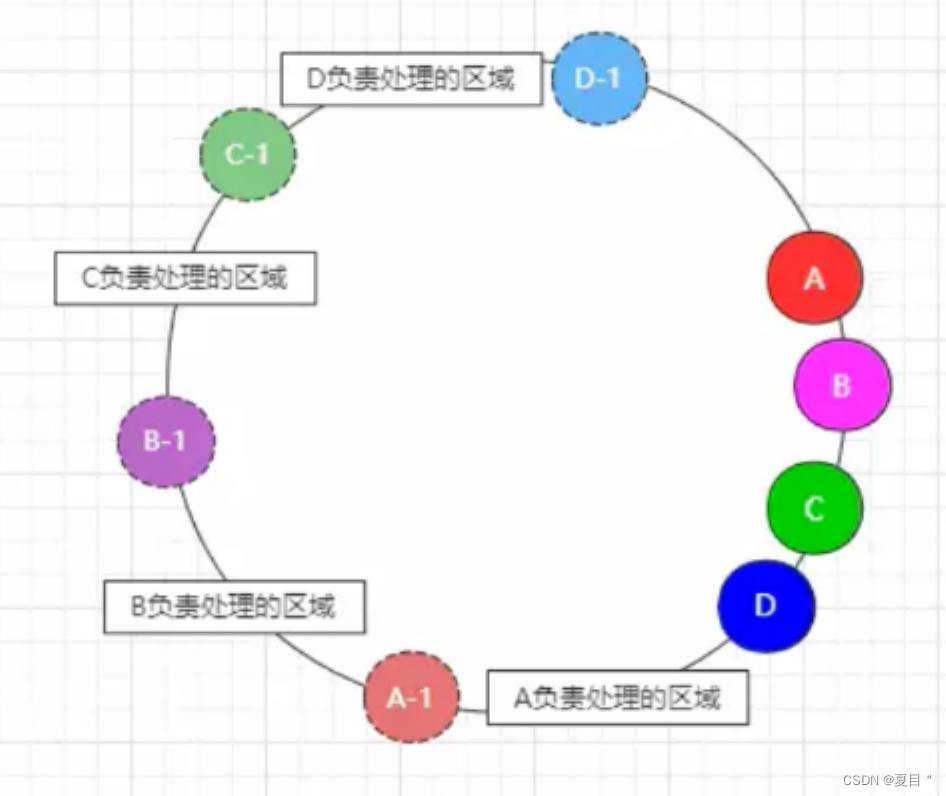
从上图中可以看出,A、B、C、D 四台服务器分别都映射出了一个虚拟节点,引入虚拟节点后会明显感觉出来,原本 A 服务器需要承载 90% 以上的流量,但此刻映射出的虚拟节点大大减轻了 A 的压力,将流量均摊到了集群中的每个节点。
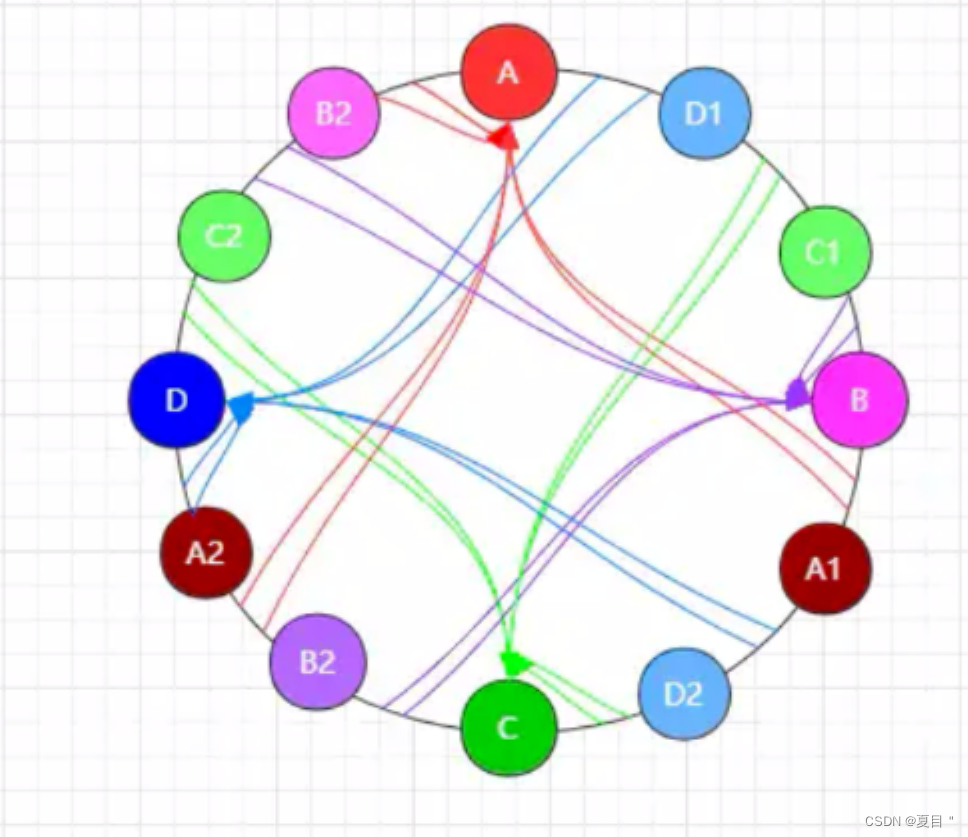
在一致性哈希算法的实际应用场景中,绝非只映射一个虚拟节点,往往会为一个真实节点映射数十个虚拟节点,以便于减小哈希环偏移所带来的影响。
同时,虚拟节点的数量越多,请求在分发时也能更均匀的分布,哈希环最终结构如下:
| Java 实现一致性哈希算法
讲了这么多,那么一致性哈希算法究竟如何实现呢?接下来一起看看:
public class Servers {
public static List<String> SERVERS = Arrays.asList(
"44.120.110.001:8080",
"44.120.110.002:8081",
"44.120.110.003:8082",
"44.120.110.004:8083",
"44.120.110.005:8084"
);
}
public class ConsistentHash {
// 使用有序的红黑树结构,用于实现哈希环结构
private static TreeMap<Integer,String> virtualNodes = new TreeMap<>();
// 每个真实节点的虚拟节点数量
private static final int VIRTUAL_NODES = 160;
static {
// 对每个真实节点添加虚拟节点,虚拟节点会根据哈希算法进行散列
for (String serverIP : Servers.SERVERS) {
// 将真实节点的IP映射到哈希环上
virtualNodes.put(getHashCode(serverIP), serverIP);
// 根据设定的虚拟节点数量进行虚拟节点映射
for (int i = 0; i < VIRTUAL_NODES; i++){
// 计算出一个虚拟节点的哈希值(只要不同即可)
int hash = getHashCode(serverIP + i);
// 将虚拟节点添加到哈希环结构上
virtualNodes.put(hash, serverIP);
}
}
}
public static String getServer(String IP){
int hashCode = getHashCode(IP);
// 得到大于该Hash值的子红黑树
SortedMap<Integer, String> sortedMap = virtualNodes.tailMap(hashCode);
// 得到该树的第一个元素,也就是最小的元素
Integer treeNodeKey = sortedMap.firstKey();
// 如果没有大于该元素的子树了,则取整棵树的第一个元素,相当于取哈希环中的最小元素
if (sortedMap == null)
treeNodeKey = virtualNodes.firstKey();
// 返回对应的虚拟节点名称
return virtualNodes.get(treeNodeKey);
}
// 哈希方法:用于计算一个IP的哈希值
public static int getHashCode(String IP){
final int p = 1904390101;
int hash = (int)1901102097L;
for (int i = 0; i < IP.length(); i++)
hash = (hash ^ IP.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
public static void main(String[] args){
// 用for循环模拟五个不同的IP访问
for (int i = 1; i <= 5; i++){
