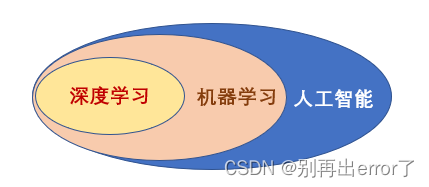
1、人工智能、机器学习、深度学习之间的关系
总的来说,深度学习时机器学习的一个子类,而机器学习又是人工智能的一个子类。
人工智能是一个非常宽泛的概念,它可以代指任何形式的蕴含某些智能特性的技术,并非特指某一特定技术领域。而机器学习则指一个特定领域,用于指代人工智能的一个特定类别。而进一步的,机器学习也包含很多技术,深度学习就是其中之一。
2、什么是机器学习?
简单地说,机器学习其实就是一种对数据的建模技术,(就我个人看来也像是一种数据处理的算法模型),是一种从数据抽象出模型的技术。数据可以是各种信息,如文档、图像等等,模型就是机器学习的产物。
//就我个人的理解来看,机器学习就是通过海量的数据集合,来对你所建立的模型进行训练,使其达到一个预期的效果,最终生成一个可靠的模型。
 在完成一个模型的建模之后,可以完成推理。(即根据新的数据输入,通过模型后得到一个输出)。而训练数据和输入数据之间存在的差异是机器学习面临的结构下挑战,也是一切问题的根源。
在完成一个模型的建模之后,可以完成推理。(即根据新的数据输入,通过模型后得到一个输出)。而训练数据和输入数据之间存在的差异是机器学习面临的结构下挑战,也是一切问题的根源。
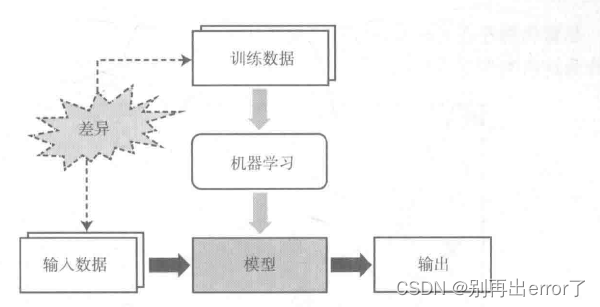
训练数据与输入数据有时差异巨大
机器学习无法基于错误的训练数据来实现预期目标,就像给新生的婴儿几个苹果,一会儿告诉你是苹果,一会儿告诉你是梨子,一会儿又说是西瓜,他永远不会知道到底什么是苹果。所以,获取能够充分反应实际领域据特征的无偏训练数据至关重要。
这里需要提到一个概念,泛化(generalization):确保模型对于训练数据与输入数据能够获得一致性能的处理过程。机器学习能否成功很大程度上取决于泛化的有效程度。
3、机器学习的常见问题之 过拟合
泛化过程失效的主要诱因之一就是 过拟合。这是一个训练模型时十分常见的问题。下面举一个例子进行简单的描述。
例如,我们需要利用机器学习对两类数据点进行分类。我们以两类数据的特征坐标画出一幅散点图:
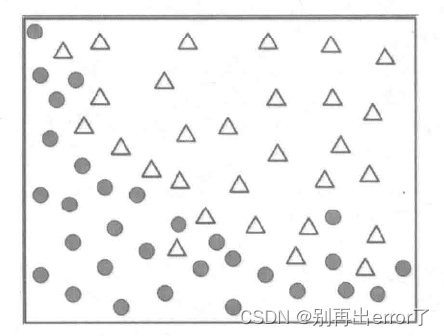
此时我们需要建立一个模型对两者进行分类,实际上也就是得到一条区分两者的边界
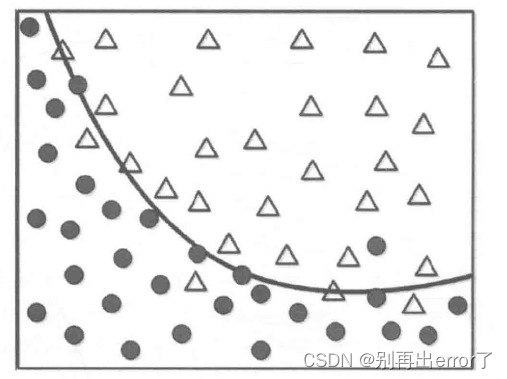
如图所示,虽然存在一定的数据点偏离,但曲线似乎是一条比较合理的边界。
如果我们要以完美的边界对所有数据点进行划分呢?能否正确地反映普适的行为特征呢?
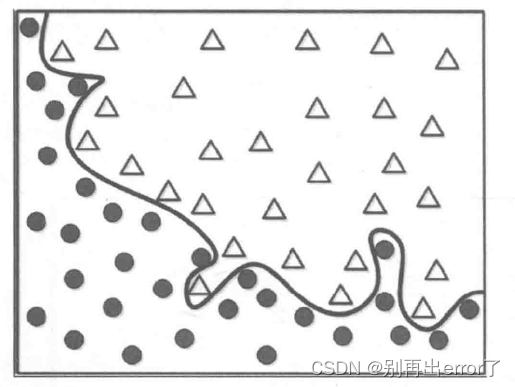
完美的边界如上图所示,针对这样的模型,如果有一个新的数据(正方形)输入,能否得到一个准确的划分呢?

这个完美的边界模型将黑色方形划分为△,但实际上它应该属于黑色圆更加合理,为什么对训练数据的100%准确率匹配会产生问题呢?
