1 绪论
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等学科。专门研究计算机如何模拟或者实现人类的学习行为,来获取新的知识或技能,并重组已有的知识结构使之不断改善自身的性能。他是人工智能核心,是使计算机具有智能的根本途径。
深度学习(DL,Deep Learning)是机器学习(ML,Machine Learning)领域中一个新的研究方向,他被引入机器学习使其更接近于最初的目标——人工智能(AL,Aritifical Intelligence)。
2 深度学习的发展
1943年由神经科学家麦卡洛克和数学家皮兹建立了神经网络和其数学模型,称为MCP模型,是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型:输入信号线性加权、求和然后非线性激活,也就诞生了“模拟大脑”,人工神经网络的大门由此开启。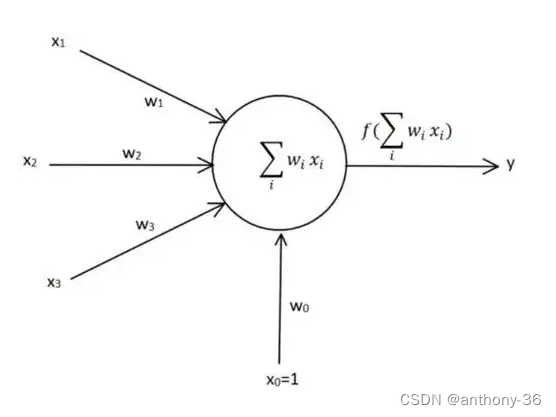
感知机 1958年计算机科学家罗森·布拉特提出两层神经元组成的神经网络,称之为感知机。第一次将MCP用于机器学习分类。感知机算法(PLA)使用MCP模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962年,该方法被证明为能够收敛,理论与实践效果引起了第一次神经网络的浪潮。 1969年,美国数学家及人工智能先驱马文·明斯基证明感知机本质是一种线性模型,只能处理线性分类问题,XOR问题无法正确分类,神经网络的研究随后陷入了将近20年的停滞。 1986年神经网络之父杰弗里·辛顿发明了适用于多层感知机(MLP)BP算法,并用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题,该方法引起了神经网络的第二次热潮。 1989年,立昆发明了卷积神经网络-LeNet,并将其用于数字识别,取得了较好成绩,但是当时没引起注意。同时神经网络有人提出通用逼近定理,一个包含有足够但但有限数量的神经元隐藏层,可以在激活函数的某些条件下可以逼近任何连续函数,为什么要深度呢?(One layer is good.Why deep?)神经网络陷入了第二次停滞, 1991年,BP算法被指出存在梯度消失问题,也就是说在误差梯度后项传递的过程中,后层梯度以乘性的方式叠加到前层,由于Sigmoid函数的饱和特性,后层梯度本来就小,误差梯度传到前层时几乎为0,因此无法对前层进行有效的学习,该问题直接阻碍了深度学习的进一步发展。
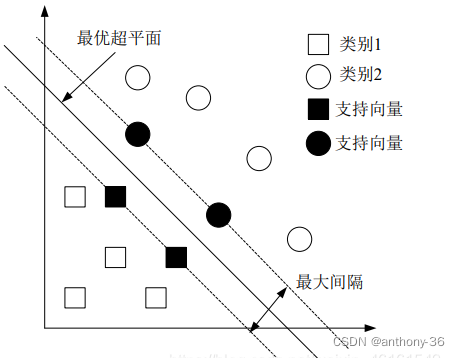
支持向量机
90年代中期,支持向量机算法(SVM算法)、ada Boost等各种浅层机器学习模型被提出,SVM也是一种有监督的学习模型,应用于模式识别,分类以及回归分类等。它的提出再次阻碍了深度学习的发展。
1997年,LSTM模型被发明,但是没有引起足够的重视。
2006年,加拿大多伦多教授、机器学习领域泰斗、神经网络之父杰弗里·辛顿和他的学生罗斯兰·萨拉赫丁诺夫提出了深层网络训练中梯度消失问题的解决方案:无监督预训练对权值进行初始化+有监督训练微调,这也是首次提出了深度学习的概念。2011年,ReLU激活函数被提出,该激活函数能够有效的抑制梯度消失问题。
2011年以来,微软首次将深度学习应用在语音识别上,取得了重大突破。微软研究院和谷歌的语音识别研究人员先后采用DNN技术降低语音识别错误率20%~30%,是语音识别领域十多年来最大的突破性进展。
2012年,DNN技术在图像识别领域取得惊人的效果,在ImageNet评测上将错误率从26%降低到15%。在这一年,DNN还被应用于制药公司的DrugeActivity预测问题,并获得世界最好成绩。