System.out.println("第"+ i + "个请求:" + getServer("192.168.12.13"+i));
}
System.out.println("-----------------------------");
// 用for循环模拟三个相同的IP访问
for (int i = 1; i <= 3; i++){
System.out.println("第"+ i + "个请求:" + getServer("192.168.12.131"));
}
}
}
/********输出结果*******/
第1个请求:44.120.110.002:8081
第2个请求:44.120.110.003:8082
第3个请求:44.120.110.004:8083
第4个请求:44.120.110.003:8082
第5个请求:44.120.110.004:8083
-----------------------------
第1个请求:44.120.110.002:8081
第2个请求:44.120.110.002:8081
第3个请求:44.120.110.002:8081
上述便是 Java 实现一致性哈希算法的全过程,其实并不难理解,里面用到了 TreeMap 实现了哈希环结构,并且指定了每个服务器节点的虚拟节点数量,同时实现了一个简单的哈希方法,用于计算入参的哈希值。
算法过程如下:
-
启动时先根据指定的数量,映射对应的虚拟节点数量在哈希环上。
-
通过计算客户端哈希值,然后在哈希环上取得大于该值的节点,然后返回对应的 IP。由于哈希环是取顺时针方向的第一个节点作为处理请求的目标服务器,所以获取大于该哈希值的节点中的第一个节点即可。
-
如果哈希环中没有大于客户端哈希值的节点,那么则将这些客户端的请求分发到整个 Map 上的第一台服务器,从此实现哈希闭环。
一致性哈希算法由于其特性,因此一般多被用于分布式缓存中的集群分片,尤其是 MemCache 的缓存分片,就是采用一致性哈希算法实现的。
而 Redis 自身推出的 RedisCluster 分片集群中,也借用了一致性哈希算法的思想,不过进行了改版实现,内部采用 CRC16+HashSolt 实现了缓存分片,但核心思想也是相同的。
当然,文中给出的算法过程都是较为简单的实现,如若想要参考完整的实现,可以参考 :
-
Dubbo 的 com.alibaba.dubbo.rpc.cluster.loadbalance 包
-
或参考 SpringCloudRibbon 的 com.netflix.loadbalancer 包下的实现
最小活跃数算法
上述分析的基本算法、平滑轮询加权、一致性哈希等算法都属于静态算法,也就是说这些算法配置后,并不会根据线上的实际运行情况进行调整,只会根据已配置的规则进行请求分发。
最小活跃数算法则会根据线上的实际情况进行分发,能够灵活的检测出集群中各个节点的状态,能够自动寻找并调用活跃度最低的节点处理请求。
// 节点类:用于封装集群中的每个节点
public class Server {
private String IP;
private AtomicInteger active;
// private Integer weight;
public Server(){}
public Server(String IP,int active) {
this.IP = IP;
// 将外部传递的活跃数作为默认活跃数
this.active = new AtomicInteger(active);
}
public String getIP() {
// 每分发一个请求时自增一次活跃数
active.incrementAndGet();
return IP;
}
public AtomicInteger getActive() {
return active;
}
}
// 集群类:用于模拟集群节点列表
public class Servers {
// 活跃度衰减器
public static void attenuator(){
new Thread(()->{
// 遍历集群中的所有节点
