mysql数据库是当前应用最为的广泛的数据库,在实际工作中也经常接触到。真正用好mysql也不仅仅是会写sql就行,更重要的是真正理解其内部的工作原理。本文先从宏观角度介绍一些mysql相关的知识点,目的是为了让大家对mysql能有一个大体上的认知,后续再逐一对每个知识点的进行深入解读。
本文主要内容是根据掘金小册《从根儿上理解 MySQL》整理而来。如想详细了解,建议购买掘金小册阅读。
通信方式
mysql采用了典型的客户端/服务器架构(C/S架构)模式。对于计算机而言,数据库客户端程序和服务器程序分别运在不同的进程中。所以客户端进程向服务器进程发送sql请求并得到返回结果的过程本质上就是进程间通信。mysql支持的进程间通信方式包括TCP/IP、命名管道、共享内存、unix域套接字文件。
TCP/IP: 如果服务端进程和客户端进程运行在不同的主机中,只能通过TCP/IP网络通信协议进行通信。mysql服务器启动时监听某个端口(默认3306),等待客户端进程来连接。当然,服务端进程和客户端进程在同一主机中,通过本机回环地址(127.0.0.1)也是可以使用TCP/IP进行通信的。命名管道或共享内存: 如果服务端进程和客户端进程都运行在一台windows主机上,可以通过命名管道或共享内存方式进行通信。- 使用
命名管道来进行进程间通信: 需要在启动服务器程序的命令中加上--enable-named-pipe参数,然后在启动客户端程序的命令中加入--pipe或者--protocol=pipe参数。 - 使用
共享内存来进行进程间通信: 需要在启动服务器程序的命令中加上--shared-memory参数,在成功启动服务器后,共享内存便成为本地客户端程序的默认连接方式,不过我们也可以在启动客户端程序的命令中加入--protocol=memory参数来显式的指定使用共享内存进行通信。
- 使用
Unix域套接字文件: 如果我们的服务器进程和客户端进程都运行在同一台操作系统为类Unix的机器上的话,我们可以使用Unix域套接字文件来进行进程间通信。
真实环境中,服务器和客户端基本都是运行在不同主机中的,它们之间采用的通信方式就是TCP/IP。
一条查询sql的基本处理过程
不论客户端进程和服务器进程是采用哪种方式进行通信,最后实现的效果都是:客户端向服务器发送一段文本(sql语句),服务器进程处理后再向客户端进程发送一段文本(处理结果)。下面以查询sql为例,简单说明一下服务器处理客户端请求的大致处理过程。
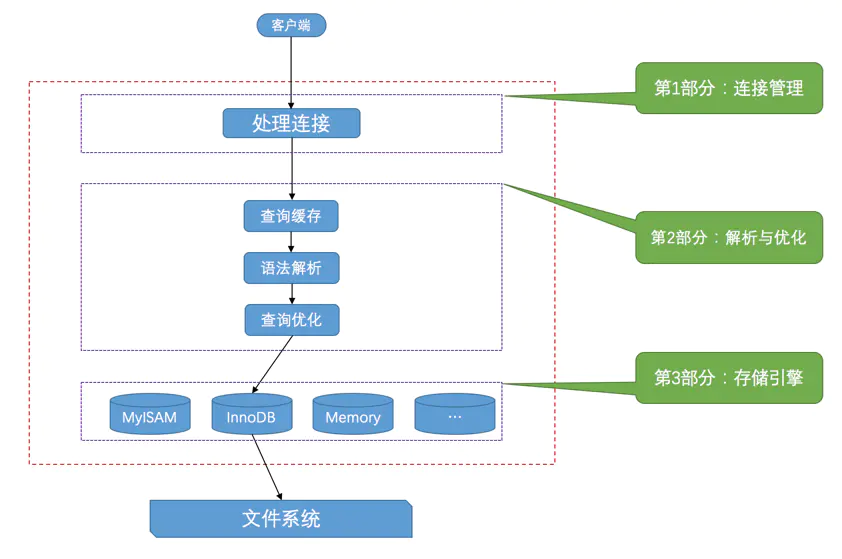
从图中我们可以看出,服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别是连接管理、解析与优化、存储引擎。
连接管理
每当有一个客户端连接到服务器时,服务器都会创建一个线程来专门处理与这个客户端的交互。在客户端程序发起连接的时候,需要携带主机信息、用户名、密码,服务器程序会对客户端程序提供的这些信息进行认证,如果认证失败,服务器程序会拒绝连接。
当连接建立后,与该客户端关联的服务器线程会一直等待客户端发送请求,MySQL服务器接收到的请求只是一个文本消息,该文本消息还要经过各种处理才能将最后的处理结果返回客户端。
解析与优化
到现在为止,MySQL服务器已经获得了文本形式的请求,接着还需要经过查询缓存、语法解析、查询优化等进行处理。
查询缓存
如果服务器开启了查询缓存,在执行查询的时候会先从查询缓存中获取查询结果。如果命中缓存则直接返回结果,否则接着执行。mysql不推荐使用查询缓存,并且在8.0版本已经移除此功能。真实环境中也不会使用,因此不用详细了解。