2012-2017年,杰弗里·辛顿为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得了冠军。
2016年3月,由谷歌(Google)旗下DeepMind公司开发的AlphaGo(基于深度学习)与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜;
2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册帐号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩;2017年5月,在中国乌镇围棋峰会上,它与排名世界第一的世界围棋冠军柯洁对战,以3比0的总比分获胜。围棋界公认阿尔法围棋的棋力已经超过人类职业围棋顶尖水平。
近些年随着数据量的增加、分布式计算的发展以及硬件比如说GPU的更新换代,深度学习的应用日渐火热,其影响力不断扩大。
3 深度学习原理探究
神经网络算法可以说是当下使用最广泛的算法,其中误差反向传播算法是神经网络中最有代表性的算法,也是迄今为止使用最多、最成功的算法。相比于数学微分计算神经网络权重的梯度,误差反向传播算法能够高效计算权重参数的梯度。但是在图像识别和语音识别等场合,深度学习的方法几乎都以卷积神经网络为基础,相比于全连接层将全部的输入数据作为相同的神经元(同一维度的神经元)处理,卷积层能够以三维数据的形式接收输入数据,并且同样以三维数据的形式输出至下一层,可以利用与形状相关的信息。
3.1 BP神经网络原理
BP算法由信号的正向传播和误差的反向传播两个过程组成。
正向传播时,输入样本从输入层进入网络,经隐含层逐层传递至输出层,如果输出层的实际输出与期望输出不同,则转至误差反向传播;如果输出层的实际输出与期望输出相同,结束学习算法。
反向传播时,将输出误差(期望输出与实际输出之差)按原通路反传计算,通过隐含层反向,直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将其作为修正各个单元权值的依据,这一计算过程使用梯度下降法完成,在不停的调整各层神经元的权重和偏置后,使误差信号减小到允许的过程。
3.2 卷积神经网络
3.2.1 卷积神经网络原理
目前卷积神经网络(Convolutional Netural Network,CNN或ConvNet)一般是由卷积层、汇聚层和全连接层交叉堆叠而成的前馈神经网络,卷积神经网络有三个结构上的特性:局部连接、权重共享以及汇聚。
一个完整的卷积神经网络基本上由输入层、卷积层、池化层(汇聚层)、全连接层和SoftMax层这五种结构组成。
输入层是整个卷积神经网络的输入,一般代表一张图片的像素矩阵。
卷积层是整个神经网络的核心,一般将前一层的神经网络上的矩阵卷积转化为下一层神经网络的矩阵,并增加节点矩阵的深度,他的作用是提取一个局部区域的特征以达到更深层次抽象特征表达的目的,不同的卷积核相当于不同的特征提取器。
池化层的作用是进行特征选择,降低特征数量,从而减少参数数量。卷积层虽然可以显著减少网络中连接的数量,但是卷积后神经元个数并没有减少,如果后面接一个分类器,分类器的输入维数依然很高,很容易出现拟合,为了解决这个问题,可以在卷积层后加上一个池化层,从而降低特征维数,避免过拟合。池化函数一般有两种:最大池化采样和平均池化采样。
全连接层一般位于多次卷积池化处理后,用以给出最后的分类结果。
SoftMax层就是分类器,用以分类,能得到结果的概率分布。
卷积神经网络中,参数为卷积核中权重以及偏置,和全连接前馈神经网络类似,卷积网络也可以通过误差反向传播算法来进行参数学习。
3.2.2 典型卷积神经网络
LeNet-5和AlexNet是广泛使用的典型深层卷积神经网络。