for (Server server : Servers.SERVERS) {
// 如果活跃度不为0
if (server.getActive().get() != 0){
// 则自减一个活跃度
server.getActive().getAndDecrement();
}
}
try {
// 每隔 2 秒中衰减一次活跃度
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
// 模拟的集群节点信息,活跃数最开始默认为0
public static List<Server> SERVERS = Arrays.asList(
new Server("44.120.110.001:8080",0),
new Server("44.120.110.002:8081",0),
new Server("44.120.110.003:8082",0)
);
}
// 最小活跃数算法实现类
public class LeastActive {
public static String getServer(){
// 初始化最小活跃数和最小活跃数的节点
int leastActive = Integer.MAX_VALUE;
Server leastServer = new Server();
// 遍历集群中的所有节点
for (Server server : Servers.SERVERS) {
// 找出活跃数最小的节点
if (leastActive > server.getActive().get()){
leastActive = server.getActive().get();
leastServer = server;
}
}
// 返回活跃数最小的节点IP
return leastServer.getIP();
}
public static void main(String[] args){
Servers.attenuator();
for (int i = 1; i <= 10; i++){
System.out.println("第"+ i + "个请求:" + getServer());
}
}
}
/********运行结果*********/
第1个请求:44.120.110.001:8080
第2个请求:44.120.110.002:8081
第3个请求:44.120.110.003:8082
第4个请求:44.120.110.001:8080
第5个请求:44.120.110.002:8081
第6个请求:44.120.110.003:8082
第7个请求:44.120.110.001:8080
第8个请求:44.120.110.002:8081
第9个请求:44.120.110.003:8082
第10个请求:44.120.110.001:8080
观察如上案例的运行结果,似乎结果好像是轮询的效果呀?确实是的,这是因为在最开始,所有节点的活跃数都为 0,三个节点的活跃数都相同。
所以默认会先取集群中的第一个活跃数为 0 的节点处理请求,第一个节点的活跃数会变成 1,第二次请求时最小活跃数也为 0,然后取第二个节点处理请求,依此类推……
在线上环境下,不会出现轮询的效果,因为每台服务器随着运行时间的增长,活跃数必然会不同,因此该算法总会取活跃数最小的节点提供服务。
当然,上述案例中实现的最小活跃数,是比较简易的版本,对于完善的实现可以参考 Dubbo 框架中的 com.alibaba.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance 类,其中也实现了权重机制。
简单阐述一下其中的原理实现:
-
先从注册中心中拉取所有的服务实例,然后找出活跃数最小的节点。
-
如果只有一个,那么则直接返回对应的实例节点处理本次请求。
-
如果存在多个,则根据每个节点配置的权重值来决定本次处理请求的具体节点。
-
如果权重值不同,优先选取权重值最大的实例,作为处理本次请求的节点。
-
如果存在相同的最大权重值,那么则通过随机的方式选择一个节点提供服务。