语法解析
这一步主要做的事情是对语句基于SQL语法进行词法和语法分析和语义的解析,将要查询的表、各种查询条件都提取出来放到MySQL服务器内部使用的一些数据结构上来。
查询优化
因为我们写的MySQL语句执行起来效率可能并不是很高,MySQL的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等等。优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序等。我们可以使用EXPLAIN语句来查看某个语句的执行计划。
存储引擎
mysql数据是保存在数据表里面,但表只是逻辑上的概念,数据真正是保存在物理磁盘上的。存储引擎负责的就是物理上数据的保存和提取。为了实现不同的功能,MySQL提供了各式各样的存储引擎,不同存储引擎在物理上的存储结构存在一些差异。但是不同的存储引擎提供了统一的调用接口(也就是存储引擎API)。
mysql支持多种存储引擎,可以通过如下命令查看:
show engines ;

虽然支持的存储引擎很多,但是我们需要重点关注InnoDB以及适当了解MyISAM存储引擎即可!
为了管理方便,人们把连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存储的功能划分为MySQL server的功能,把真实存取数据的功能划分为存储引擎的功能。
启动选项和系统变量
mysql程序(包括服务器相关程序和客户端相关程序)在启动的时候可以指定启动参数,来控制程序启动后的行为。这些启动参数可以放在命令行中指定,也可以把它们放在配置文件中指定。
在命令行上使用启动选项
启动mysql程序的命令行后边指定启动选项的通用格式如下:
--启动选项1[=值1] --启动选项2[=值2] ... --启动选项n[=值n]
各个启动选项之间使用空白字符隔开,在每一个启动选项名称前边添加--。对于不需要值的启动选项,比方说skip-networking,它们就不需要指定对应的值。对于需要指定值的启动选项,比如default-storage-engine我们在指定这个设置项的时候需要显式的指定它的值,比方说InnoDB、MyISAM。
mysqld --default-storage-engine=MyISAM --skip-networking
比如上面的启动项就表示默认存储引擎为MyISAM,并且禁止使用TCP/IP方式通信。
为了使用的方便,对于一些常用的选项提供了短形式,比如:
| 长形式 | 短形式 | 含义 |
|---|---|---|
| –host | -h | 主机名 |
| –user | -u | 用户名 |
| –password | -p | 密码 |
| –port | -P | 主机名 |
| –host | -h | 端口 |
配置文件中使用选项
相比于使用命令行的方式设置启动选项,mysql更推荐使用配置文件来设置启动选项。我们把需要设置的启动选项都写在这个配置文件中,每次启动服务器的时候都从这个文件里加载相应的启动选项。
MySQL程序在启动时会寻找多个路径下的配置文件,这些路径有的是固定的,有的是可以在命令行指定的。根据操作系统的不同,配置文件的路径也有所不同,并且越后面路径下的配置优先级越好。总之就是多个路径下都可以存在配置文件,并且有个优先级的关系。这里就不展开了。
配置文件的内容
与在命令行中指定启动选项不同的是,配置文件中的启动选项被划分为若干个组,每个组有一个组名,用中括号[]扩起来,像这样:
[server]
(具体的启动选项...)