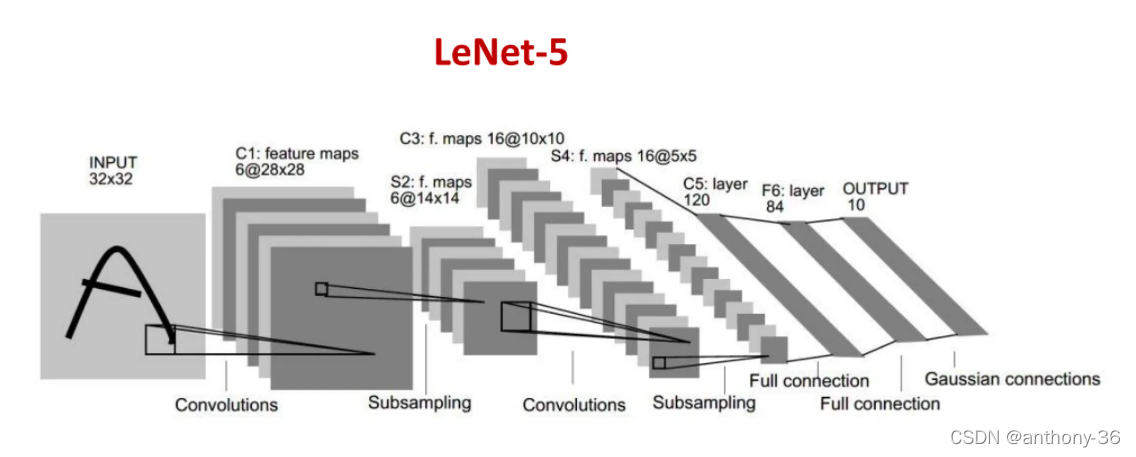
LeNet-5结构 LeNet-5如果不加输入层为七层卷积神经网络,接收输入图像的大小为32*32=1024,输出对应10个类别的得分。其结构如下: ①第一层输入层之后的第二层为卷积层C1,使用6个5*5的卷积核,得到6个28*28=784的特征图。所以C1层神经元数目为6*784=4704,可训练参数数量为6*25+6=156。 ②第三层为池化层S2,采样窗口为2*2,使用平均汇聚,并使用一个非线性函数,所以S2层神经元数目为6*14*14=1176,可训练参数为6*(1+1)=12。 ③第四层为卷积层C3,应该使用96个5*5的卷积核,得到16组大小为10*10的特征图,但是LeNet-5中使用了一个连接表来定义输入和输出之间的关系,最后使用了60个5*5的卷积核就达到了目的。所以C3层神经元数量为16*100=1600,可训练参数为(60*25)+16=1516。 ④第五层为池化层S4,采样窗口为2*2,得到26个5*5大小的特征图,S4层可训练参数数量为16*2=32。 ⑤第六层为卷积层C5,使用120*16=1920个5*5的卷积核,得到120组大小为1*1的特征图,C5层神经元数量为120,可训练参数数量为1920*25+120=48120。 ⑥第七层为全连接层,有84个神经元,可训练数量为84*(120+1)=10164。 ⑦第八层为输出层。
AlexNet是第一个现代深度卷积网络模型,其首次使用很多现代深度卷积网络的技术方法:①利用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算;②采用ReLU作为非线性激活函数,其效果超过Sigmoid,解决了梯度消失问题;③使用Dropout随机忽略一部分神经元,防止过拟合;④使用最大池化采样,此前普遍使用平均池化采样;⑤使用数据增强来提高模型准确率。模型包括五个卷积层、三个池化层和三个全连接层,输入为2242243的图像,输出为1000个类别的条件概率。

AlexNet结构
①第一层输入层之后的第二层为卷积层,使用两个大小为1111348的卷积核,实际上是96个1111的卷积核,步长为4,零填充为3,得到两个大小为555548的特征图,可训练参数数量为96*(11113+1)=34994.
②第三层为池化层,使用大小为33的最大池化采样操作,步长为2,得到两个272748的特征图。
③第四层为卷积层,使用两个大小为5548128的卷积核,也就是256个大小为55的卷积核,步长为1,零填充为2,得到两个大小为2727128的特征图,可训练参数数量为256(5596+1)=614656.
④第五层为池化层,使用大小为33的最大池化操作,步长为2,得到大小为1313128的特征图。
⑤第六层为卷积层并且将两个路径融合,使用大小为33256384的卷积核,步长为1,零填充为1,得到两个大小为1313192的特征图,可训练参数数量为384*(33256+1)=885120。
⑥第七层为卷积层,使用两个大小为33192192的卷积核,步长为1,零填充为1,得到两个大小为1313192的特征图,可训练参数数量为384(33394+1)=1327488。
⑦第八层为卷积层,使用两个33192128的卷积核,步长为1,零填充为1,得到两个为1313128的特征图,可训练参数数量为256(33394+1)=884992。
第九层为池化层,使用大小为33的最大池化操作,步长为2,得到两个大小为66*128的特征图。
⑧后面的三层全连接层神经元数量分别是:4096、4096和1000,可训练参数数量分别为:37752832、16781312和4100096。
AlexNet网络参数总共为62381490!