当然,由于需要对每个节点去实现活跃数监听,所以在 Dubbo 框架中,想要配置最小活跃数策略,那么需要首先启用 ActiveLimitFilter 记录每个节点的活跃数。
或者也可以参考 Ribbon 框架 com.netflix.loadbalancer 包下面的 BestAvailableRule 最小活跃数算法实现类。
从最小活跃数算法特性不难得知,该算法带来的优势极为明显,永远都能选取节点列表中最空闲的那台服务器处理请求,从而避免某些负载过高的节点,还依旧承担需要承担新的流量访问,造成更大的压力。
最优响应算法
与前面分析的最小活跃数算法一样,最优响应算法也是一种动态算法,但它比最小活跃数算法更加智能,因为最小活跃数算法中,如果一台节点存在故障,导致它自身处理的请求数比较少,那么它会遭受最大的访问压力,这显然是并不合理的。
最小活跃数算法就类似于平时的搬砖工作,谁事情做的最少谁留下来加班,在正常情况下,这种算法都能够找到“摸鱼”最厉害的员工留下来加班。
但如果有一天,某个员工由于身体出问题了,导致自己做的工作量比较少,但按照这种算法的逻辑,依旧会判定为该员工今天最闲,所以留下来加班。
从上述这个案例中,大家略微能够感受出来最小活跃数算法的不合理性。
而最优响应算法则更加智能,该算法在开始前,会对服务列表中的各节点发出一个探测请求(例如 Ping 或心跳包检测),然后根据各节点的响应时间来决定由哪台服务器处理客户端请求,该算法能较好根据节点列表中每台机器的当前运行状态分发请求。
public class Servers {
// 模拟的集群节点信息,活跃数最开始默认为0
public static List<Server> SERVERS = Arrays.asList(
new Server("44.120.110.001:8080"),
new Server("44.120.110.002:8081"),
new Server("44.120.110.003:8082")
);
}
public class Server {
private String IP;
public Server(){}
public Server(String IP) {
this.IP = IP;
}
public String getIP() {
return IP;
}
public void setIP(String IP){
this.IP = IP;
}
public String ping(){
// 生成一个1000~3000之间的随机数
int random = ThreadLocalRandom.current().nextInt(1000, 2000);
try {
// 随机休眠一段时间,模拟不同的响应速度
Thread.sleep(random);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 最后返回自身的IP
return this.IP;
}
}
public class ResponseTime {
// 创建一个定长的线程池,用于去执行ping任务
static ExecutorService pingServerPool =
Executors.newFixedThreadPool(Servers.SERVERS.size());
public static String getServer() throws InterruptedException {
// 创建一个CompletableFuture用于拼接任务
CompletableFuture cfAnyOf;
// 创建一个接收结果返回的server节点对象
final Server resultServer = new Server();
// 根据集群节点数量初始化一个异步任务数组
CompletableFuture[] cfs = new CompletableFuture[Servers.SERVERS.size()];
// 遍历整个服务器列表,为每个节点创建一个ping任务
for (Server server : Servers.SERVERS) {
// 获取当前节点在集群列表中的下标