其实,在大量的训练数据中,存在的大量的噪声,就比如上述的一些偏离了的数据点。但机器学习无法区分噪声,如果过分要求区分所有训练集数据,他将会生成一个不合理的模型,而对后续所需要判定的实际数据的判定产生误差。
如果认为训练数据中的每一个元素都是准确的,并且精准匹配模型,这将会得到一个普适性较低的模型,这就是过拟合。就比如,你拿出三个苹果,十分强硬地和婴儿宝宝说这就是苹果,其他的就算很像也不是苹果,只有这三个才是苹果。这样,如果再拿来一个新的没有见过的苹果,婴儿宝宝也会觉得这个东西不是刚见过的苹果,所以判断失误,这其实就是过拟合的概念。
4、如何克服过拟合?
这里介绍两种克服过拟合问题的典型方法:正则化和验证。
(1)正则化:是一种力求构建极简模型的数值方法。精简后的模型能以较小的性能代价,避免过拟合的影响。类似于前文讨论的例子,复杂的曲线更倾向于过拟合。而简单的曲线虽然未能正确划分部分数据点,但能更加好的反映总体特征。
(2)验证:验证是指预留一部分训练数据,并利用其监控模型性能的过程。验证数据集不参与训练过程。如果训练过程所生成的模型对预留输入数据的处理效果不佳,则认为存在过拟合。
验证的方法十分常见,也拿之前说的认识苹果来说,相当于你在教婴儿“这2个是苹果”之后,再拿出另一个苹果出来,如果婴儿宝宝能认出来也是苹果,说明教的效果好,反之如果不认识,那就是过拟合的意思了。
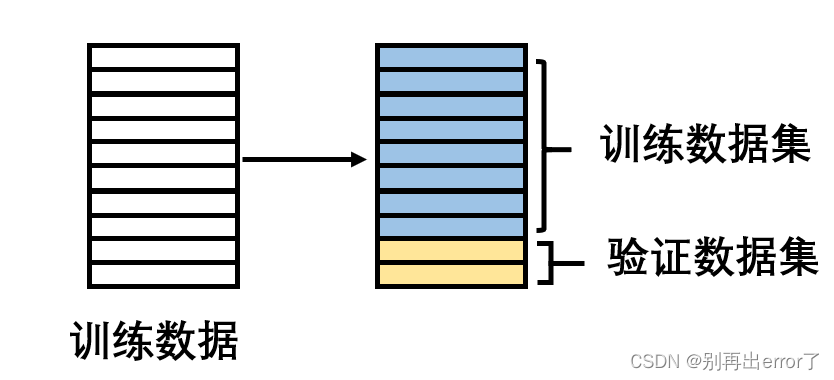
在利用验证技术的机器学习过程包括以下几步:
(1)将训练数据分为两组:一组用于训练,另一组用于验证。根据经验规律,训练数据与验证数据的比例为8:2;
(2)使用训练数据对模型进行训练;
(3)利用验证数据评估模型效果。如果效果满意。结束训练;如果效果不显著,修改模型重新进行训练。
这里再介绍一种验证方法——交叉验证
简单的说,交叉验证就是不保留数据的原始划分,而是重复划分数据。比例一定,但数据划分范围不同,是从训练过程中随机选出的。
5、机器学习的类型
主要分以下三个大类:
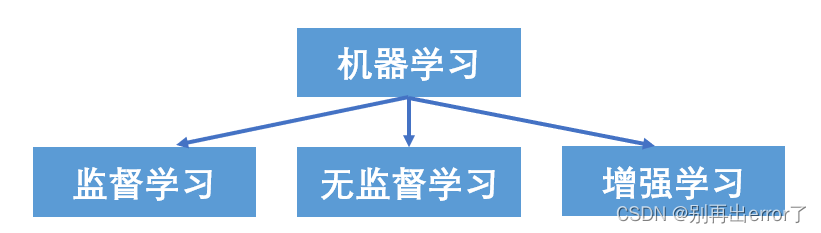
监督学习的应用最为广泛。在监督学习中,每个训练数据集均由输入与标准输出构成的数据对构成。标准输出是模型对该输入应生成的预期结果。
{ input , correct output }
类似于之前的教婴儿认识苹果,苹果这个物体就是数据,它包含苹果的各种特征,比如颜色、大小、触感等等,对用的输出结果就是苹果,婴儿需要学会通过大脑收集到的信息对其进行判断。这就是监督学习。
而在无监督学习中,训练数据仅包含输入,而不包含标准输出。
{ input }
无监督学习通常用于分析数据的特征,并对数据进行预处理。再类比于教婴儿学习苹果,无监督学习相当于没有人告诉宝宝啥是苹果和梨子,而是把一堆水果塞给宝宝,让他自己根据特征分出两个种类,这个过程就相当于提取物体的关键特征。
增强学习利用输入、某些输出以及评分组成的数据集作为训练数据。它通常用在需要优化折中的情况,例如控制和博弈问题。
{ input,some output, grade for this output }
6、分类和回归
监督学习最常见的两类应用就是分类(classification)和回归(regression)。
分类可以说是最主流的应用了,它所关注的就是寻找数据所属的类别。比如数字识别、面部识别等等。类似的,分类问题的训练数据如下
{ input , class} //class 种类即对应这数据的标准输出。
回归不判定类别,而是预测数值。针对对以后数据的学习,得到一个模型,可对新输入的数据进行值的预测。比如天气预测、股票预测等等。
总之,分类是分析研究利用模型来判别输入数据属于哪一种类别;回归是分析利用模型来估计数据的趋势。