[mysqld]
(具体的启动选项...)
[mysqld_safe]
(具体的启动选项...)
[client]
(具体的启动选项...)
[mysql]
(具体的启动选项...)
[mysqladmin]
(具体的启动选项...)
启动mysql程序时,会使用对应的一个或多个组下的启动选项。每个组下边可以定义若干个启动选项,我们以[server]组为例来看一下填写启动选项的形式(其他组中启动选项的形式是一样的):
[server]
option1 #这是option1,该选项不需要选项值
option2 = value2 #这是option2,该选项需要选项值
系统变量
mysql系统变量是指能够影响服务器程序运行行为的变量。比如允许同时连入的客户端数量由系统变量max_connections控制,表的默认存储引擎由系统变量default_storage_engine控制。每个系统变量都有一个默认值,我们可以使用命令行或者配置文件中的选项在启动服务器时改变一些系统变量的值,或者在运行时动态修改(大多数系统变量支持动态修改)。
作用范围
多个客户端程序可以同时连接到一个服务器程序。对于同一个系统变量,我们有时想让不同的客户端有不同的值,mysql通过系统变量的作用范围来解决上述问题。具体来说作用范围分为下面两种:
GLOBAL:全局变量,影响服务器的整体操作。SESSION:会话变量,影响某个客户端连接的操作。(注:SESSION有个别名叫LOCAL)
很显然,通过启动选项设置的系统变量的作用范围都是GLOBAL的,也就是对所有客户端都有效的。通过客户端动态修改系统变量语法如下:
SET [GLOBAL|SESSION] 系统变量名 = 值;
如果在设置系统变量的语句中省略了作用范围,默认的作用范围就是SESSION。同理,我们可以使用下列命令查看MySQL服务器程序支持的系统变量以及它们的当前值:
SHOW [GLOBAL|SESSION] VARIABLES [LIKE 匹配的模式];
状态变量
mysql状态变量是指描述服务器运行状态的变量,比方说Threads_connected表示当前有多少客户端与服务器建立了连接。
由于状态变量是用来显示服务器程序运行状况的,所以它们的值只能由服务器程序自己来设置(对客户端而言是只读的)。与系统变量类似,状态变量也有GLOBAL和SESSION两个作用范围的,所以查看状态变量的语句可以这么写:
SHOW [GLOBAL|SESSION] STATUS [LIKE 匹配的模式];
mysql支持的字符集和比较规则
在计算机中,数据最终都是以二进制的形式保存的。因此,如果我们要保存字符串,首先就先得确定字符串中的每个字符对应的二进制数据是什么,然后再将这些二进制数据保存到计算机中。将一个字符映射成一个二进制数据的过程也叫做编码,将一个二进制数据映射到一个字符的过程叫做解码。
使用字符集可以解决数据存储的问题,但是无法完全解决字符之间相互比较的问题。简单场景下,我们可以直接通过比较字符的二进制数据来判断大小,这种方式其实就是二进制比较规则。而有些场景下,二进制比较规则并不适用,比如忽略大小写的时候。因此为了应对不同的场景,同一种字符集可以有多种比较规则。
字符集
mysql中支持很多种字符集,可以通过以下语句查看:
SHOW CHARSET [LIKE 匹配的模式];
mysql> SHOW CHARSET;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
...
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
...
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.01 sec)
Charset: 字符集名称Description: 字符集描述Default collation: 默认的比较规则Maxlen: 一个字符最大占用的字节数。对于采用变长编码方式的字符集而言,一个字符占用的字节数不是固定的。比如在GB2312字符集中,一个字母只占用1个字节,而一个汉字占用了2个字节。
在mysql中,utf8和utf8mb4的区别就在于1个字符占用的最大字节数不同。utf8一个字符占用1-3个字节,而utf8mb4一个字符占用1-4个字节。实际上,mysql的utf8是utf8mb3的别名。如果需要保存一些占用4个字节的特殊字符(比如emoji表情),建议使用utf8mb4字符集。
比较规则
可以通过以下语句查看mysql中支持的比较规则:
SHOW COLLATION [LIKE 匹配的模式];
mysql> SHOW COLLATION LIKE 'utf8\_%';
+--------------------------+---------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+---------+-----+---------+----------+---------+
| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | | Yes | 1 |
...