深度学习本质上是层次特征提取学习的过程,他通过构建多层隐含神经网络模型,利用海量数据训练出模型特征来提取最有利的参数,将简单的特征组合抽象成高层次的特征,以实现对数据或实际对象的抽象表达。
4 深度学习技术的应用及其影响
深度学习在医疗领域最激动人心的应用,无疑是在医学诊断方面的应用。谷歌的DeepMind和IBM的watson,都在这方面积极布局,尤其是watson,在某些特定领域,其诊断精度已经超过了人类专家。由于医疗中病例大多数为非结构化文本数据,因此采用多层限制性波尔兹曼机(RBM)堆叠成的深度信念网络(DBN),可以自动提取文本病例中的特征,可以有效的学习病历中的知识,同时可以高效地进行诊断。CNN 可以在多种医疗影像上训练,包括放射科、病理科、皮肤科和眼科。信息从左到右传播。输入图像馈入 CNN 后,网络会使用卷积、池化、全连接层等简单操作按顺序将数据转换成扁平向量。输出向量的元素表示疾病出现的概率。在训练过程中,网络层的内部参数会迭代调整,以提高准确率。
无人驾驶也称为无人车、自动驾驶汽车,是指车辆能够依据自身对周围环境条件的感知、理解,自行进行运动控制,且能达到人类驾驶员驾驶水平。深度学习技术带来的高准确性促进了无人驾驶车辆系统在目标检测、决策、传感器应用等多个核心领域的发展。如卷积神经网络,目前广泛应用于各类图像处理中,非常适用于无人驾驶领域。其训练测试样本是从廉价的摄像头中获取的,这种使用摄像机取代雷达从而压缩成本的方法广受关注。CNN是可以理解图片中结构关系的神经网络,可以精确识别图像中的行人、车辆、路牌等等,同时还需要有实时性,RCNN以及后续的Fast-RCNN以及Faster-RCNN逐步做到了能够实时给出图像中物体位置。更进一步,有人开始使用CNN来分割图像,试图估测出每个部分与摄像头的距离。
语音识别指的是将语音信号转化为文字序列,它是所有基于语音交互的基础。对于语音识别而言,高斯混合模型(GMM)和马尔科夫模型(HMM)曾占据了几十年的发展历史。这些模型有很多优点,最重要的就是他们可以用数学来描述,研究人员可以合理地推导出适用某个方向的可行性办法。在1990年前后,判别模型获得了比基于最大似然估计的方法(GMM)更好的性能。尤其在2012年以后,深度学习在语音识别领域获得了很大的发展,CNN,RNN,CRNN等结构在语音识别性能上取得了一次又一次的突破。随着研究的深入和硬件设备的不断更新,一些端到端模型取得了最先进的性能,比较有代表性的是之前提到的sequence-to-sequence模型(CTC,LAS)。随着语音识别性能的不断提升,工业界也产出了很多应用成果,比如虚拟助手:Google Home, Amazon Alexa and Microsoft Cortana;语音转录:YouTube的字幕生成等。
5 结语
近年来,基于深度学习模型的算法已逐步改变人类处理现实问题的方式,深度学习在社会和生活等各个领域的应用呈现高速增长的趋势。由于深度学习领域的研究,深度学习模型成功地应用于各种实际应用场景中,如医疗,自动驾驶,图像处理分类和检测,语音和音频处理,网络安全。
随着各大研究机构和科技巨头相继对深度学习领域投入了大量的资金和精力,并取得了惊人的成就,但是我们不能忽略的一个重要问题是,深度学习还有着局限性:
深度学习的不可解释性;深度学习学到的是输入与输出特征之间的复杂关系,而不是因果关系的表征,训练神经网络获得的参数与实际任务之间的关联性非常模糊。这是一个黑盒模型,要使他们具有说服力,首先要解决的问题是使他们具有可解释性。虽然关于可解释的人工智能领域的研究应运而生,但是后面仍有很长的路要走。
深度学习需要大量数据;深度学习的性能的提升取决于数据集的大小,因此深度学习通常需要大量的数据作为支撑,如果不能进行大量有效的训练,往往会导致过拟合现象的产生。
综上所述尽管人类在深度学习领域取得了不小的成就但是距离人类级别的人工智能仍有着很大距离。目前为了解决深度学习面临的挑战,人们已经采取了多项举措来解决问题。所以对于深度学习的发展,我们也不要过于悲观。