int index = Servers.SERVERS.indexOf(server);
// 为每个节点创建一个ping任务,并交给pingServerPool线程池执行
CompletableFuture<String> cf =
CompletableFuture.supplyAsync(server::ping,pingServerPool);
// 将创建好的异步任务加入数组中
cfs[index] = cf;
}
// 将创建好的多个Ping任务组合成一个聚合任务并执行
cfAnyOf = CompletableFuture.anyOf(cfs);
// 监听执行完成后的回调,谁先执行完成则返回谁
cfAnyOf.thenAccept(resultIP -> {
System.out.println("最先响应检测请求的节点为:" + resultIP);
resultServer.setIP((String) resultIP);
});
// 阻塞主线程一段时间,防止CompletableFuture退出
Thread.sleep(3000);
// 返回最先响应检测请求(ping)的节点作为本次处理客户端请求的节点
return resultServer.getIP();
}
public static void main(String[] args) throws InterruptedException {
for (int i = 1; i <= 5; i++){
System.out.println("第"+ i + "个请求:" + getServer());
}
}
}
/******运行结果:******/
最先响应检测请求的节点为:44.120.110.002:8081
第1个请求:44.120.110.002:8081
最先响应检测请求的节点为:44.120.110.002:8081
第2个请求:44.120.110.002:8081
最先响应检测请求的节点为:44.120.110.003:8082
第3个请求:44.120.110.003:8082
最先响应检测请求的节点为:44.120.110.003:8080
第4个请求:44.120.110.001:8080
最先响应检测请求的节点为:44.120.110.002:8081
第5个请求:44.120.110.002:8081在该案例中,其实现过程对比之前的算法略微复杂一些,首先在 Server 实例类中定义了一个 Ping() 方法,该方法中使用随机数+线程休眠的方式简单模拟了一下节点的不同的响应速度。
然后在算法实现类中,利用 CompletableFuture 分别对每一个节点都创建了对应的 Ping 任务,然后同时执行,又通过 thenAccept() 回调方法监听了执行结果,谁最先响应,则取其作为处理本次请求的节点。
这个算法的实现过程中,唯一难理解的就是 CompletableFuture,它是 JDK8 中推出的一种异步任务。
这里只是举例实现,所以通过 CompletableFuture 实现了检测请求,但实际过程中如果要选择这种算法,那么基于 Netty 会更为合适。
从上述案例的运行结果中也可以得知:最优响应算法无论在何种情况下,都能从集群中选取性能最好的节点对外服务,Nginx 中也支持配置这种算法,但需要先安装对应的 nginx-upstream-fair 模块。
总结
在本文中,对于比较常用的请求分发算法进行了剖析及手写实践,其中提到了较为传统的静态调度算法:轮询、随机、加权、一致性哈希等,也谈到了一些较为智能的动态算法:最小活跃数、最优响应等。
但需要牢记的一点是:并非越智能的算法越好,越是并发高、流量大的场景下,反而选用最基本的算法更合适,例如微信的红包业务,就是采用最基本的轮询算法进行集群调度。
那这又是为何呢?因为越智能的调度算法,进行节点选择时的开销会更大,如果你对于文中给出的调度算法实现都一一运行过,那么大家会明显感知出:越到后面的算法,分发请求的速度越慢。
因此在面临巨大访问压力的情景中,选择最简单的算法反而带来的收益更高,但前提是需要集群中所有的节点硬件配置都一致,所有节点分配的资源都相同,轮询算法则是最佳的调度算法。