什么是归一化
把预处理的数据映射到 [ 0 , 1 ] [0,1] [0,1] 或 [ − 1 , 1 ] [-1,1] [−1,1] 之间的小数来处理。
为什么要归一化
维基百科的解释:
1. 归一化后加快了梯度下降求最优解的速度;
如果不进行归一化,由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长。
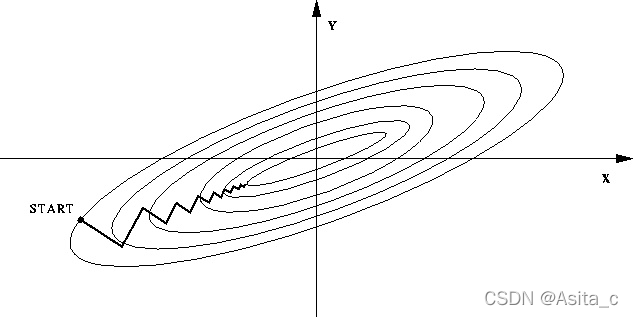
如果进行归一化以后,目标函数会呈现比较“圆”,这样训练速度大大加快,少走很多弯路。
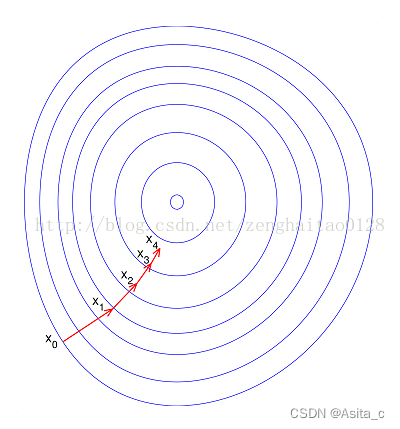
2. 归一化有可能提高精度;
归一化不同量纲的数据统一到一个标准,减少了不同指标之间量纲的影响。
常用的归一化方式:
- 最值归一化:
x ′ = x − X m i n X m a x − X m i n x’ = \frac{x-X_{min}}{X_{max}-X_{min}} x′=Xmax−Xminx−Xmin - 标准差差(Z-score)归一化:
x ′ = x − μ M a x V a l u e − M i n V a l u e x’ = \frac{x-μ}{MaxValue -MinValue} x′=MaxValue−MinValuex−μ - 非线性归一化:
(1)对数函数转换:y = log10(x)
(2)反余切函数转换:y = atan(x) * 2 / π
StandardScaler
作用:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。
scale_x = StandardScaler()
scale_data = scale_x.fit_transform(data)