+--------------------------+---------+-----+---------+----------+---------+
27 rows in set (0.00 sec)
Collation: 比较规则名称,基本符合字符集名称_语言_后缀模式。第一部分字符集名称就是与其关联的字符集的名称开头,第二部分表示该比较规则作用的语言,比如utf8_spanish_ci是以西班牙语的规则比较,utf8_general_ci是一种通用的比较规则。第三部分后缀主要用来表示要不要区分大小写和重音之类的。Charset: 关联的字符集的名称。Default: yes表示是字符集默认的比较规则。
| 后缀 | 英文释义 | 描述 |
|---|---|---|
| _ai | accent insensitive | 不区分重音 |
| _as | accent | sensitive |
| _ci | case insensitive | 不区分大小写 |
| _cs | case sensitive | 区分大小写 |
| _bin | binary | 以二进制方式比较 |
字符集和比较规则作用域级别
mysql中字符集和比较规则有4种作用域级别:
- 服务器级别
- 数据库级别
- 表级别
- 列级别
实际上,字符集和比较较规则最后肯定是作用在列级别字段上的。可以简单的认为,如果列级别没有指定字符集和比较较规则,就使用表级别的;如果表级别没有指定字符集和比较较规则,就使用数据库级别的;以此类推。
服务器级别
MySQL提供了两个系统变量来表示服务器级别的字符集和比较规则:
character_set_server: 服务器级别的字符集collation_server: 服务器级别的比较规则
服务器级别默认的字符集是utf8,默认的比较规则是utf8_general_ci。
数据库级别
我们在创建和修改数据库的时候可以指定该数据库的字符集和比较规则,具体语法如下:
CREATE DATABASE 数据库名
CHARACTER SET 字符集名称
COLLATE 比较规则名称;
ALTER DATABASE 数据库名
CHARACTER SET 字符集名称
COLLATE 比较规则名称;
比如:
mysql> CREATE DATABASE charset_demo_db
-> CHARACTER SET gb2312
-> COLLATE gb2312_chinese_ci;
Query OK, 1 row affected (0.01 sec)
如果想查看当前数据库使用的字符集和比较规则,可以查看下面两个系统变量的值:
character_set_database: 当前数据库的字符集collation_database: 当前数据库的比较规则
表级别
我们可以在创建和修改表的时候指定表的字符集和比较规则,语法如下:
CREATE TABLE 表名
(列的信息)
CHARACTER SET 字符集名称
COLLATE 比较规则名称
ALTER TABLE 表名
CHARACTER SET 字符集名称
COLLATE 比较规则名称
比如:
mysql> CREATE TABLE t(
-> col VARCHAR(10)
-> ) CHARACTER SET utf8 COLLATE utf8_general_ci;
Query OK, 0 rows affected (0.03 sec)
列级别
需要注意的是,对于存储字符串的列,同一个表中的不同的列也可以有不同的字符集和比较规则。我们在创建和修改列定义的时候可以指定该列的字符集和比较规则,语法如下:
CREATE TABLE 表名(
列名 字符串类型 CHARACTER SET 字符集名称 COLLATE 比较规则名称,
其他列...
);
ALTER TABLE 表名 MODIFY 列名 字符串类型 CHARACTER SET 字符集名称 COLLATE 比较规则名称;
比如我们修改一下表t中列col的字符集和比较规则可以这么写:
mysql> ALTER TABLE t MODIFY col VARCHAR(10) CHARACTER SET gbk COLLATE gbk_chinese_ci;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
还需要注意的一点是:由于字符集和比较规则是相互联系的,如果我们只修改了字符集和比较规则,都可能引起关联的字符集和比较规则发生变化。